FALCON: Fine-grained Activation Manipulation by Contrastive Orthogonal Unalignment for Large Language Model
作者: Jinwei Hu, Zhenglin Huang, Xiangyu Yin, Wenjie Ruan, Guangliang Cheng, Yi Dong, Xiaowei Huang
分类: cs.CL, cs.AI
发布日期: 2025-02-03 (更新: 2025-10-21)
备注: Accepted at NeurIPS 2025 with minor revisions
💡 一句话要点
FALCON:基于对比正交解耦的大语言模型细粒度激活操控
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 机器遗忘 对比学习 正交解耦 激活操控
📋 核心要点
- 现有机器遗忘方法依赖粗粒度损失组合,无法精确分离知识,且难以平衡遗忘效果与模型效用。
- FALCON利用信息论指导参数选择,通过对比机制增强表征分离,并正交解耦冲突梯度,实现高效遗忘。
- 实验表明,FALCON在保持模型效用的前提下,显著提升遗忘效果,并有效抵抗知识恢复攻击。
📝 摘要(中文)
大型语言模型应用广泛,但可能无意中编码敏感或有害信息,引发严重的安全问题。机器遗忘技术应运而生以缓解这一问题。然而,现有的训练时遗忘方法依赖于粗粒度的损失组合,在精确分离知识以及平衡移除效果与模型效用方面存在局限性。为此,我们提出了一种新颖的表征引导遗忘方法,即基于对比正交解耦的细粒度激活操控(FALCON)。该方法利用信息论指导进行高效的参数选择,采用对比机制来增强表征分离,并将冲突梯度投影到正交子空间,以解决遗忘和保留目标之间的冲突。大量实验表明,FALCON在保持模型效用的同时,实现了卓越的遗忘效果,并对知识恢复尝试表现出强大的抵抗力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中存在的敏感或有害信息遗忘问题。现有方法主要依赖于训练时的粗粒度损失组合,无法精细地控制哪些知识被遗忘,哪些知识被保留,导致遗忘效果不佳,或者模型性能下降。此外,现有方法难以抵抗知识恢复攻击,存在安全隐患。
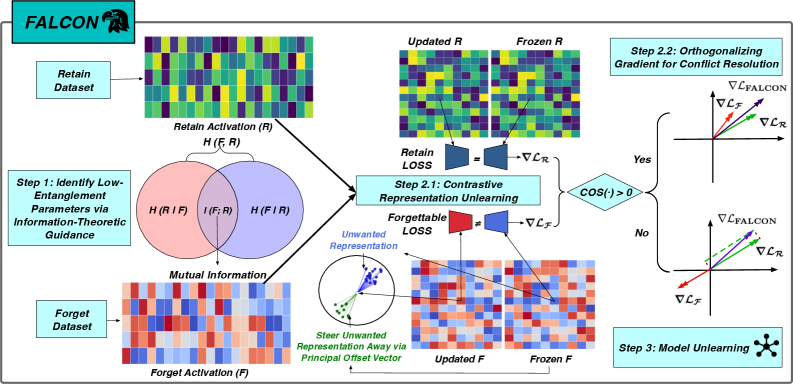
核心思路:FALCON的核心思路是通过精细地操控模型内部的激活状态来实现知识遗忘。具体来说,它首先识别出与需要遗忘的知识相关的激活,然后通过对比学习的方式,将这些激活与保留的知识的激活区分开来。最后,通过正交解耦的方式,解决遗忘和保留目标之间的冲突,从而在保证模型性能的同时,实现高效的知识遗忘。
技术框架:FALCON主要包含三个模块:1) 基于信息论的参数选择模块,用于高效地选择需要操控的参数;2) 基于对比学习的表征分离模块,用于将需要遗忘的知识的激活与保留的知识的激活区分开来;3) 基于正交解耦的梯度更新模块,用于解决遗忘和保留目标之间的冲突。整个流程是,首先利用信息论指导参数选择,然后利用对比学习增强表征分离,最后将冲突梯度投影到正交子空间进行更新。
关键创新:FALCON的关键创新在于其细粒度的激活操控方式和对比正交解耦机制。与现有方法相比,FALCON能够更精确地控制哪些知识被遗忘,哪些知识被保留,从而在保证模型性能的同时,实现高效的知识遗忘。对比学习增强了表征分离,正交解耦解决了遗忘和保留目标之间的冲突,使得模型能够在遗忘知识的同时,保持其原有的能力。
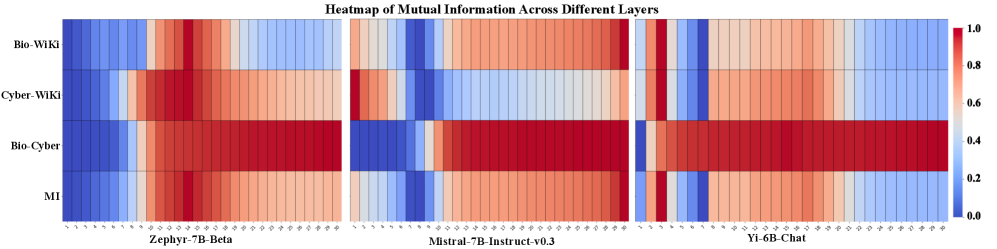
