Efficient Reasoning with Hidden Thinking
作者: Xuan Shen, Yizhou Wang, Xiangxi Shi, Yanzhi Wang, Pu Zhao, Jiuxiang Gu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-31
备注: Preprint version
💡 一句话要点
提出Heima框架,通过隐空间推理提升多模态大语言模型效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 链式思考 隐空间推理 高效推理 模型压缩
📋 核心要点
- 现有CoT推理方法在多模态大模型中存在冗长文本推理导致的效率瓶颈。
- Heima框架通过在隐空间进行CoT推理,使用紧凑的隐表示降低token数量。
- 实验表明Heima在提升推理效率的同时,保持甚至提升了零样本任务准确率。
📝 摘要(中文)
链式思考(CoT)推理已成为提升多模态大语言模型(MLLM)复杂问题解决能力的强大框架。然而,文本推理的冗长性带来了显著的效率低下。本文提出了Heima(作为隐藏的llama),一个高效的推理框架,它利用隐空间中的推理CoT。我们设计了Heima编码器,使用单个思考token将每个中间CoT压缩成紧凑的、更高层次的隐藏表示,从而有效地最小化冗长性并减少推理过程中所需的token总数。同时,我们设计了带有传统大语言模型(LLM)的相应Heima解码器,以自适应地将隐藏表示解释为可变长度的文本序列,重建与原始CoT非常相似的推理过程。在各种推理MLLM基准上的实验结果表明,Heima模型在保持甚至更好的零样本任务准确率的同时,实现了更高的生成效率。此外,Heima解码器对多模态推理过程的有效重建验证了我们方法的鲁棒性和可解释性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)中,使用链式思考(CoT)进行推理时,由于文本推理过程冗长而导致的效率低下的问题。现有的CoT方法需要处理大量的文本token,增加了计算成本和延迟,限制了其在实际应用中的部署。
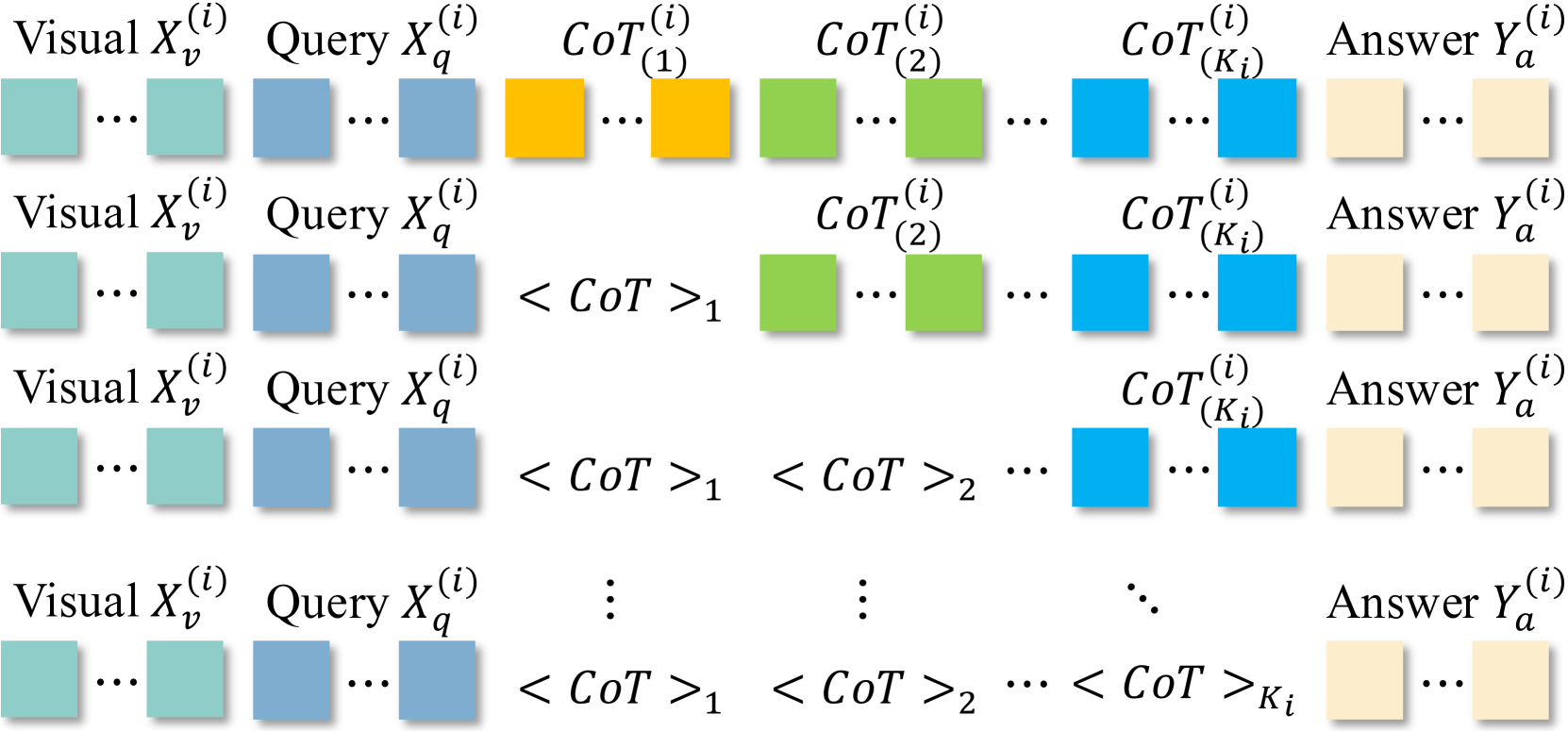
核心思路:论文的核心思路是将CoT推理过程映射到隐空间中进行。通过设计一个编码器将中间的CoT步骤压缩成一个紧凑的隐表示(单个thinking token),从而减少token数量,提高推理效率。然后,使用一个解码器将隐表示转换回可理解的文本推理过程。
