Large Language Models with Temporal Reasoning for Longitudinal Clinical Summarization and Prediction
作者: Maya Kruse, Shiyue Hu, Nicholas Derby, Yifu Wu, Samantha Stonbraker, Bingsheng Yao, Dakuo Wang, Elizabeth Goldberg, Yanjun Gao
分类: cs.CL
发布日期: 2025-01-30 (更新: 2025-09-04)
💡 一句话要点
评估LLM在纵向临床数据上的时序推理能力,用于病历总结和诊断预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 临床文本总结 电子病历 时间推理 检索增强生成 思维链 诊断预测
📋 核心要点
- 现有临床文本总结方法难以处理跨时间分布的多模态数据和长患者轨迹。
- 本文评估了LLM及其RAG变体和CoT提示在长文本临床总结和预测中的时序推理能力。
- 实验表明,长上下文窗口能改善输入整合,但不能持续增强临床推理,LLM在时序推理和罕见病预测方面仍有挑战。
📝 摘要(中文)
本文系统性地评估了多个最先进的开源大型语言模型(LLM)及其检索增强生成(RAG)变体和思维链(CoT)提示在长文本临床总结和预测方面的能力。研究考察了它们在整合结构化和非结构化电子病历(EHR)数据,并进行时间连贯性推理的能力,通过重新设计现有任务,包括来自两个公开EHR数据集的出院总结和诊断预测。结果表明,长上下文窗口改善了输入整合,但并未持续增强临床推理,并且LLM在时间进展和罕见疾病预测方面仍然存在困难。虽然RAG在某些情况下显示出幻觉方面的改进,但并未完全解决这些限制。这项工作填补了长临床文本总结方面的空白,为评估具有多模态数据和时间推理的LLM奠定了基础。
🔬 方法详解
问题定义:论文旨在解决利用大型语言模型(LLM)进行纵向临床数据(例如电子病历EHR)的总结和预测的问题。现有方法,特别是传统的LLM,在处理长上下文、多模态数据以及进行时间推理方面存在局限性,导致无法准确捕捉患者病程发展和进行有效预测。现有的LLM在处理临床数据时,容易出现幻觉问题,即生成不真实或与原始数据不符的信息。
核心思路:论文的核心思路是系统性地评估现有开源LLM在处理长上下文临床数据时的能力,并探索检索增强生成(RAG)和思维链(CoT)提示等技术是否能够提升LLM在临床总结和预测任务中的表现。通过重新设计现有的临床任务,并关注LLM在时间推理和罕见疾病预测方面的表现,从而更全面地了解LLM在临床应用中的潜力和局限性。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据准备:使用公开的EHR数据集,包括结构化和非结构化数据。2) 模型选择:选择多个最先进的开源LLM,例如(具体模型名称未知)。3) 任务设计:重新设计出院总结和诊断预测等临床任务,并特别关注需要时间推理的场景。4) 方法应用:应用RAG和CoT提示等技术来增强LLM的能力。5) 评估:使用合适的指标评估LLM在各个任务上的表现,并分析其在时间推理和罕见疾病预测方面的优劣。
关键创新:论文的关键创新在于对LLM在纵向临床数据处理能力进行系统性评估,并深入研究了长上下文窗口、RAG和CoT提示等技术对LLM性能的影响。此外,论文还特别关注了LLM在时间推理和罕见疾病预测方面的表现,这在以往的研究中较少被关注。通过这种全面的评估,论文为LLM在临床应用中的进一步研究和开发提供了有价值的参考。
关键设计:论文的关键设计包括:1) 长上下文窗口:探索不同长度的上下文窗口对LLM性能的影响。2) RAG:使用检索增强生成技术,从外部知识库中检索相关信息,以减少LLM的幻觉问题。3) CoT提示:使用思维链提示,引导LLM进行逐步推理,以提高其在复杂任务中的表现。4) 评估指标:使用合适的评估指标,例如ROUGE和准确率,来评估LLM在各个任务上的表现。(更详细的参数设置、损失函数、网络结构等技术细节未知)
