Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SciCap Challenge 2023
作者: Ting-Yao E. Hsu, Yi-Li Hsu, Shaurya Rohatgi, Chieh-Yang Huang, Ho Yin Sam Ng, Ryan Rossi, Sungchul Kim, Tong Yu, Lun-Wei Ku, C. Lee Giles, Ting-Hao K. Huang
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-01-31 (更新: 2025-02-18)
备注: Accepted to TACL 2025
💡 一句话要点
SciCap Challenge 2023揭示大型多模态模型在科学图表标题生成中的能力与局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学图表标题生成 大型多模态模型 GPT-4V SciCap Challenge 视觉-语言任务
📋 核心要点
- 现有科学图表标题生成模型在处理跨领域、多样化图表类型时仍面临挑战,难以满足专业编辑的标准。
- 该研究通过SciCap Challenge评估了包括GPT-4V在内的大型多模态模型在科学图表标题生成任务中的表现。
- 实验结果表明,GPT-4V生成的标题在专业编辑的偏好度上显著优于其他模型和人工撰写的标题,但仍有改进空间。
📝 摘要(中文)
自2021年SciCap数据集发布以来,学术界在生成学术文章中科学图表的标题方面取得了显著进展。2023年,首届SciCap Challenge举办,邀请全球团队使用扩展的SciCap数据集开发模型,为各个学术领域的不同图表类型生成标题。与此同时,文本生成模型迅速发展,涌现出许多强大的预训练大型多模态模型(LMM),在各种视觉-语言任务中表现出令人印象深刻的能力。本文概述了首届SciCap Challenge,并详细介绍了各种模型在其数据上的性能,捕捉了该领域的现状。研究发现,专业编辑人员绝大多数更喜欢GPT-4V生成的图表标题,而不是所有其他模型,甚至包括作者撰写的原始标题。基于这一关键发现,我们进行了详细分析,以回答这个问题:先进的LMM是否解决了科学图表标题生成的任务?
🔬 方法详解
问题定义:论文旨在评估大型多模态模型(LMMs)在科学图表标题生成任务中的能力。现有方法,包括人工撰写的标题和传统模型生成的标题,在准确性、信息量和可读性方面存在不足,难以满足专业编辑的需求。SciCap Challenge旨在推动该领域的发展,并探索LMMs是否能够有效解决这些问题。
