Efficient Beam Search for Large Language Models Using Trie-Based Decoding
作者: Brian J Chan, MaoXun Huang, Jui-Hung Cheng, Chao-Ting Chen, Hen-Hsen Huang
分类: cs.CL
发布日期: 2025-01-31 (更新: 2025-09-22)
备注: 13 pages, accepted as a main conference paper at EMNLP 2025
💡 一句话要点
提出基于Trie树解码的高效Beam Search方法,解决大语言模型内存瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Beam Search 大语言模型 Trie树 KV缓存 解码算法 内存优化 并行计算
📋 核心要点
- 现有Batch Beam Search方法在大语言模型推理时存在内存效率低下的问题,限制了其在资源受限环境中的应用。
- 论文提出基于Trie树的并行解码方法,通过共享具有相同前缀的beams的KV缓存,从而减少内存占用。
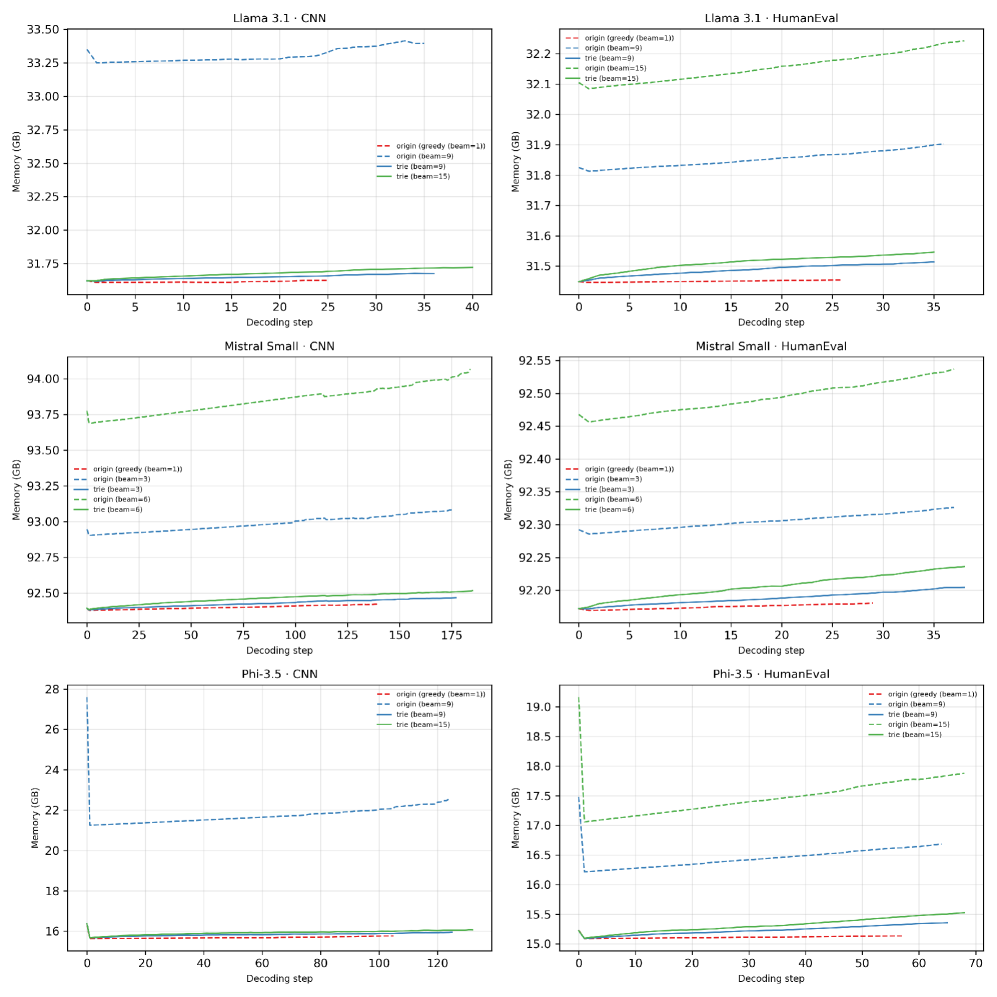
- 实验表明,该方法在多种注意力架构下,显著降低了内存使用,并提升了解码速度,同时保持了生成质量。
📝 摘要(中文)
本文提出了一种新颖的基于Trie树(前缀树)的并行解码方法,旨在解决基于批处理的Beam Search的内存效率问题。通过在具有共同前缀的beams之间共享单个KV缓存,我们的方法显著降低了内存使用,并实现了高效解码。我们使用CNN/DailyMail数据集进行抽象摘要,以及HumanEval数据集进行代码生成,在三种注意力架构上评估了我们的方法,包括Multi-Head Attention (Phi-3.5-mini-instruct)、Grouped Query Attention (Llama-3.1-8B-Instruct)和Sliding Window Attention (Mistral-Small-24B-Instruct-2501)。实验结果表明,在不影响生成质量的前提下,我们的方法可以显著节省内存(4-8倍),并实现高达2.4倍的解码速度提升。这些结果突显了我们的方法适用于内存受限的环境和大规模部署。
🔬 方法详解
