AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Document Understanding
作者: Ahmed Masry, Juan A. Rodriguez, Tianyu Zhang, Suyuchen Wang, Chao Wang, Aarash Feizi, Akshay Kalkunte Suresh, Abhay Puri, Xiangru Jian, Pierre-André Noël, Sathwik Tejaswi Madhusudhan, Marco Pedersoli, Bang Liu, Nicolas Chapados, Yoshua Bengio, Enamul Hoque, Christopher Pal, Issam H. Laradji, David Vazquez, Perouz Taslakian, Spandana Gella, Sai Rajeswar
分类: cs.CL
发布日期: 2025-02-03 (更新: 2025-11-02)
💡 一句话要点
AlignVLM:通过对齐视觉和语言隐空间,提升多模态文档理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态文档理解 视觉文本对齐 语言先验知识 低资源学习
📋 核心要点
- 现有视觉-语言模型依赖MLP等连接器对齐视觉和语言特征,但缺乏语言结构的归纳偏置,导致数据需求高且易错位。
- AlignVLM将视觉特征映射到LLM文本嵌入的加权平均,利用LLM的语言先验知识,确保视觉特征映射到LLM可解释的空间。
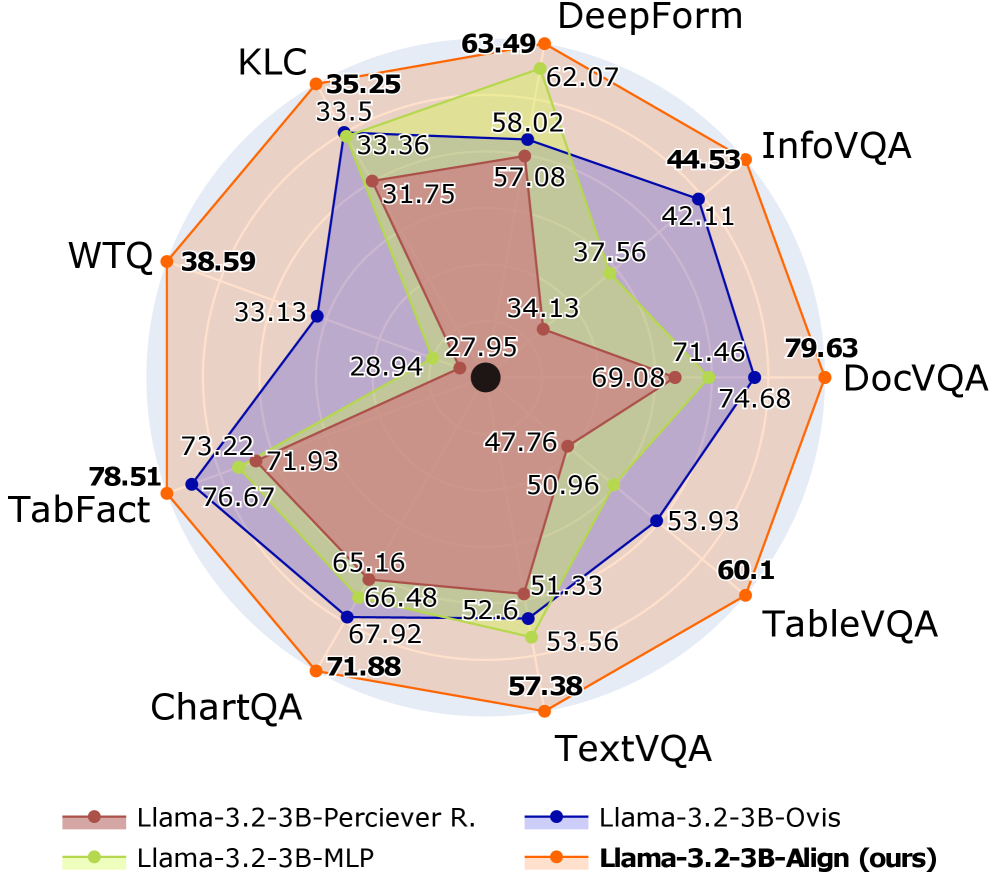
- 实验表明,AlignVLM在文档理解任务上取得了SOTA性能,尤其在低资源场景下提升显著,并展现出良好的效率和鲁棒性。
📝 摘要(中文)
在视觉-语言模型(VLM)中,对齐视觉特征与语言嵌入是一个关键挑战。此类模型的性能取决于是否存在一个良好的连接器,该连接器能够将视觉编码器生成的视觉特征映射到与LLM共享的嵌入空间,同时保持语义相似性。现有的连接器,如多层感知机(MLP),缺乏归纳偏置,无法将视觉特征约束在LLM嵌入空间的语言结构中,导致它们对数据需求高且容易出现跨模态错位。