mFollowIR: a Multilingual Benchmark for Instruction Following in Retrieval
作者: Orion Weller, Benjamin Chang, Eugene Yang, Mahsa Yarmohammadi, Sam Barham, Sean MacAvaney, Arman Cohan, Luca Soldaini, Benjamin Van Durme, Dawn Lawrie
分类: cs.IR, cs.CL, cs.LG
发布日期: 2025-01-31
备注: Accepted to ECIR 2025
💡 一句话要点
提出mFollowIR多语言基准,评估检索模型在指令跟随方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言检索 指令跟随 信息检索 跨语言检索 基准数据集
📋 核心要点
- 现有检索模型主要针对英语,缺乏对多语言环境下指令跟随能力的评估。
- mFollowIR基准通过构建多语言指令数据集,评估模型理解和执行复杂查询的能力。
- 实验表明,基于英语训练的模型在跨语言任务中表现良好,但在多语言环境中性能下降。
📝 摘要(中文)
检索系统通常侧重于简短且不明确的Web式查询。然而,语言模型的进步促进了能够理解具有多样化意图的更复杂查询的检索模型的兴起。但是,这些努力仅集中在英语上;因此,我们尚不了解它们在不同语言中的工作方式。我们引入了mFollowIR,这是一个用于衡量检索模型中指令跟随能力的多语言基准。mFollowIR建立在TREC NeuCLIR叙述(或指令)之上,这些叙述跨越三种不同的语言(俄语,中文,波斯语),为检索模型提供查询和指令。我们对叙述进行了小的更改,并隔离了检索模型能够多好地遵循这些细微的更改。我们展示了多语言(XX-XX)和跨语言(En-XX)性能的结果。我们看到基于英语的检索器在使用指令训练的情况下具有强大的跨语言性能,但发现在多语言设置中性能显着下降,这表明在开发用于基于指令的多语言检索器的数据方面还需要做更多的工作。
🔬 方法详解
问题定义:现有检索系统主要处理简短、不明确的英文查询,难以应对复杂指令和多语言环境。缺乏针对多语言指令跟随检索的基准数据集,阻碍了相关技术的发展。现有方法在多语言环境下的性能表现未知,需要进一步研究。
核心思路:构建一个多语言指令跟随检索基准数据集mFollowIR,包含多种语言的指令和对应的文档。通过评估模型在不同语言环境下的检索性能,衡量其指令跟随能力。重点关注模型在多语言和跨语言环境下的表现差异。
技术框架:mFollowIR数据集基于TREC NeuCLIR数据集构建,包含俄语、中文和波斯语三种语言的叙述(指令)。对原始叙述进行细微修改,以评估模型对指令变化的敏感度。实验评估了多语言(XX-XX)和跨语言(En-XX)两种设置下的检索性能。
关键创新:首次提出了一个多语言指令跟随检索基准数据集mFollowIR,填补了该领域的研究空白。该数据集包含多种语言的指令,可以用于评估模型在多语言环境下的指令跟随能力。通过对指令进行细微修改,可以更精确地评估模型对指令变化的敏感度。
关键设计:数据集构建过程中,对TREC NeuCLIR的叙述进行了人工修改,以确保指令的质量和多样性。实验评估采用了常用的检索指标,如MAP、NDCG等。针对多语言和跨语言两种设置,分别评估了模型的性能。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

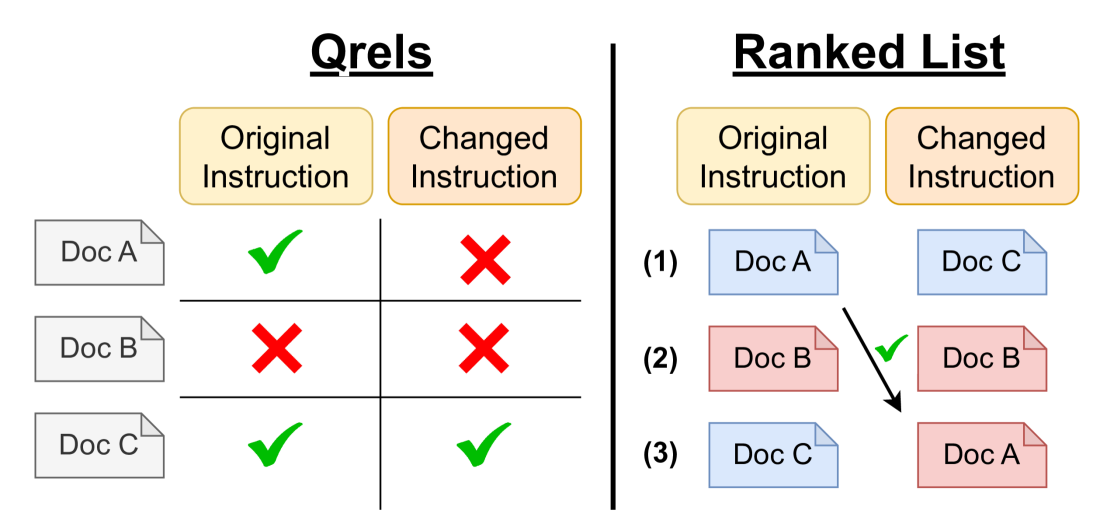
📊 实验亮点
实验结果表明,基于英语训练的检索模型在跨语言设置下表现良好,但在多语言设置下性能显著下降。这表明,现有模型在多语言环境下的指令跟随能力仍有提升空间。该研究为未来多语言指令跟随检索的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于多语言信息检索、跨语言信息检索、智能助手、多语言搜索引擎等领域。通过提升模型在多语言环境下的指令跟随能力,可以为用户提供更准确、更个性化的信息服务。未来可进一步扩展到更多语言和领域,推动多语言信息检索技术的发展。
📄 摘要(原文)
Retrieval systems generally focus on web-style queries that are short and underspecified. However, advances in language models have facilitated the nascent rise of retrieval models that can understand more complex queries with diverse intents. However, these efforts have focused exclusively on English; therefore, we do not yet understand how they work across languages. We introduce mFollowIR, a multilingual benchmark for measuring instruction-following ability in retrieval models. mFollowIR builds upon the TREC NeuCLIR narratives (or instructions) that span three diverse languages (Russian, Chinese, Persian) giving both query and instruction to the retrieval models. We make small changes to the narratives and isolate how well retrieval models can follow these nuanced changes. We present results for both multilingual (XX-XX) and cross-lingual (En-XX) performance. We see strong cross-lingual performance with English-based retrievers that trained using instructions, but find a notable drop in performance in the multilingual setting, indicating that more work is needed in developing data for instruction-based multilingual retrievers.