Adaptive Distraction: Probing LLM Contextual Robustness with Automated Tree Search
作者: Yanbo Wang, Zixiang Xu, Yue Huang, Chujie Gao, Siyuan Wu, Jiayi Ye, Pin-Yu Chen, Xiuying Chen, Xiangliang Zhang
分类: cs.CL
发布日期: 2025-02-03 (更新: 2025-09-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于树搜索的自适应干扰生成框架,提升LLM上下文鲁棒性压力测试效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文鲁棒性 自适应干扰 树搜索 压力测试
📋 核心要点
- 现有方法使用固定模板或检索式干扰,对LLM上下文鲁棒性的测试效果有限,难以有效评估模型。
- 提出基于树搜索的动态干扰生成框架,通过模型行为引导生成过程,高效生成更具挑战性的自适应干扰。
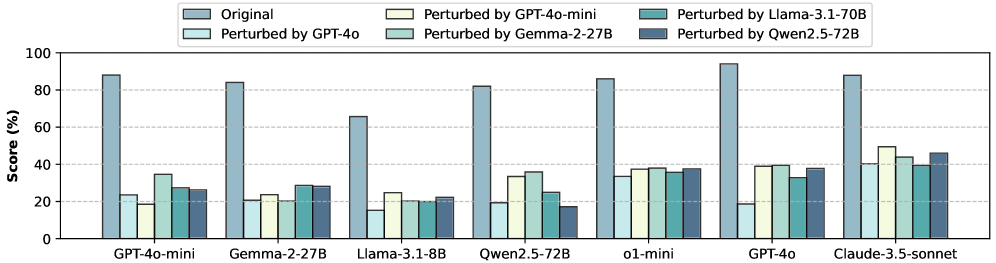
- 实验表明,该方法生成的干扰使主流模型性能平均下降超过45%,凸显了LLM在上下文干扰下的推理缺陷。
📝 摘要(中文)
大型语言模型(LLMs)在面对语义连贯但与任务无关的上下文信息时,常常难以维持其原始性能。为了解决这个问题,我们提出了一种基于树搜索的动态干扰生成框架,该生成过程由模型行为引导。该方法无需修改原始问题或答案,即可在多个数据集上高效地生成具有挑战性的自适应干扰,从而对LLMs的上下文鲁棒性进行系统性的压力测试。在四个基准测试上的实验表明,生成的干扰导致主流模型的性能平均下降超过45%。进一步的缓解策略比较表明,基于提示的优化方法收益有限,而事后训练方法(例如,DPO)显著增强了模型的上下文鲁棒性。结果表明,这些问题并非源于LLMs的知识缺陷,而是源于在上下文干扰下无法保持一致推理的根本缺陷,这对LLMs在实际应用中的可靠性提出了重大挑战。代码已公开。
🔬 方法详解
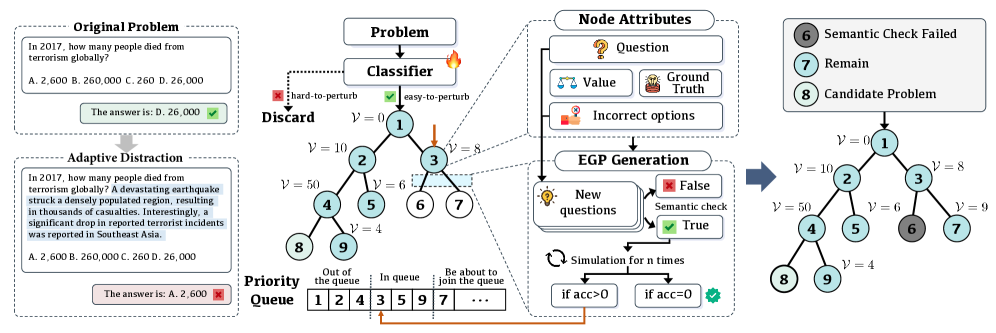
问题定义:论文旨在解决大型语言模型(LLMs)在面对语义相关但任务无关的上下文信息时,性能显著下降的问题。现有方法,如固定模板或检索式干扰,无法有效评估和挑战现代LLMs的上下文鲁棒性,因为它们生成的干扰不够动态和自适应。
核心思路:论文的核心思路是利用树搜索算法,动态地生成与模型行为相适应的干扰信息。通过迭代地探索和评估不同干扰对模型性能的影响,逐步生成更具挑战性的干扰样本,从而更有效地暴露LLMs在上下文推理方面的弱点。这种自适应的干扰生成方式能够克服传统静态方法的局限性。
技术框架:该框架主要包含以下几个阶段:1) 初始化:使用原始问题和答案作为初始状态。2) 干扰生成:利用语言模型生成候选干扰信息。3) 模型评估:将生成的干扰信息添加到上下文中,并评估LLM在修改后的上下文中的表现。4) 树搜索:使用树搜索算法(如蒙特卡洛树搜索)来探索不同的干扰组合,并根据模型评估结果选择最优的干扰路径。5) 迭代优化:重复干扰生成、模型评估和树搜索过程,直到达到预定的停止条件。
关键创新:最重要的技术创新点在于动态的、自适应的干扰生成机制。与传统的静态干扰方法不同,该方法能够根据LLM的实际表现,针对性地生成更具挑战性的干扰信息。这种自适应性使得该方法能够更有效地暴露LLMs在上下文推理方面的弱点,并为LLM的鲁棒性评估提供更准确的依据。
关键设计:树搜索算法是该框架的关键。具体而言,论文可能采用了蒙特卡洛树搜索(MCTS)或其他变体。在MCTS中,每个节点代表一个上下文状态(包含原始问题、答案和已生成的干扰信息),边代表添加新的干扰信息。搜索过程通过模拟(rollout)和反向传播(backpropagation)来评估每个节点和边的价值,从而指导搜索方向。奖励函数的设计至关重要,它通常基于LLM在添加干扰后的性能下降程度。此外,干扰生成器的设计也需要考虑,可以使用预训练的语言模型来生成语义连贯但与任务无关的干扰信息。