本文提出了一种新的视觉-文本对齐方法AlignVLM,该方法将视觉特征映射到LLM文本嵌入的加权平均值。我们的方法利用LLM编码的语言先验知识,确保视觉特征被映射到LLM能够有效解释的空间区域。AlignVLM在文档理解任务中尤其有效,因为在这些任务中,视觉和文本模态高度相关。大量的实验表明,与之前的对齐方法相比,AlignVLM实现了最先进的性能,在文档理解任务和低资源设置下获得了更大的收益。我们进一步的分析证明了其效率和对噪声的鲁棒性。
🔬 方法详解
问题定义:现有的视觉-语言模型在对齐视觉特征和语言嵌入时,通常使用多层感知机(MLP)等连接器。这些连接器缺乏足够的归纳偏置,无法有效地将视觉特征约束在语言模型的语义空间内。这导致模型需要大量的数据进行训练,并且容易出现跨模态的语义错位,尤其是在文档理解等视觉和语言信息高度相关的任务中。
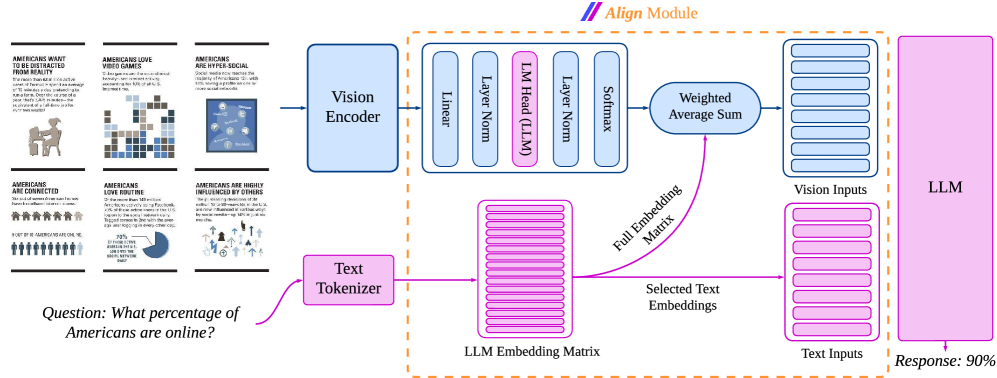
核心思路:AlignVLM的核心思路是将视觉特征映射到语言模型(LLM)文本嵌入的加权平均值。通过这种方式,视觉特征的表示被约束在LLM已经学习到的语言结构中,从而利用了LLM的语言先验知识。这种方法避免了从头学习视觉-语言对齐关系,而是直接将视觉信息融入到已有的语言知识体系中。
技术框架:AlignVLM的整体框架包括以下几个主要步骤:1. 使用视觉编码器提取视觉特征。2. 使用语言模型(LLM)提取文本嵌入。3. 将视觉特征通过AlignVLM模块映射到LLM的嵌入空间,具体来说,就是计算视觉特征与各个文本嵌入之间的权重,然后对文本嵌入进行加权平均。4. 将对齐后的视觉特征与文本嵌入一起输入到下游任务的模型中进行训练或推理。
关键创新:AlignVLM最重要的技术创新点在于其视觉-文本对齐方式。与传统的MLP等连接器不同,AlignVLM不是学习一个独立的映射函数,而是直接利用LLM的文本嵌入作为视觉特征的目标空间。这种方法能够更好地利用LLM的语言知识,从而提高视觉-语言对齐的准确性和效率。本质区别在于,AlignVLM是基于语言先验的对齐,而传统方法是数据驱动的对齐。
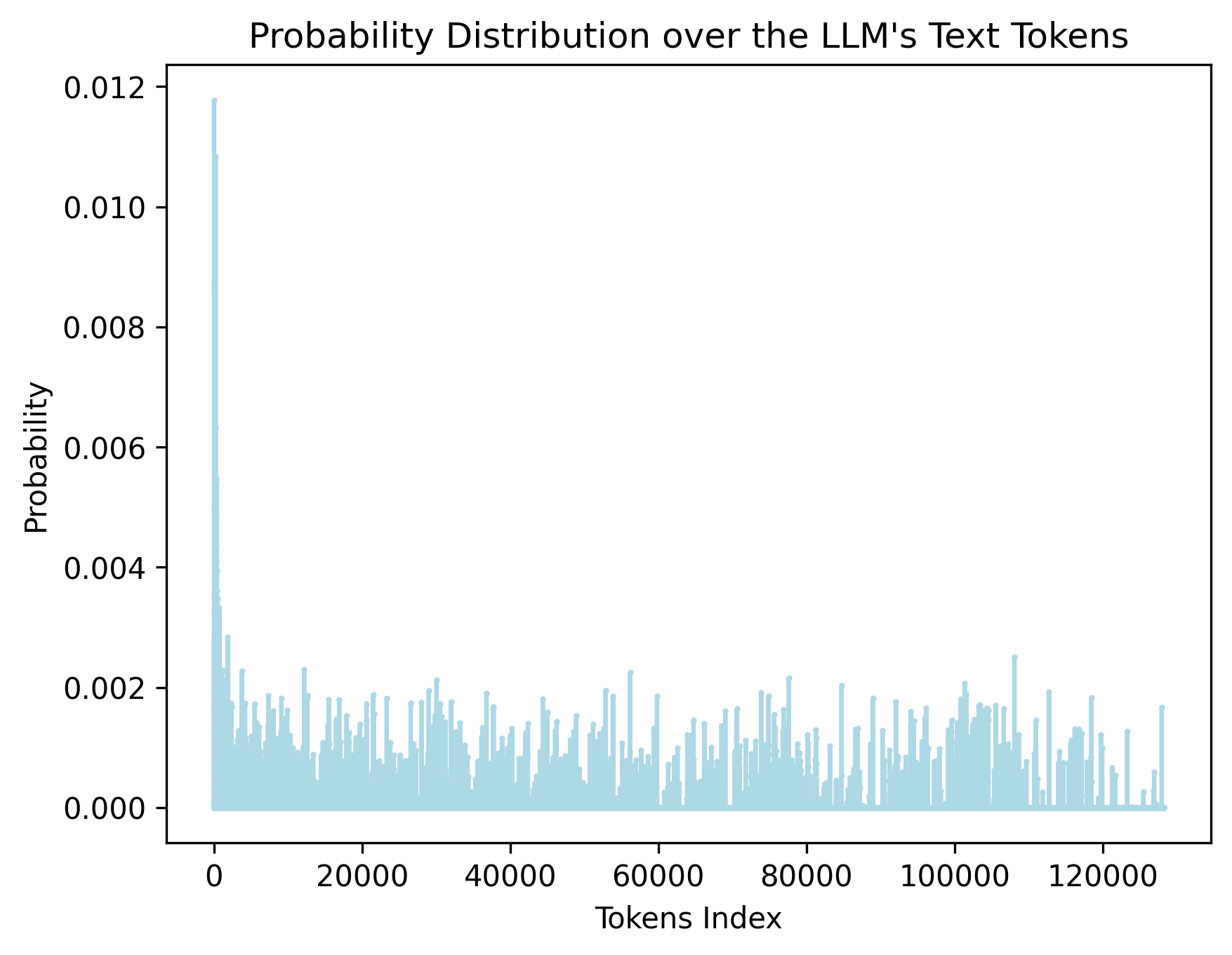
