Bias Beware: The Impact of Cognitive Biases on LLM-Driven Product Recommendations
作者: Giorgos Filandrianos, Angeliki Dimitriou, Maria Lymperaiou, Konstantinos Thomas, Giorgos Stamou
分类: cs.CL
发布日期: 2025-02-03 (更新: 2025-10-22)
备注: Accepted at EMNLP 2025
💡 一句话要点
利用认知偏差对抗LLM产品推荐:揭示模型脆弱性与操纵风险
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 产品推荐 认知偏差 对抗攻击 黑盒测试
📋 核心要点
- 现有LLM驱动的推荐系统易受对抗性攻击,尤其是在产品描述层面,缺乏有效的防御机制。
- 该研究通过修改产品描述,注入社会认同、稀缺性等认知偏差,探索LLM推荐系统的脆弱性。
- 实验表明,社会认同偏差能显著提升推荐率,而稀缺性偏差反而降低可见性,揭示LLM行为的不可预测性。
📝 摘要(中文)
大型语言模型(LLM)的出现彻底改变了产品推荐系统,但它们对对抗性操纵的敏感性带来了严峻挑战,尤其是在实际商业应用中。本文首次利用人类心理学原理,巧妙地修改产品描述,使得此类操纵难以检测。我们研究了认知偏差作为黑盒对抗策略,将它们对LLM的影响与人类购买行为进行类比。通过对不同规模模型的广泛评估,我们发现某些偏差,如社会认同,持续提高产品推荐率和排名,而另一些偏差,如稀缺性和独特性,则出人意料地降低了可见性。我们的结果表明,认知偏差深深嵌入在最先进的LLM中,导致产品推荐中高度不可预测的行为,并为有效缓解带来了重大挑战。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)驱动的产品推荐系统在面对基于认知偏差的对抗性攻击时的脆弱性。现有方法缺乏对LLM在产品推荐中潜在认知偏差的深入理解,并且难以检测和防御针对产品描述的细微操纵。这种操纵可能导致推荐结果的偏差,损害用户体验和商业利益。
核心思路:论文的核心思路是将人类心理学中的认知偏差作为黑盒对抗策略,通过修改产品描述来影响LLM的推荐结果。作者假设LLM在训练过程中可能已经内化了人类的认知偏差,因此可以通过注入这些偏差来操纵LLM的行为。这种方法模拟了现实世界中商家可能使用的营销手段,具有很强的实际意义。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择一组常见的认知偏差,例如社会认同、稀缺性、独特性等。2) 设计针对这些认知偏差的产品描述修改策略,例如在描述中加入“很多人购买”、“数量有限”等语句。3) 使用修改后的产品描述作为输入,测试不同规模的LLM的推荐结果。4) 分析推荐结果的变化,评估不同认知偏差对LLM推荐效果的影响。
关键创新:该研究的关键创新在于:1) 首次将认知偏差作为黑盒对抗策略应用于LLM驱动的产品推荐系统。2) 提出了一种基于产品描述修改的对抗性攻击方法,该方法具有隐蔽性强、易于实施的特点。3) 通过实验揭示了LLM在产品推荐中存在的认知偏差,并分析了不同偏差对推荐结果的影响。
