Reward-Guided Speculative Decoding for Efficient LLM Reasoning
作者: Baohao Liao, Yuhui Xu, Hanze Dong, Junnan Li, Christof Monz, Silvio Savarese, Doyen Sahoo, Caiming Xiong
分类: cs.CL, cs.AI
发布日期: 2025-01-31 (更新: 2025-06-26)
备注: 17 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出奖励引导的推测解码(RSD),提升大语言模型推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大语言模型 推理加速 奖励模型 效率优化
📋 核心要点
- 现有推测解码方法通常强制无偏性,忽略了输出质量的差异,导致效率提升受限。
- RSD通过奖励模型引导,有偏地选择更有希望的token序列,在效率和质量间取得平衡。
- 实验表明,RSD在推理任务上显著提升效率(减少FLOPs),并优于并行解码的准确率。
📝 摘要(中文)
本文提出了一种名为奖励引导的推测解码(RSD)的新框架,旨在提高大型语言模型(LLM)的推理效率。RSD协同结合了一个轻量级的草稿模型和一个更强大的目标模型,引入了一种受控的偏差来优先考虑高奖励的输出,这与现有推测解码方法强制执行严格无偏性形成对比。RSD采用过程奖励模型来评估中间解码步骤,并动态决定是否调用目标模型,从而优化计算成本和输出质量之间的权衡。理论上证明,基于阈值的混合策略实现了资源利用率和性能之间的最佳平衡。在包括奥林匹克级别任务在内的具有挑战性的推理基准上的广泛评估表明,RSD相对于仅使用目标模型进行解码而言,实现了显著的效率提升(减少高达4.4倍的FLOPs),同时比并行解码方法实现了显著更高的平均准确率(高达+3.5)。这些结果突出了RSD作为一种在资源密集型场景中部署LLM的稳健且经济高效的方法。
🔬 方法详解
问题定义:现有的大语言模型推理效率较低,尤其是在复杂的推理任务中。传统的推测解码方法为了保证无偏性,可能会接受一些低质量的草稿 token,从而降低整体效率。因此,如何在保证一定输出质量的前提下,尽可能地减少计算量,是一个重要的挑战。
核心思路:RSD的核心思路是引入一个奖励模型,用于评估草稿模型生成的 token 序列的质量。通过奖励模型,RSD可以有偏地选择更有可能产生高质量输出的 token 序列,从而避免了对所有草稿 token 进行验证的需要,提高了推理效率。
技术框架:RSD框架主要包含三个部分:轻量级的草稿模型、强大的目标模型和过程奖励模型。首先,草稿模型快速生成多个 token 序列;然后,奖励模型对这些序列进行评估,并根据奖励值决定是否需要目标模型进行验证。如果奖励值高于设定的阈值,则接受该序列,否则,使用目标模型重新生成。这个过程迭代进行,直到生成完整的输出。
关键创新:RSD的关键创新在于引入了奖励模型来指导推测解码过程。与传统的推测解码方法不同,RSD允许一定的偏差,从而可以更加高效地利用草稿模型生成的 token 序列。此外,RSD还提出了一种基于阈值的混合策略,用于平衡资源利用率和性能。
关键设计:RSD的关键设计包括奖励模型的选择和阈值的设定。奖励模型需要能够准确地评估 token 序列的质量,常用的方法是使用一个较小的语言模型或者一个专门训练的奖励模型。阈值的设定则需要根据具体的任务和模型进行调整,以达到最佳的效率和准确率平衡。
🖼️ 关键图片
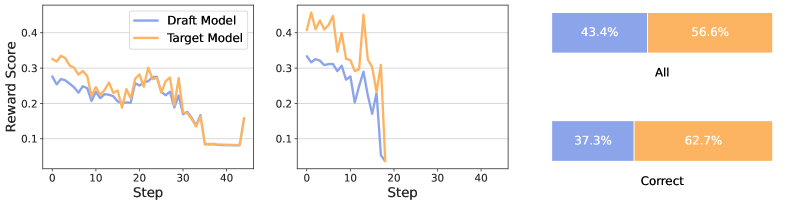