关键设计:AlignVLM的关键设计在于如何计算视觉特征与文本嵌入之间的权重。一种常用的方法是使用注意力机制,将视觉特征作为query,文本嵌入作为key和value,计算视觉特征与每个文本嵌入之间的相似度,然后使用softmax函数将相似度转换为权重。此外,还可以使用其他的相似度度量方法,如余弦相似度等。损失函数方面,可以使用对比学习损失或交叉熵损失等,以鼓励对齐后的视觉特征与相关的文本嵌入更加接近。
🖼️ 关键图片
📊 实验亮点
AlignVLM在文档理解任务上取得了显著的性能提升,尤其是在低资源场景下。实验结果表明,AlignVLM相比于传统的MLP连接器,在多个数据集上取得了SOTA性能,并且在数据量较少的情况下,提升幅度更加明显。这表明AlignVLM能够更有效地利用LLM的语言知识,从而提高视觉-语言对齐的准确性和鲁棒性。
🎯 应用场景
AlignVLM在多模态文档理解领域具有广泛的应用前景,例如智能文档处理、信息抽取、视觉问答、报告生成等。该方法能够提升模型在低资源场景下的性能,降低对大量标注数据的依赖,具有重要的实际应用价值。未来,AlignVLM可以扩展到其他视觉-语言任务中,例如图像描述、视频理解等。
📄 摘要(原文)
Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), lack inductive bias to constrain visual features within the linguistic structure of the LLM's embedding space, making them data-hungry and prone to cross-modal misalignment. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where visual and textual modalities are highly correlated. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods, with larger gains on document understanding tasks and under low-resource setups. We provide further analysis demonstrating its efficiency and robustness to noise.