Sparse Autoencoder Insights on Voice Embeddings
作者: Daniel Pluth, Yu Zhou, Vijay K. Gurbani
分类: cs.CL
发布日期: 2025-01-31
💡 一句话要点
利用稀疏自编码器解析语音嵌入,揭示单义特征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音嵌入 稀疏自编码器 单义特征 说话人识别 可解释机器学习
📋 核心要点
- 现有方法难以有效解析非文本数据的嵌入表示,阻碍了对语音等领域深层特征的理解。
- 本研究采用稀疏自编码器,从Titanet模型生成的说话人嵌入中提取单义特征,实现对语音嵌入的解析。
- 实验结果表明,该方法能够识别和操纵语言、音乐等特征,验证了其在非文本数据上的有效性。
📝 摘要(中文)
近年来,可解释机器学习的进展突显了稀疏自编码器在揭示密集编码嵌入中的单义特征方面的潜力。虽然大多数研究集中在大型语言模型(LLM)嵌入上,但该技术在其他领域的适用性在很大程度上仍未被探索。本研究将稀疏自编码器应用于从Titanet模型生成的说话人嵌入,证明了该技术在从非文本嵌入数据中提取单义特征方面的有效性。结果表明,提取的特征表现出与LLM嵌入中发现的特征相似的特性,包括特征分裂和操纵。分析表明,自编码器可以识别和操纵诸如语言和音乐等在原始嵌入中不明显的特征。研究结果表明,稀疏自编码器可以成为理解和解释包括基于音频的说话人识别在内的许多领域中嵌入数据的宝贵工具。
🔬 方法详解
问题定义:论文旨在解决如何从语音嵌入中提取可解释的单义特征的问题。现有方法,特别是针对LLM嵌入的方法,可能无法直接应用于语音嵌入,因为语音数据的特性与文本数据有显著差异。因此,如何有效地从语音嵌入中提取有意义的特征,并理解这些特征的含义,是本研究需要解决的关键问题。
核心思路:论文的核心思路是利用稀疏自编码器学习语音嵌入的稀疏表示。稀疏自编码器通过引入稀疏性约束,迫使网络学习到具有单义性的特征。通过分析这些稀疏特征,可以更好地理解语音嵌入中包含的信息,例如说话人的语言、音乐偏好等。这种方法借鉴了在LLM嵌入分析中的成功经验,并将其推广到语音领域。
技术框架:整体框架包括以下几个步骤:1) 使用Titanet模型生成说话人嵌入;2) 使用稀疏自编码器对说话人嵌入进行编码和解码;3) 分析自编码器学习到的稀疏特征,例如通过可视化、特征分裂分析等方法;4) 通过操纵这些特征,验证其代表的语义信息。主要模块包括Titanet模型(用于生成嵌入)、稀疏自编码器(用于特征提取)和特征分析模块(用于理解特征)。
关键创新:本研究的关键创新在于将稀疏自编码器应用于语音嵌入分析,并证明了其有效性。虽然稀疏自编码器在LLM嵌入分析中已经得到应用,但将其应用于非文本数据,特别是语音数据,仍然是一个新的尝试。此外,论文还展示了如何通过操纵稀疏特征来控制语音嵌入,这为语音处理和生成提供了一种新的思路。
关键设计:稀疏自编码器的关键设计包括:1) 编码器和解码器的网络结构,例如多层感知机;2) 稀疏性约束,例如L1正则化或KL散度;3) 稀疏性参数,用于控制稀疏程度;4) 损失函数,包括重构损失(例如均方误差)和稀疏性损失。这些参数需要根据具体的数据集和任务进行调整,以获得最佳的性能。
🖼️ 关键图片
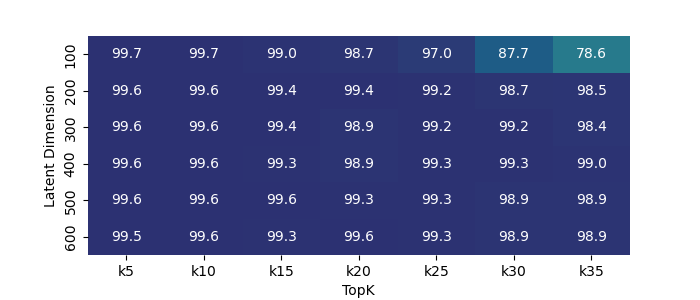
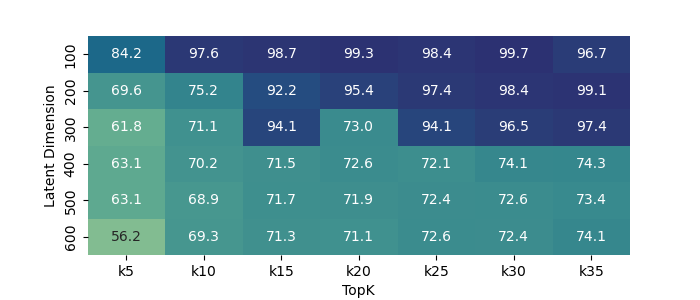
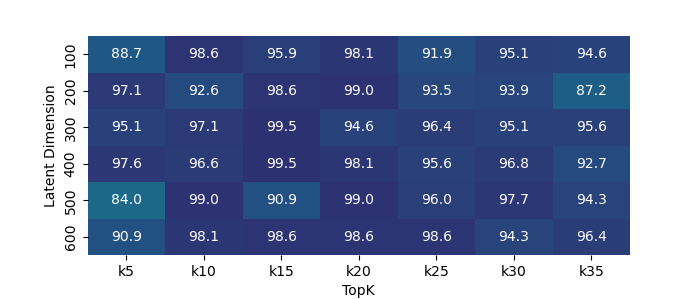
📊 实验亮点
实验结果表明,稀疏自编码器能够从Titanet模型生成的说话人嵌入中提取出具有单义性的特征,例如语言和音乐。通过操纵这些特征,可以改变语音嵌入的属性,例如改变说话人的语言风格或添加音乐背景。这些结果验证了该方法在语音嵌入分析中的有效性,并为未来的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于说话人识别、语音合成、语音情感分析等领域。通过理解语音嵌入中的单义特征,可以提高说话人识别的准确率,实现更自然的语音合成,并更好地理解语音中的情感信息。此外,该方法还可以用于语音数据的降维和可视化,方便研究人员进行分析和探索。未来,该技术有望应用于智能语音助手、语音社交等领域。
📄 摘要(原文)
Recent advances in explainable machine learning have highlighted the potential of sparse autoencoders in uncovering mono-semantic features in densely encoded embeddings. While most research has focused on Large Language Model (LLM) embeddings, the applicability of this technique to other domains remains largely unexplored. This study applies sparse autoencoders to speaker embeddings generated from a Titanet model, demonstrating the effectiveness of this technique in extracting mono-semantic features from non-textual embedded data. The results show that the extracted features exhibit characteristics similar to those found in LLM embeddings, including feature splitting and steering. The analysis reveals that the autoencoder can identify and manipulate features such as language and music, which are not evident in the original embedding. The findings suggest that sparse autoencoders can be a valuable tool for understanding and interpreting embedded data in many domains, including audio-based speaker recognition.