Differentially Private Steering for Large Language Model Alignment
作者: Anmol Goel, Yaxi Hu, Iryna Gurevych, Amartya Sanyal
分类: cs.CL, cs.LG
发布日期: 2025-01-30 (更新: 2025-03-20)
备注: ICLR 2025 Camera Ready; Code: https://github.com/UKPLab/iclr2025-psa
💡 一句话要点
提出PSA算法,通过差分隐私指导LLM对齐,保护私有数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 差分隐私 激活编辑 模型对齐 隐私保护
📋 核心要点
- 现有激活编辑方法在处理来自私有数据集的演示时,存在泄露隐私信息的风险,缺乏隐私保护机制。
- 论文提出Private Steering for LLM Alignment (PSA)算法,通过差分隐私保证来编辑LLM激活,实现私有数据下的LLM对齐。
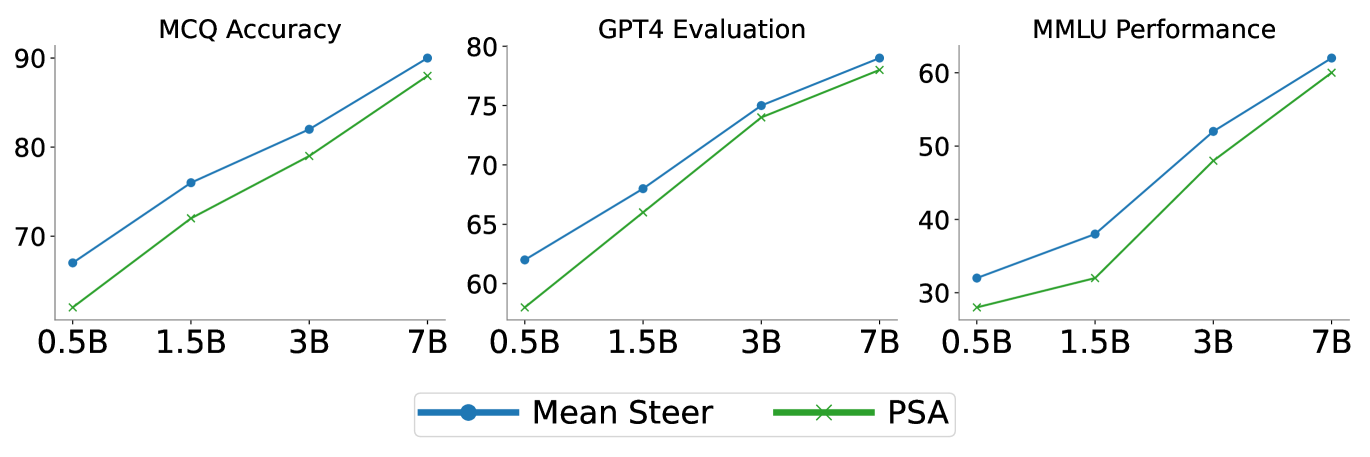
- 实验表明,PSA算法在保证差分隐私的同时,对LLM的对齐性能、文本生成质量和推理能力影响很小。
📝 摘要(中文)
将大型语言模型(LLM)与人类价值观对齐并避免不良行为(如幻觉)变得越来越重要。最近,通过激活编辑引导LLM朝向期望行为已成为一种有效的方法,可以在推理时缓解有害生成。激活编辑通过保留来自正面演示(例如,真实)的信息并最小化来自负面演示(例如,幻觉)的信息来修改LLM表示。