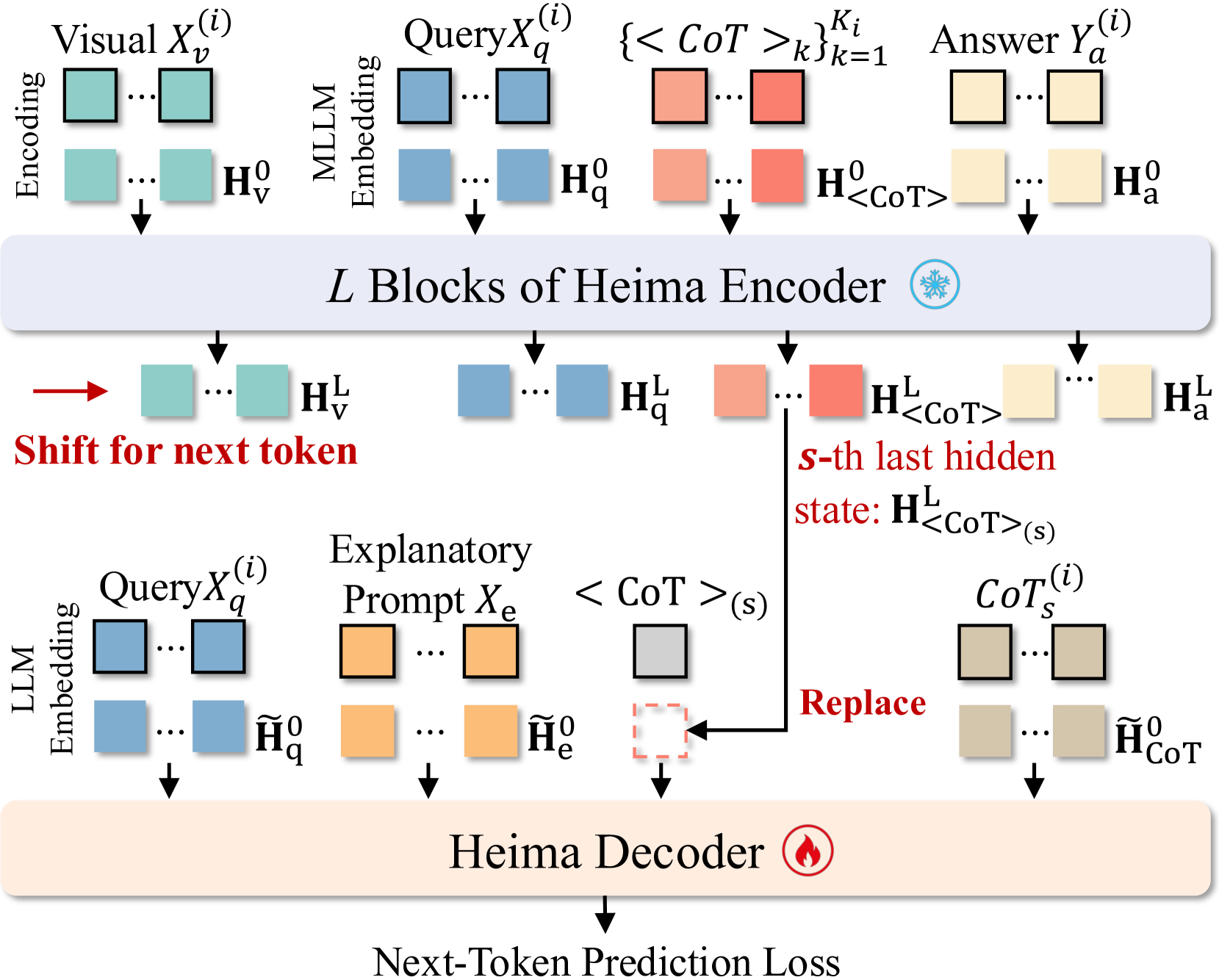
技术框架:Heima框架包含两个主要模块:Heima编码器和Heima解码器。Heima编码器负责将每个中间CoT步骤编码成一个紧凑的隐表示。Heima解码器则负责将这些隐表示解码回文本序列,重建推理过程。整个框架利用现有的LLM作为解码器的基础,并针对隐空间推理进行了优化。
关键创新:该论文的关键创新在于提出了在隐空间进行CoT推理的思想,并设计了相应的编码器和解码器。与传统的CoT方法直接处理文本token不同,Heima框架通过隐表示来压缩推理过程,从而显著减少了token数量。此外,Heima解码器能够自适应地将隐表示解释为可变长度的文本序列,保证了推理过程的灵活性和可解释性。
关键设计:Heima编码器使用一个单层Transformer网络将CoT文本序列映射到单个thinking token。Heima解码器则使用一个标准的LLM,并添加了一个适配器层,用于将隐表示转换为LLM可以理解的输入。损失函数包括重构损失,用于保证解码器能够准确地重建原始的CoT推理过程。具体的参数设置和网络结构细节在论文中有更详细的描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Heima模型在多个推理MLLM基准测试中,在保持甚至提高零样本任务准确率的同时,显著提高了生成效率。具体的数据指标(例如加速比、准确率提升等)在论文中有详细的呈现,与现有CoT方法相比,Heima在效率和准确率之间取得了更好的平衡。
🎯 应用场景
Heima框架可应用于各种需要高效推理的多模态大语言模型应用场景,例如智能问答、图像理解、视频分析等。通过减少推理所需的token数量,可以降低计算成本,提高响应速度,从而更好地支持实时应用和资源受限的设备。该研究还有助于提升模型的可解释性,为模型调试和优化提供更多信息。
📄 摘要(原文)
Chain-of-Thought (CoT) reasoning has become a powerful framework for improving complex problem-solving capabilities in Multimodal Large Language Models (MLLMs). However, the verbose nature of textual reasoning introduces significant inefficiencies. In this work, we propose $\textbf{Heima}$ (as hidden llama), an efficient reasoning framework that leverages reasoning CoTs at hidden latent space. We design the Heima Encoder to condense each intermediate CoT into a compact, higher-level hidden representation using a single thinking token, effectively minimizing verbosity and reducing the overall number of tokens required during the reasoning process. Meanwhile, we design corresponding Heima Decoder with traditional Large Language Models (LLMs) to adaptively interpret the hidden representations into variable-length textual sequence, reconstructing reasoning processes that closely resemble the original CoTs. Experimental results across diverse reasoning MLLM benchmarks demonstrate that Heima model achieves higher generation efficiency while maintaining or even better zero-shot task accuracy. Moreover, the effective reconstruction of multimodal reasoning processes with Heima Decoder validates both the robustness and interpretability of our approach.