🖼️ 关键图片

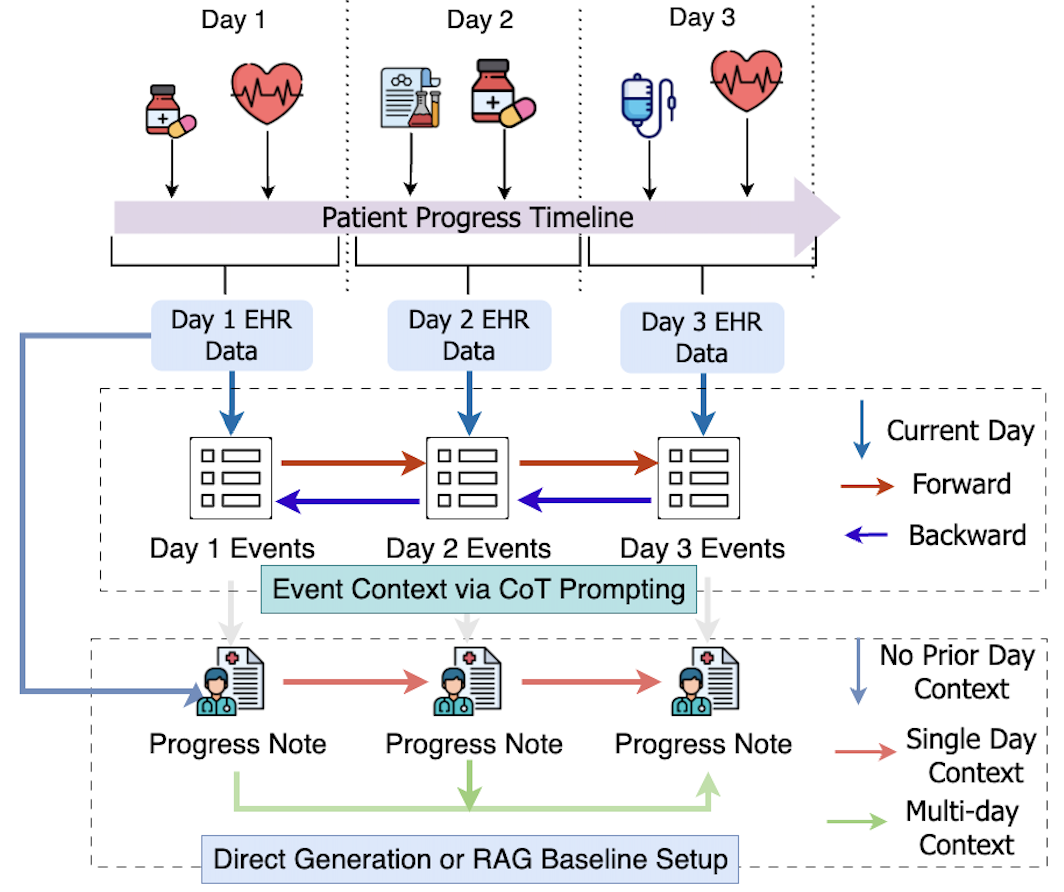
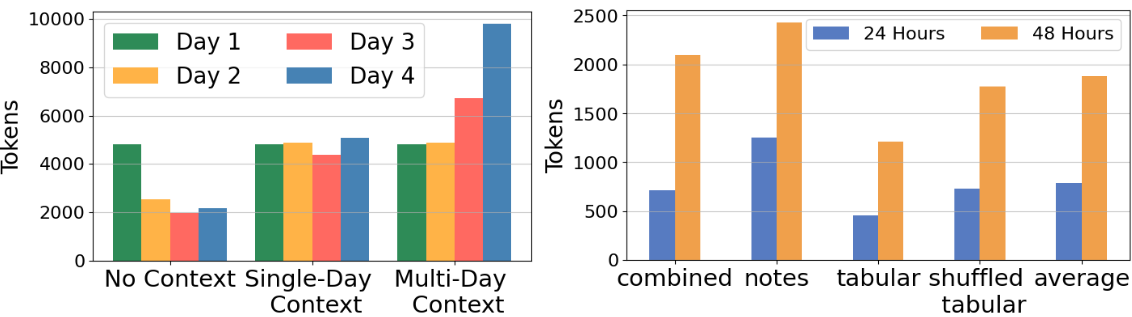
📊 实验亮点
实验结果表明,长上下文窗口虽然能改善输入整合,但并未持续增强临床推理能力。LLM在时间进展和罕见疾病预测方面仍面临挑战。RAG在某些情况下能减少幻觉,但不能完全解决问题。这些发现为未来LLM在临床应用中的研究方向提供了重要启示,例如需要更有效的时序建模方法和更可靠的知识检索机制。
🎯 应用场景
该研究成果可应用于智能临床决策支持系统、自动病历摘要生成、疾病风险预测等领域。通过提升LLM在处理纵向临床数据方面的能力,可以帮助医生更高效地获取患者信息、做出更准确的诊断,并改善患者的治疗效果。未来,该研究可以扩展到其他医疗领域,例如药物研发和个性化治疗。
📄 摘要(原文)
Recent advances in large language models (LLMs) have shown potential in clinical text summarization, but their ability to handle long patient trajectories with multi-modal data spread across time remains underexplored. This study systematically evaluates several state-of-the-art open-source LLMs, their Retrieval Augmented Generation (RAG) variants and chain-of-thought (CoT) prompting on long-context clinical summarization and prediction. We examine their ability to synthesize structured and unstructured Electronic Health Records (EHR) data while reasoning over temporal coherence, by re-engineering existing tasks, including discharge summarization and diagnosis prediction from two publicly available EHR datasets. Our results indicate that long context windows improve input integration but do not consistently enhance clinical reasoning, and LLMs are still struggling with temporal progression and rare disease prediction. While RAG shows improvements in hallucination in some cases, it does not fully address these limitations. Our work fills the gap in long clinical text summarization, establishing a foundation for evaluating LLMs with multi-modal data and temporal reasoning.