问题定义:大语言模型解码过程中,Beam Search是一种常用的方法,但传统的Batch Beam Search在处理长序列或大规模模型时,需要为每个beam维护独立的KV缓存,导致内存占用过高,限制了其在资源受限设备上的应用。现有方法的痛点在于内存效率低,无法有效利用beams之间的共享信息。
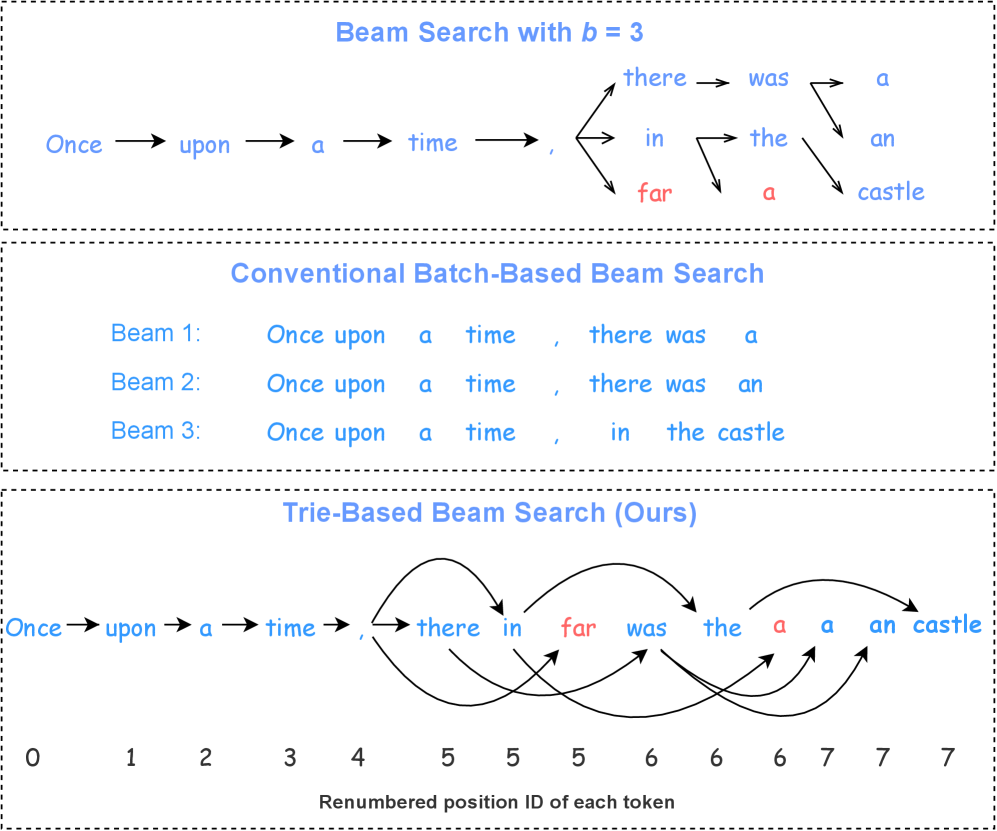
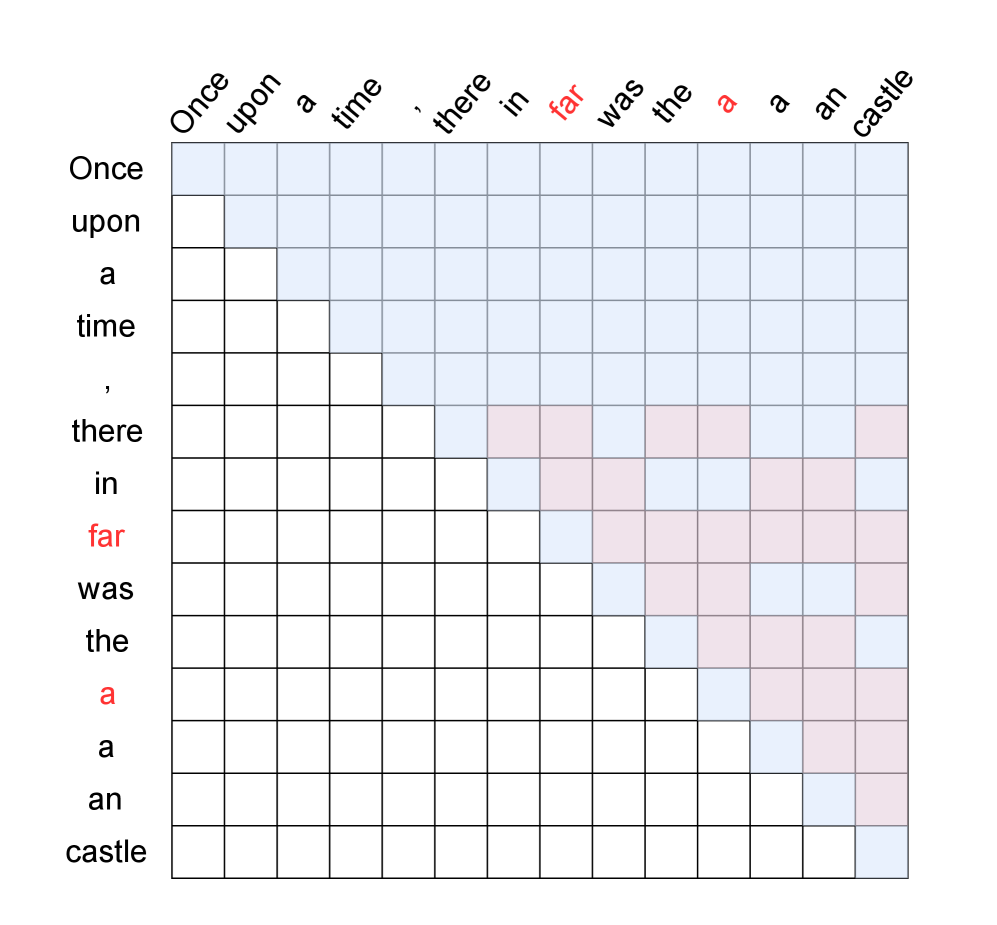
核心思路:论文的核心思路是利用Trie树(前缀树)来组织不同的beams,共享具有相同前缀的beams的KV缓存。这样,只需要为不同的后缀存储KV缓存,从而大幅减少内存占用。这种方法的核心在于最大化beams之间KV缓存的共享,提高内存利用率。
技术框架:整体框架包括以下几个主要阶段:1) 构建Trie树:根据当前beams的序列构建Trie树,相同前缀的beams在Trie树上共享路径。2) KV缓存共享:在Trie树的每个节点上,存储对应前缀的KV缓存。具有相同前缀的beams共享该节点的KV缓存。3) 并行解码:利用共享的KV缓存,并行解码每个beam的下一个token。4) Trie树更新:根据解码结果,更新Trie树结构,并调整KV缓存的分配。
关键创新:最重要的技术创新点是基于Trie树的KV缓存共享机制。与传统的Batch Beam Search为每个beam维护独立的KV缓存不同,该方法通过Trie树结构,实现了KV缓存的细粒度共享,极大地减少了内存占用。本质区别在于,传统方法没有考虑beams之间的共享信息,而该方法充分利用了beams之间的前缀重叠。
关键设计:关键设计包括:1) Trie树的构建和维护算法,需要高效地插入、删除和查找节点。2) KV缓存的分配和释放策略,需要保证内存使用的效率和安全性。3) 并行解码的实现,需要充分利用硬件资源,提高解码速度。具体的参数设置和网络结构与所使用的基础大语言模型架构相关,论文主要关注解码算法的优化,而非模型结构的修改。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在三种不同的注意力架构(Multi-Head Attention, Grouped Query Attention, Sliding Window Attention)下均取得了显著的性能提升。在CNN/DailyMail摘要生成和HumanEval代码生成任务上,该方法实现了4-8倍的内存节省,并提升了解码速度高达2.4倍,同时保持了与传统Batch Beam Search相当的生成质量。这些结果表明该方法具有很强的通用性和实用性。
🎯 应用场景
该研究成果可广泛应用于各种需要大语言模型进行文本生成或代码生成的场景,尤其是在内存资源受限的边缘设备或移动设备上。例如,可以用于移动端的智能助手、低功耗的嵌入式设备上的自然语言处理应用,以及大规模云端服务的低成本部署。该方法降低了对硬件资源的需求,使得大语言模型能够更广泛地应用。
📄 摘要(原文)
This work presents a novel trie (prefix-tree)-based parallel decoding method that addresses the memory inefficiency of batch-based beam search. By sharing a single KV cache across beams with common prefixes, our approach dramatically reduces memory usage and enables efficient decoding. We evaluated our method across three attention architectures, Multi-Head Attention (Phi-3.5-mini-instruct), Grouped Query Attention (Llama-3.1-8B-Instruct), and Sliding Window Attention (Mistral-Small-24B-Instruct-2501), using CNN/DailyMail for abstractive summarization and HumanEval for code generation. Our experiments demonstrate substantial memory savings (4--8$\times$) and up to 2.4$\times$ faster decoding, without compromising generation quality. These results highlight our method's suitability for memory-constrained environments and large-scale deployments.