当这些演示来自私有数据集时,对齐的LLM可能会泄露这些私有样本中包含的私有信息。本文首次研究了使用私有数据集对齐LLM行为的问题。我们提出了一种用于LLM对齐的私有指导(PSA)算法,该算法使用差分隐私(DP)保证来编辑LLM激活。我们在七个不同的基准测试中,使用不同大小(0.5B到7B)和模型系列(LlaMa、Qwen、Mistral和Gemma)的开源LLM进行了广泛的实验。结果表明,PSA在LLM对齐方面实现了DP保证,且性能损失最小,包括对齐指标、开放式文本生成质量和通用推理。我们还开发了第一个成员推理攻击(MIA),用于评估和审计通过激活编辑进行LLM指导的经验隐私。实验结果支持了理论保证,表明与几种现有的非私有技术相比,我们的PSA算法具有更好的保证。
🔬 方法详解
问题定义:论文旨在解决在利用私有数据集进行大型语言模型(LLM)对齐时,如何保护数据隐私的问题。现有的激活编辑方法虽然能够有效地引导LLM的行为,但当训练数据包含敏感信息时,对齐后的模型可能会泄露这些信息,缺乏有效的隐私保护机制。
核心思路:论文的核心思路是在激活编辑过程中引入差分隐私(DP)机制。通过在激活向量上添加噪声,使得模型学习到的信息具有一定的模糊性,从而防止模型记住或泄露训练数据中的个体信息。这样既能保证LLM的对齐效果,又能提供可证明的隐私保护。
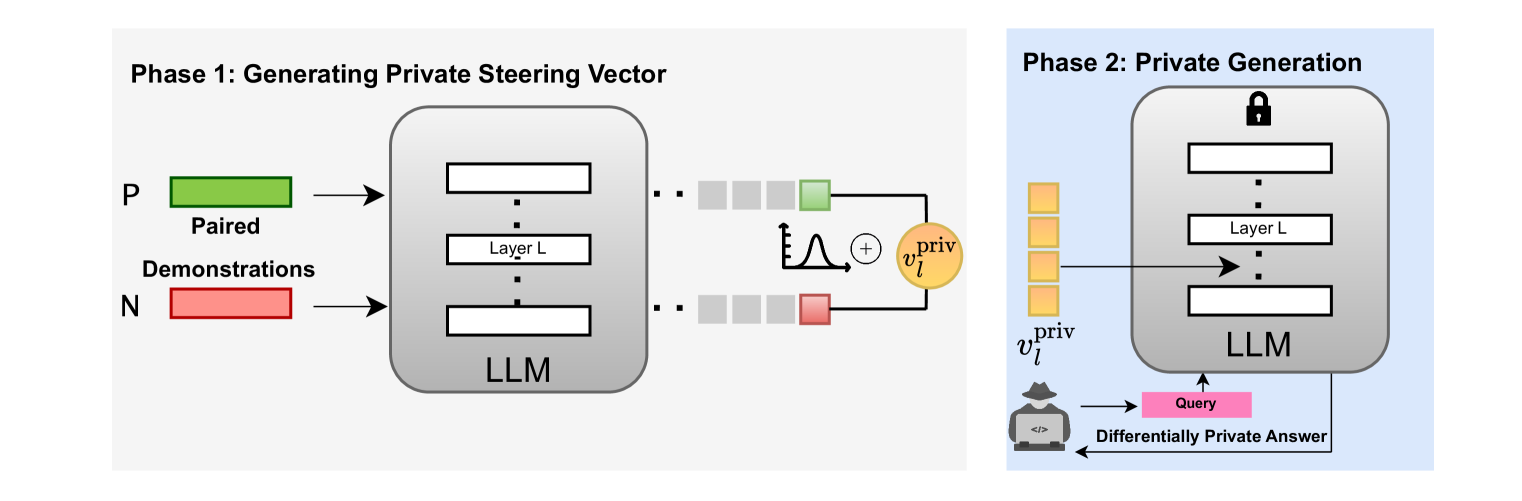
技术框架:PSA算法主要包含以下几个阶段:1) 从私有数据集中获取正负样本;2) 使用这些样本计算激活向量;3) 对激活向量添加满足差分隐私的噪声;4) 使用添加噪声后的激活向量进行激活编辑,从而引导LLM的行为。整体流程是在标准的激活编辑流程中,加入了差分隐私噪声添加步骤。