🖼️ 关键图片
📊 实验亮点
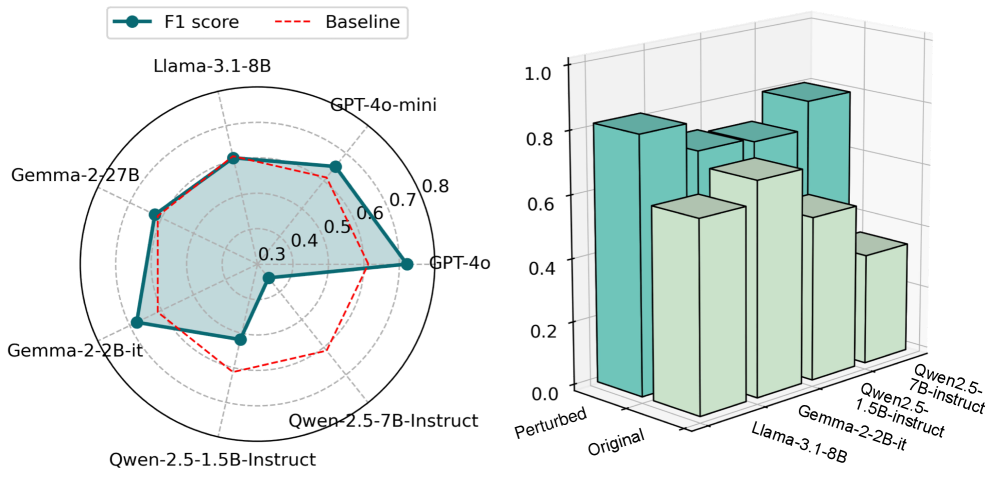
实验结果表明,该方法生成的自适应干扰能够导致主流LLM(如GPT-3.5、LLaMA2等)的性能平均下降超过45%。对比prompt优化等缓解策略,发现其效果有限,而采用DPO等事后训练方法能够显著提升LLM的上下文鲁棒性。这些结果表明,LLM的上下文推理能力仍有较大提升空间。
🎯 应用场景
该研究成果可应用于LLM的安全性评估、鲁棒性测试和对抗训练。通过生成自适应干扰,可以更有效地发现LLM在复杂上下文环境下的潜在缺陷,从而提升LLM在实际应用中的可靠性和安全性。此外,该方法还可以用于开发更有效的对抗训练策略,提高LLM的抗干扰能力。
📄 摘要(原文)
Large Language Models (LLMs) often struggle to maintain their original performance when faced with semantically coherent but task-irrelevant contextual information. Although prior studies have explored this issue using fixed-template or retrieval-based distractions, such static methods show limited effectiveness against contemporary models. To address this problem, we propose a dynamic distraction generation framework based on tree search, where the generation process is guided by model behavior. Without modifying the original question or answer, the method efficiently produces challenging adaptive distractions across multiple datasets, enabling systematic stress testing of LLMs' contextual robustness. Experiments on four benchmarks demonstrate that the generated distractions lead to an average performance drop of over 45\% for mainstream models. Further comparisons of mitigation strategies show that prompt-based optimization methods yield limited gains, whereas post-training approaches (e.g., DPO) significantly enhance the model's contextual robustness. The results indicate that these issues do not stem from knowledge deficits in LLMs, but from a fundamental inability to maintain consistent reasoning under contextual distraction, posing a major challenge to the reliability of LLMs in real-world applications. The code is publicly available at https://github.com/wyf23187/Adaptive_Distractions.