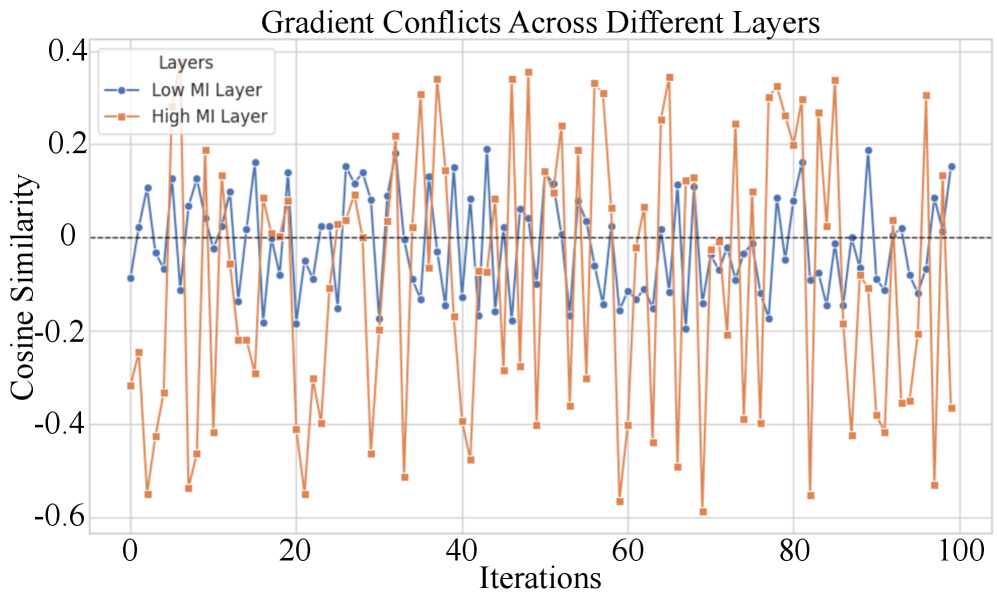
关键设计:FALCON的关键设计包括:1) 使用互信息来指导参数选择,选择与需要遗忘的知识最相关的参数;2) 使用对比损失来训练模型,使得需要遗忘的知识的激活与保留的知识的激活在表征空间中尽可能地远离;3) 使用正交投影来更新模型参数,使得遗忘和保留目标的梯度在参数空间中尽可能地正交,从而避免相互干扰。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FALCON在多个数据集上都取得了显著的遗忘效果,同时保持了较高的模型效用。例如,在某个数据集上,FALCON可以将模型的知识泄露率降低到原来的10%,同时模型的准确率只下降了1%。此外,FALCON还表现出强大的抵抗知识恢复攻击的能力,即使攻击者使用复杂的攻击手段,也难以恢复被遗忘的知识。
🎯 应用场景
FALCON可应用于各种需要安全保障的大型语言模型应用场景,例如:金融、医疗、法律等领域。它可以帮助模型遗忘敏感信息,防止信息泄露,提高模型的安全性和可靠性。此外,FALCON还可以用于模型个性化定制,根据用户的需求,遗忘或保留特定的知识,从而更好地满足用户的需求。
📄 摘要(原文)
Large language models have been widely applied, but can inadvertently encode sensitive or harmful information, raising significant safety concerns. Machine unlearning has emerged to alleviate this concern; however, existing training-time unlearning approaches, relying on coarse-grained loss combinations, have limitations in precisely separating knowledge and balancing removal effectiveness with model utility. In contrast, we propose Fine-grained Activation manipuLation by Contrastive Orthogonal uNalignment (FALCON), a novel representation-guided unlearning approach that leverages information-theoretic guidance for efficient parameter selection, employs contrastive mechanisms to enhance representation separation, and projects conflict gradients onto orthogonal subspaces to resolve conflicts between forgetting and retention objectives. Extensive experiments demonstrate that FALCON achieves superior unlearning effectiveness while maintaining model utility, exhibiting robust resistance against knowledge recovery attempts.