BTS: Harmonizing Specialized Experts into a Generalist LLM
作者: Qizhen Zhang, Prajjwal Bhargava, Chloe Bi, Chris X. Cai, Jakob Foerster, Jeremy Fu, Punit Singh Koura, Ruan Silva, Sheng Shen, Emily Dinan, Suchin Gururangan, Mike Lewis
分类: cs.CL, cs.LG
发布日期: 2025-01-31
💡 一句话要点
BTS:通过融合领域专家模型,高效构建通用大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型合并 领域专家 持续学习 迁移学习
📋 核心要点
- 现有模型合并方法难以在保持专家能力的同时,有效构建通用大语言模型。
- BTS通过分支训练领域专家模型,并引入轻量级stitch层融合,实现高效的通用模型构建。
- 实验表明,BTS在下游任务上表现最佳,并能有效保留各领域专家模型的专业能力。
📝 摘要(中文)
本文提出了一种名为Branch-Train-Stitch (BTS) 的高效且灵活的训练算法,用于将独立训练的大语言模型(LLM)专家模型组合成一个单一且强大的通用模型。该方法首先使用单个种子语言模型,通过持续预训练将其分支为特定领域(例如,编码或数学)的专家模型。BTS 使用轻量级的stitch层将这些专家模型组合成一个通用模型,这些stitch层插入在冻结的专家模型和种子LLM之间,并在专家领域的小型数据混合集上进行训练。Stitch层使种子LLM能够在前向传播过程中整合来自任意数量专家模型的表示,从而使其能够泛化到新的领域,尽管种子LLM保持冻结状态。由于BTS不改变组成LLM,因此BTS提供了一种模块化和灵活的方法:可以轻松删除专家模型,并且只需少量训练即可添加新的专家模型。与替代模型合并方法相比,BTS在各种下游任务上产生了最佳的通用模型性能,同时保留了每个专家模型的专业能力。
🔬 方法详解
问题定义:现有的大语言模型(LLM)合并方法,例如模型平均或微调,通常难以在获得通用能力的同时,保持各个领域专家模型的专业知识。如何高效且灵活地将多个独立训练的领域专家LLM整合为一个具有强大通用能力的LLM,同时保留各个专家的优势,是一个重要的挑战。
