DyPCL: Dynamic Phoneme-level Contrastive Learning for Dysarthric Speech Recognition
作者: Wonjun Lee, Solee Im, Heejin Do, Yunsu Kim, Jungseul Ok, Gary Geunbae Lee
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-01-31 (更新: 2025-02-03)
备注: NAACL 2025 main conference, 9pages, 1 page appendix
💡 一句话要点
提出动态音素级对比学习(DyPCL)用于提升构音障碍语音识别性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 构音障碍语音识别 对比学习 音素级别 动态课程学习 语音表征学习
📋 核心要点
- 构音障碍语音识别面临严重挑战,现有方法难以有效处理语音严重程度和说话人差异。
- DyPCL通过动态音素级对比学习,聚焦语音的细微差别,并利用动态课程学习提升模型对难区分语音的识别能力。
- 实验结果表明,DyPCL在UASpeech数据集上显著降低了词错误率,验证了其在构音障碍语音识别方面的有效性。
📝 摘要(中文)
构音障碍语音识别常因构音障碍程度的内在多样性和与正常语音的外在差异而导致性能下降。为了弥合这些差距,我们提出了一种动态音素级对比学习(DyPCL)方法,旨在获得跨不同说话人的不变表示。我们利用动态连接时序分类对齐将语音分解为音素片段,以进行音素级对比学习。与侧重于语句级嵌入的先前研究不同,我们细粒度的学习能够区分语音的细微部分。此外,我们引入了动态课程学习,基于音素的语音相似性,逐步从简单的负样本过渡到难以区分的负样本。我们通过难度级别进行训练的方法减轻了说话人固有的可变性,更好地识别具有挑战性的语音。在UASpeech数据集上的评估表明,DyPCL优于基线模型,在整个构音障碍组中,词错误率(WER)平均相对降低了22.10%。
🔬 方法详解
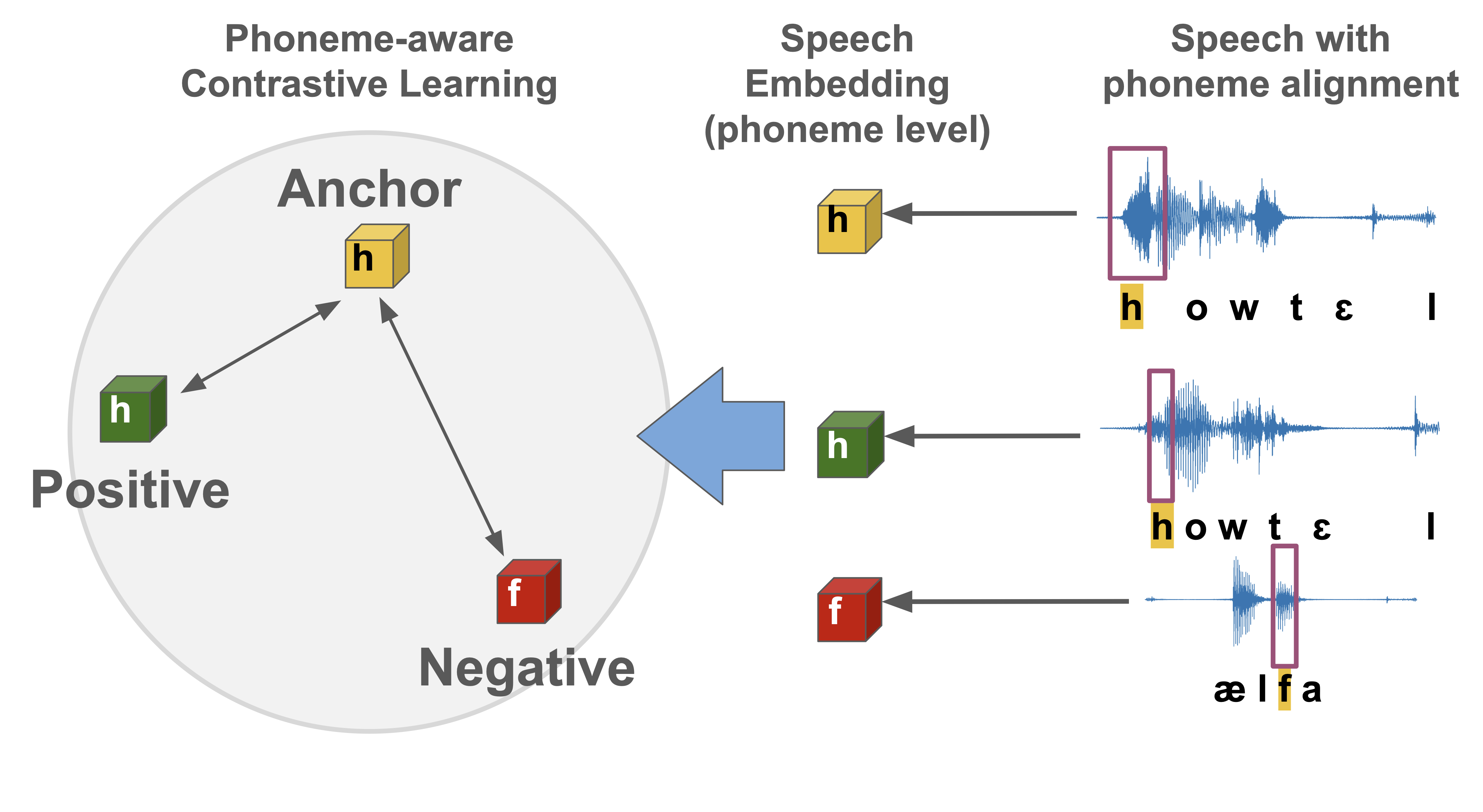
问题定义:构音障碍语音识别的性能受到构音障碍程度差异和与正常语音差异的双重影响。现有方法难以有效应对这些挑战,导致识别准确率下降。特别是,语句级别的嵌入方法忽略了语音中细微的音素级别的差异,限制了模型的区分能力。