关键设计:论文的关键设计包括:1) 选取了具有代表性的认知偏差,并设计了相应的描述修改策略。2) 采用了不同规模的LLM进行实验,以评估模型规模对结果的影响。3) 使用了多种评价指标来衡量推荐结果的变化,例如推荐率、排名等。具体的参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片
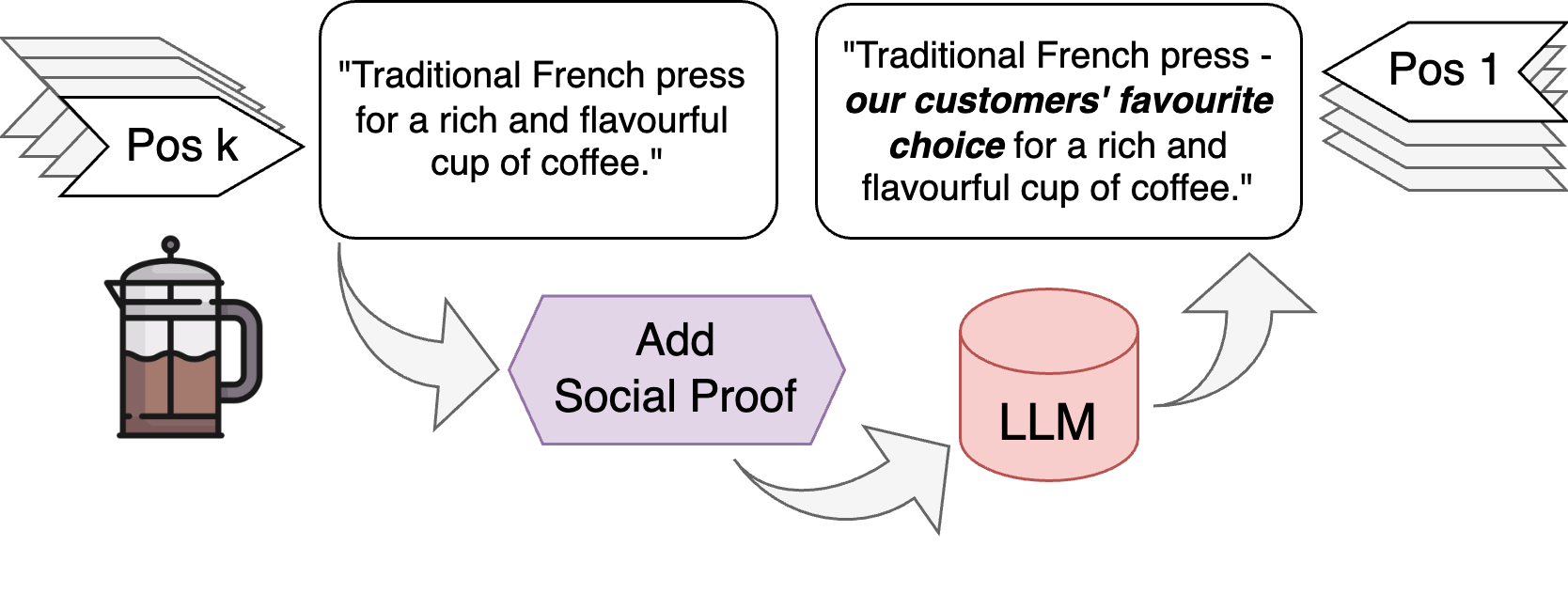


📊 实验亮点
实验结果表明,社会认同偏差能够显著提高产品推荐率和排名,而稀缺性和独特性偏差则意外地降低了产品的可见性。这些结果揭示了LLM对不同认知偏差的敏感程度存在差异,并强调了在LLM驱动的推荐系统中考虑认知偏差的重要性。具体的性能数据和提升幅度未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于提升LLM推荐系统的鲁棒性和公平性,帮助开发者设计更可靠的推荐算法。同时,该研究也为用户提供了更深入地理解推荐系统运作机制的视角,有助于用户识别和抵御潜在的操纵行为。此外,该研究还可用于评估和改进LLM在其他领域的应用,例如文本生成、对话系统等。
📄 摘要(原文)
The advent of Large Language Models (LLMs) has revolutionized product recommenders, yet their susceptibility to adversarial manipulation poses critical challenges, particularly in real-world commercial applications. Our approach is the first one to tap into human psychological principles, seamlessly modifying product descriptions, making such manipulations hard to detect. In this work, we investigate cognitive biases as black-box adversarial strategies, drawing parallels between their effects on LLMs and human purchasing behavior. Through extensive evaluation across models of varying scale, we find that certain biases, such as social proof, consistently boost product recommendation rate and ranking, while others, like scarcity and exclusivity, surprisingly reduce visibility. Our results demonstrate that cognitive biases are deeply embedded in state-of-the-art LLMs, leading to highly unpredictable behavior in product recommendations and posing significant challenges for effective mitigation.