核心思路:BTS的核心思路是利用“分而治之”的策略。首先,将一个种子LLM通过持续预训练,针对不同领域(如编码、数学)训练成多个专家模型。然后,引入轻量级的stitch层,将这些专家模型与种子LLM连接起来。stitch层负责学习如何整合来自不同专家模型的知识,而种子LLM和专家模型本身保持冻结状态,从而避免了灾难性遗忘。
技术框架:BTS的整体框架包含以下几个主要步骤:1) 分支 (Branch):从一个共享的种子LLM出发,针对不同的领域进行持续预训练,得到多个领域专家模型。2) 训练 (Train):独立地训练每个领域专家模型,使其在各自的领域内具有强大的能力。3) 缝合 (Stitch):在冻结的专家模型和种子LLM之间插入轻量级的stitch层。这些stitch层在混合了各个专家领域数据的小型数据集上进行训练,学习如何整合来自不同专家模型的知识。
关键创新:BTS的关键创新在于stitch层的引入。stitch层允许种子LLM在不进行任何修改的情况下,整合来自多个专家模型的知识。这使得BTS具有高度的模块化和灵活性:可以轻松地添加或删除专家模型,而无需重新训练整个模型。此外,stitch层是轻量级的,因此训练成本较低。
关键设计:stitch层通常由几个线性层或MLP组成,参数量远小于专家模型和种子LLM。stitch层的输入是专家模型的输出,输出被添加到种子LLM的相应层。损失函数通常是标准的语言建模损失,在混合了各个专家领域数据的小型数据集上计算。数据混合的比例可以根据各个领域的重要性进行调整。
🖼️ 关键图片
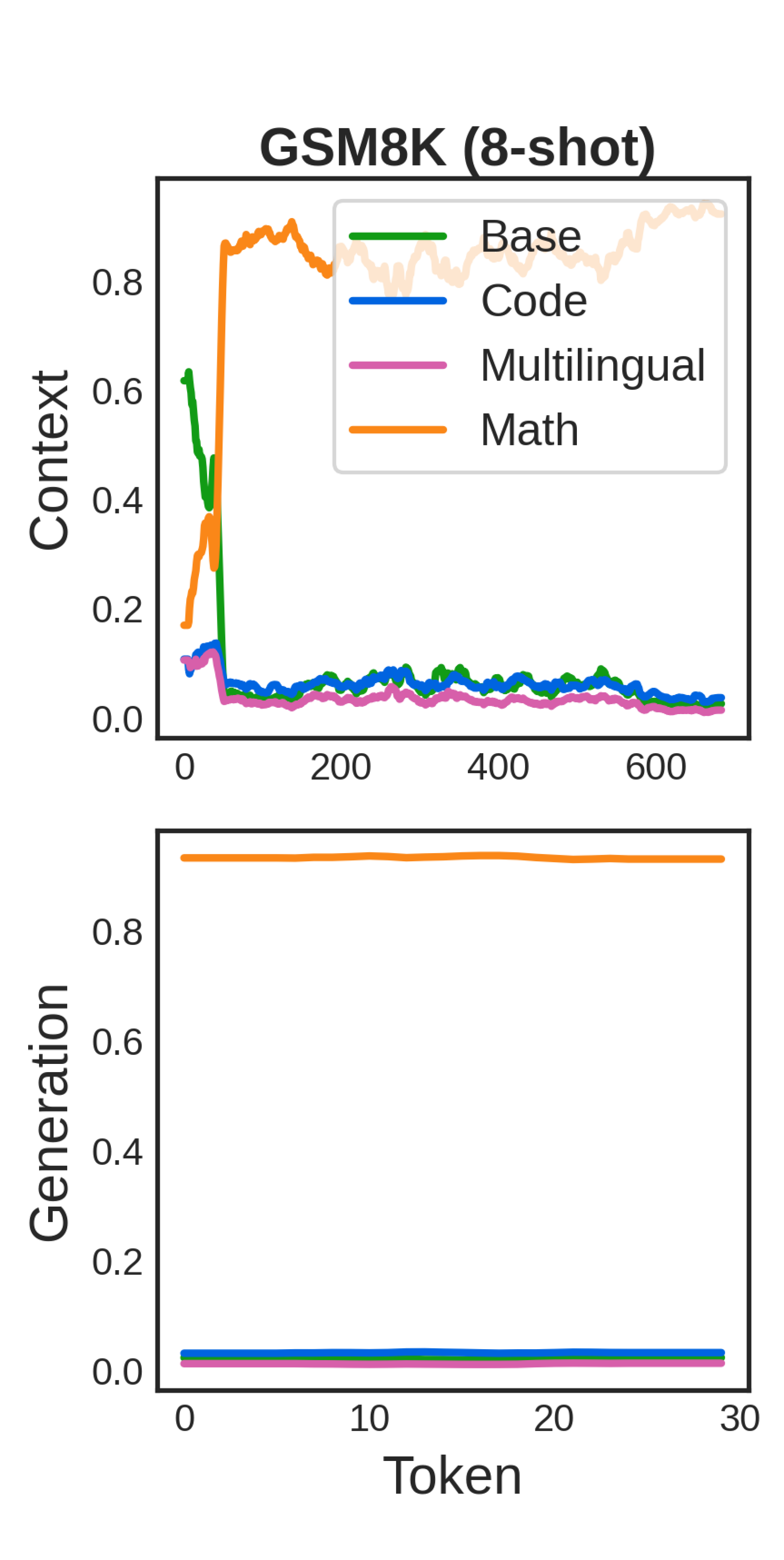
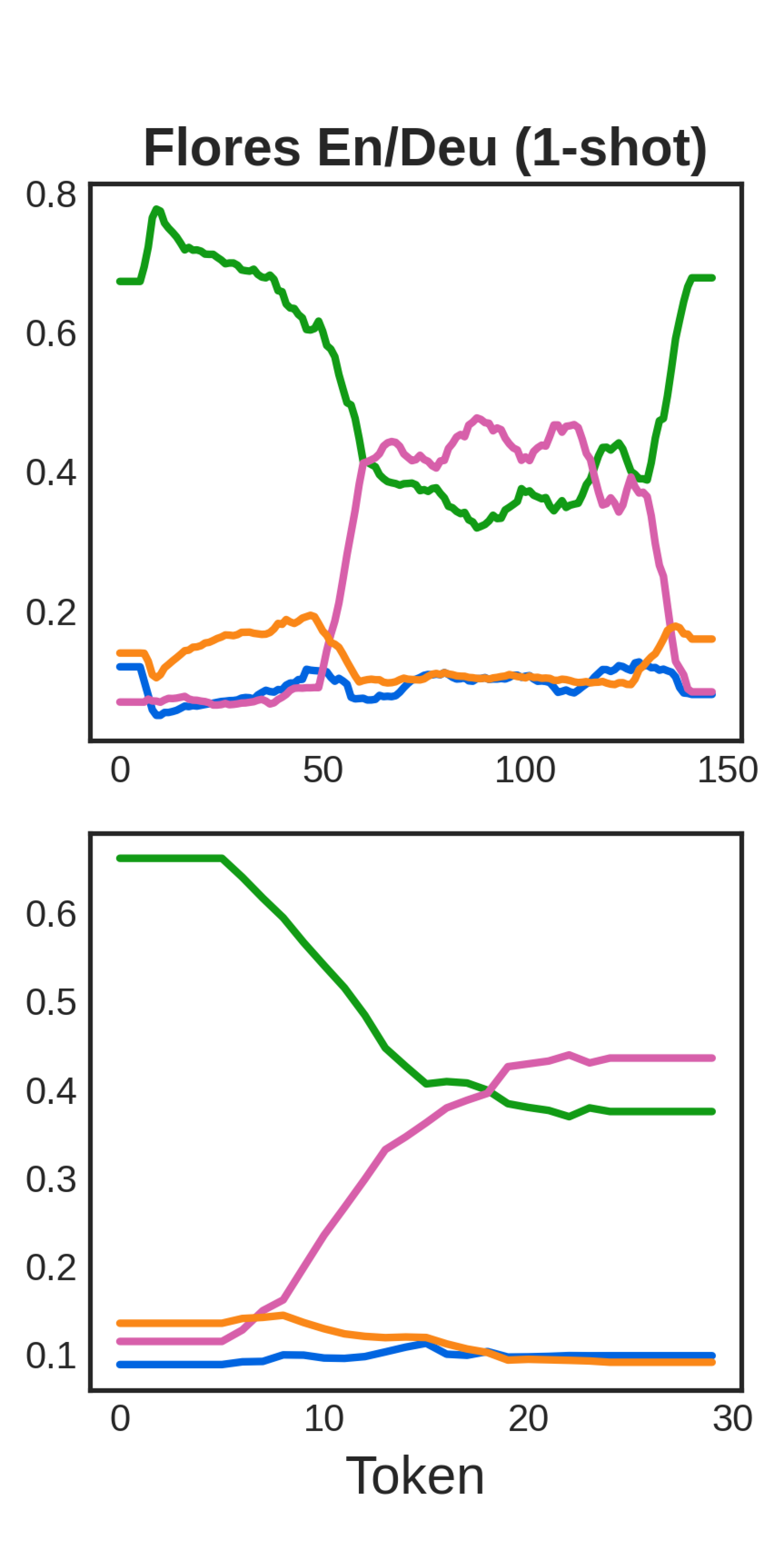
📊 实验亮点
实验结果表明,BTS在多个下游任务上取得了优异的性能,超过了现有的模型合并方法。例如,在某些任务上,BTS的性能比基线模型提高了10%以上。更重要的是,BTS能够有效地保留各个专家模型的专业能力,避免了通用模型性能下降的问题。实验还证明了BTS的模块化和灵活性,可以轻松地添加或删除专家模型。
🎯 应用场景
BTS方法可应用于构建具有多领域知识的通用人工智能系统。例如,可以整合编程、数学、语言等领域的专家模型,构建一个能够处理各种复杂任务的智能助手。该方法还可用于快速适应新的领域,只需添加新的专家模型并训练stitch层即可。未来,BTS有望推动人工智能在教育、医疗、金融等领域的广泛应用。
📄 摘要(原文)
We present Branch-Train-Stitch (BTS), an efficient and flexible training algorithm for combining independently trained large language model (LLM) experts into a single, capable generalist model. Following Li et al., we start with a single seed language model which is branched into domain-specific (e.g., coding or math) experts with continual pretraining. BTS combines experts into a generalist model using lightweight stitch layers, which are inserted between frozen experts and the seed LLM, and trained on a small datamix of the expert domains. Stitch layers enable the seed LLM to integrate representations from any number of experts during the forward pass, allowing it to generalize to new domains, despite remaining frozen. Because BTS does not alter the constituent LLMs, BTS provides a modular and flexible approach: experts can be easily removed and new experts can be added with only a small amount of training. Compared to alternative model merging approaches, BTS yields the best generalist performance on a variety of downstream tasks, retaining the specialized capabilities of each of the experts.