核心思路:论文的核心思路是利用音素级别的对比学习,更精细地捕捉语音的特征。通过将语音分解为音素片段,并进行对比学习,模型能够学习到更具区分性的表示,从而提高对构音障碍语音的识别能力。此外,动态课程学习的引入,使得模型能够逐步学习,从易到难,更好地适应不同程度的构音障碍语音。
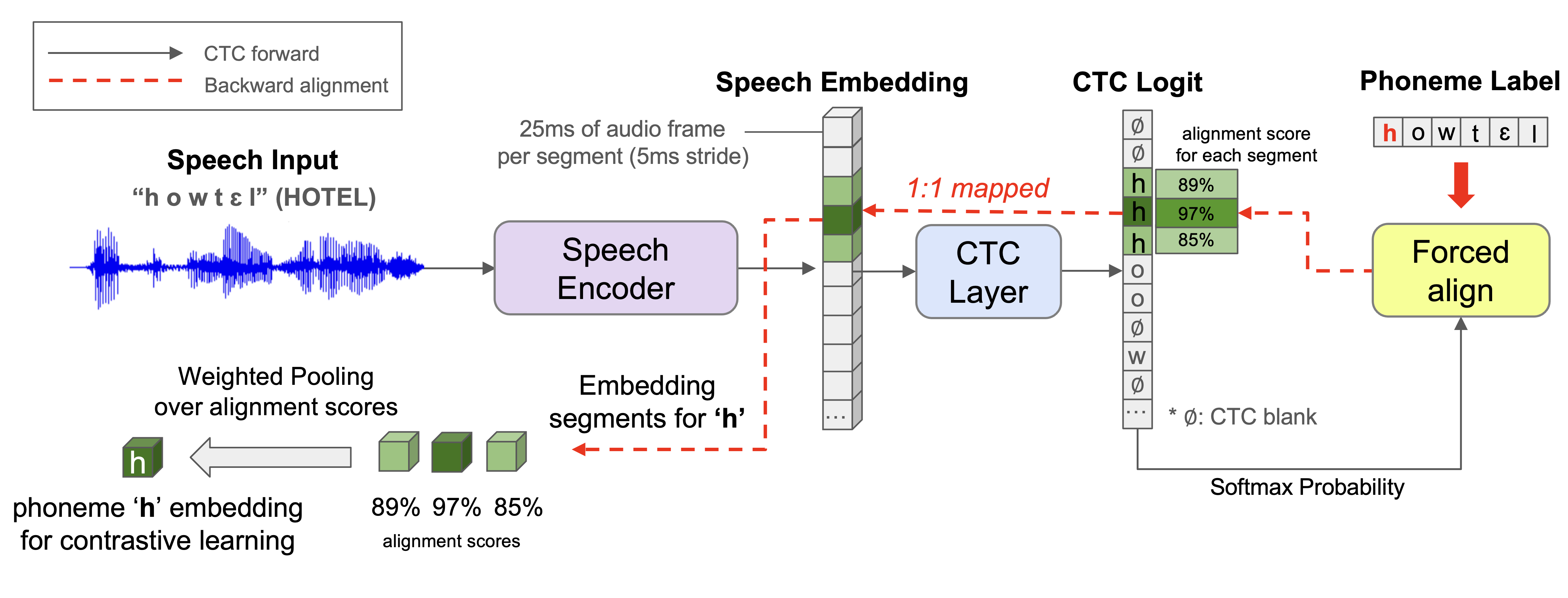
技术框架:DyPCL方法主要包含以下几个阶段:1) 语音分解:利用动态连接时序分类(CTC)对齐将语音分解为音素片段。2) 音素级对比学习:对每个音素片段进行嵌入表示,并通过对比学习损失函数,使得相似的音素片段在嵌入空间中更接近,不同的音素片段更远离。3) 动态课程学习:根据音素的语音相似性,动态调整负样本的难度,使得模型能够逐步学习,提高对难区分语音的识别能力。
关键创新:该方法最重要的创新点在于将对比学习应用到音素级别,并结合动态课程学习。与以往的语句级别对比学习相比,音素级别的对比学习能够更精细地捕捉语音的特征,提高模型的区分能力。动态课程学习则使得模型能够更好地适应不同程度的构音障碍语音,提高模型的泛化能力。
关键设计:在音素级对比学习中,使用了InfoNCE损失函数,用于最大化正样本之间的相似性,最小化负样本之间的相似性。动态课程学习中,使用了基于音素语音相似性的难度评估方法,并根据难度动态调整负样本的选择。具体的网络结构使用了常见的语音识别模型,例如Transformer或LSTM,并在此基础上进行了修改,以适应音素级别的对比学习。
🖼️ 关键图片

📊 实验亮点
DyPCL在UASpeech数据集上进行了评估,实验结果表明,该方法显著优于基线模型,在整个构音障碍组中,词错误率(WER)平均相对降低了22.10%。这一结果表明,DyPCL能够有效提高构音障碍语音识别的准确率,具有重要的实际应用价值。
🎯 应用场景
该研究成果可应用于辅助构音障碍患者的交流,例如开发更准确的语音输入系统、语音治疗工具等。通过提高构音障碍语音识别的准确率,可以帮助患者更方便地使用语音技术,改善生活质量。未来,该技术还可扩展到其他语音障碍的识别与辅助。
📄 摘要(原文)
Dysarthric speech recognition often suffers from performance degradation due to the intrinsic diversity of dysarthric severity and extrinsic disparity from normal speech. To bridge these gaps, we propose a Dynamic Phoneme-level Contrastive Learning (DyPCL) method, which leads to obtaining invariant representations across diverse speakers. We decompose the speech utterance into phoneme segments for phoneme-level contrastive learning, leveraging dynamic connectionist temporal classification alignment. Unlike prior studies focusing on utterance-level embeddings, our granular learning allows discrimination of subtle parts of speech. In addition, we introduce dynamic curriculum learning, which progressively transitions from easy negative samples to difficult-to-distinguishable negative samples based on phonetic similarity of phoneme. Our approach to training by difficulty levels alleviates the inherent variability of speakers, better identifying challenging speeches. Evaluated on the UASpeech dataset, DyPCL outperforms baseline models, achieving an average 22.10\% relative reduction in word error rate (WER) across the overall dysarthria group.