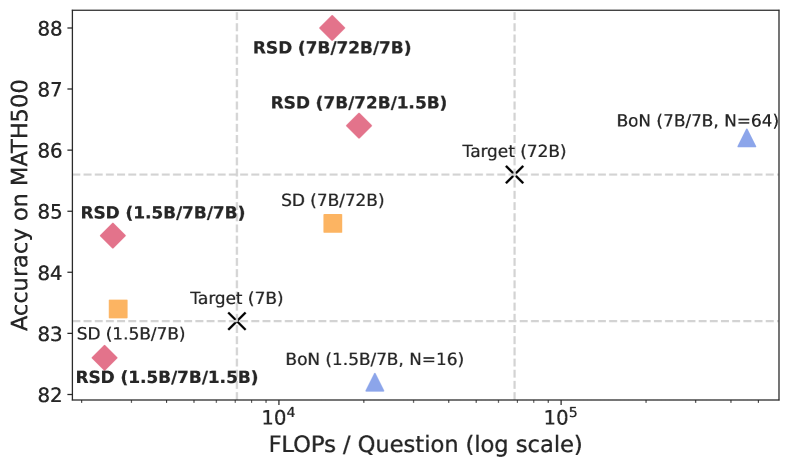
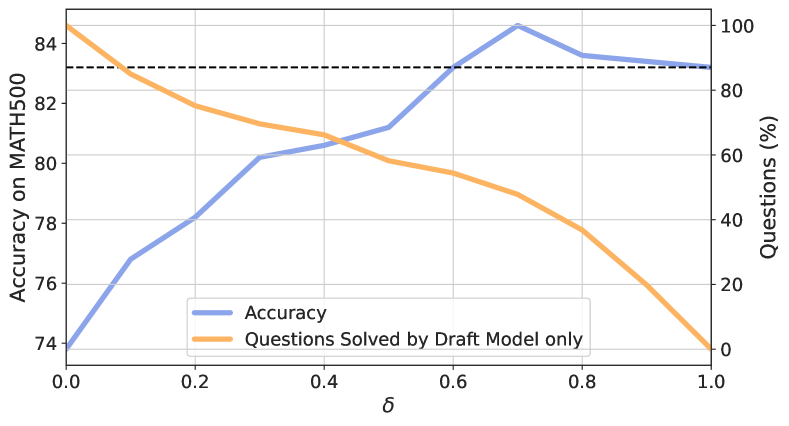
📊 实验亮点
实验结果表明,RSD在推理任务上实现了显著的效率提升,最高可减少4.4倍的FLOPs。同时,RSD在准确率方面也优于并行解码方法,平均提升高达3.5%。这些结果表明,RSD是一种高效且有效的LLM推理加速方法。
🎯 应用场景
RSD适用于对推理效率有较高要求的场景,例如在线对话系统、智能客服、以及需要快速生成高质量文本的各种应用。通过降低计算成本,RSD可以使得大型语言模型更容易部署在资源受限的设备上,并降低运营成本。未来,RSD可以进一步扩展到其他类型的生成任务,例如图像生成和代码生成。
📄 摘要(原文)
We introduce Reward-Guided Speculative Decoding (RSD), a novel framework aimed at improving the efficiency of inference in large language models (LLMs). RSD synergistically combines a lightweight draft model with a more powerful target model, incorporating a controlled bias to prioritize high-reward outputs, in contrast to existing speculative decoding methods that enforce strict unbiasedness. RSD employs a process reward model to evaluate intermediate decoding steps and dynamically decide whether to invoke the target model, optimizing the trade-off between computational cost and output quality. We theoretically demonstrate that a threshold-based mixture strategy achieves an optimal balance between resource utilization and performance. Extensive evaluations on challenging reasoning benchmarks, including Olympiad-level tasks, show that RSD delivers significant efficiency gains against decoding with the target model only (up to 4.4x fewer FLOPs), while achieving significant better accuracy than parallel decoding method on average (up to +3.5). These results highlight RSD as a robust and cost-effective approach for deploying LLMs in resource-intensive scenarios. The code is available at https://github.com/BaohaoLiao/RSD.