核心思路:论文的核心思路是通过举办SciCap Challenge,收集不同模型生成的科学图表标题,并由专业编辑进行评估,从而客观地衡量LMMs在这一任务中的表现。重点关注GPT-4V,因为它在初步评估中表现出色。通过对比GPT-4V与其他模型以及人工撰写的标题,深入分析LMMs的优势和局限性。
技术框架:该研究主要依赖于SciCap Challenge的数据集和评估框架。SciCap数据集包含各种学术领域的科学图表及其对应的标题。挑战赛参与者使用各种模型生成图表标题,然后由专业编辑对这些标题进行评估和排序。评估指标包括准确性、信息量、可读性和整体质量。研究人员对GPT-4V生成的标题进行了更深入的分析,包括错误类型分析和消融实验。
关键创新:该研究的关键创新在于使用专业编辑的评估作为主要评价标准,这比传统的自动评估指标更贴近实际应用场景。此外,该研究首次系统地评估了GPT-4V等先进LMMs在科学图表标题生成任务中的表现,并揭示了其优势和局限性。
关键设计:SciCap Challenge的设计包括:1) 扩展的SciCap数据集,包含更多样化的图表类型和学术领域;2) 专业编辑参与的评估流程,确保评估的质量和客观性;3) 多种评估指标,全面衡量模型生成的标题的质量;4) 对GPT-4V生成的标题进行深入分析,包括错误类型分析和消融实验,以了解其工作原理和改进方向。
🖼️ 关键图片

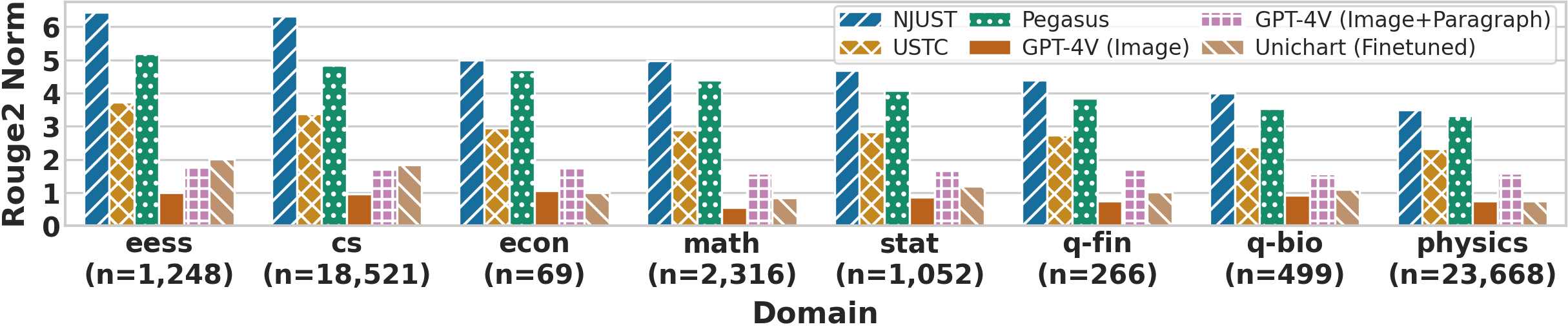
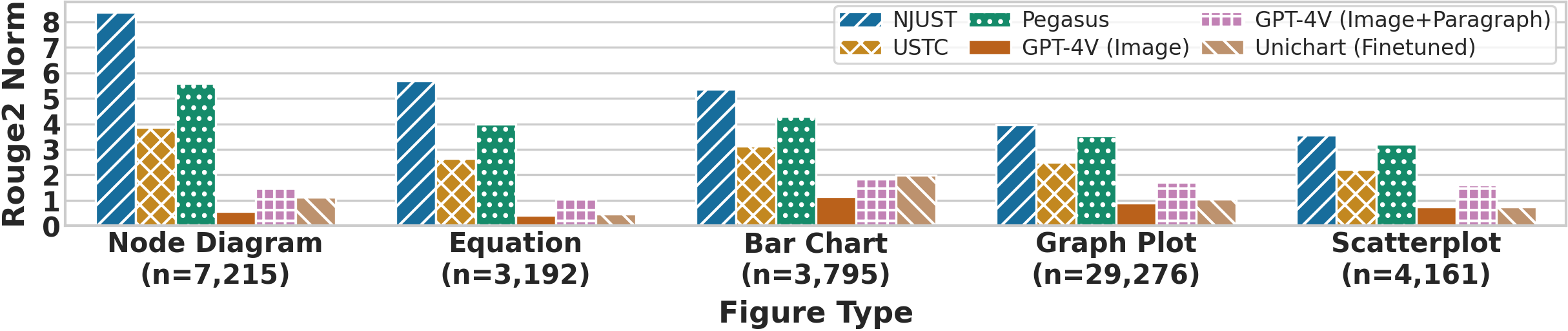
📊 实验亮点
实验结果表明,GPT-4V生成的图表标题在专业编辑的偏好度上显著优于其他模型和人工撰写的标题。具体来说,GPT-4V在准确性、信息量和可读性方面均表现出色。然而,GPT-4V仍然存在一些问题,例如有时会产生不准确或不相关的标题。未来的研究可以集中在解决这些问题,进一步提高LMMs在科学图表标题生成任务中的性能。
🎯 应用场景
该研究成果可应用于自动化科学论文写作、辅助科研人员快速理解图表内容、提升学术交流效率等领域。高质量的图表标题生成模型可以嵌入到学术出版平台,自动生成图表标题,减轻作者负担,提高论文质量。此外,该技术还可以应用于教育领域,帮助学生更好地理解科学图表。
📄 摘要(原文)
Since the SciCap datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SciCap Challenge took place, inviting global teams to use an expanded SciCap dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SciCap Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?