关键创新:论文的关键创新在于将差分隐私技术应用于LLM的激活编辑过程,提出了一种新的私有LLM对齐算法。这是首次在LLM指导领域考虑隐私保护问题,并提供了一种可行的解决方案。此外,论文还提出了针对LLM指导的成员推理攻击(MIA)方法,用于评估和审计模型的隐私泄露风险。
关键设计:PSA算法的关键设计在于如何选择合适的噪声添加机制,以在隐私保护和模型性能之间取得平衡。论文可能采用了高斯机制或其他差分隐私常用的噪声添加方法,并根据隐私预算(epsilon和delta)调整噪声的强度。具体的损失函数和网络结构与原始的激活编辑方法保持一致,主要修改在于激活向量的处理上。
🖼️ 关键图片
📊 实验亮点
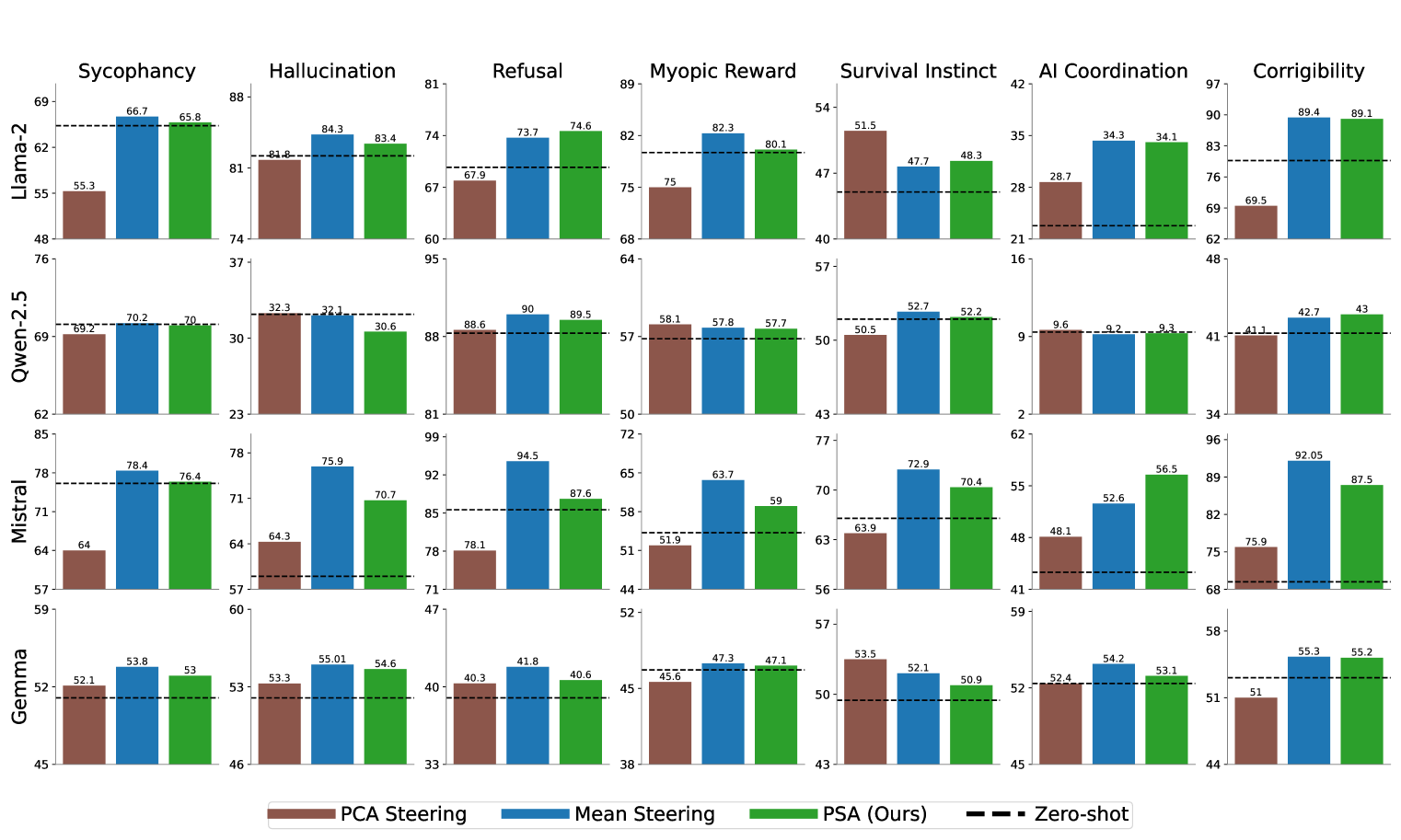
实验结果表明,PSA算法在多个基准测试中实现了差分隐私保证,同时对LLM的对齐性能影响很小。与非私有方法相比,PSA算法在保证隐私的前提下,仍然能够取得具有竞争力的性能。此外,成员推理攻击实验也验证了PSA算法的有效性,表明其能够有效降低模型的隐私泄露风险。
🎯 应用场景
该研究成果可应用于需要利用私有数据对齐大型语言模型的各种场景,例如医疗健康、金融服务等。在这些领域,数据隐私至关重要,PSA算法可以在保证数据安全的前提下,提升LLM的性能和可靠性。未来,该技术有望促进LLM在更多敏感领域的应用。
📄 摘要(原文)
Aligning Large Language Models (LLMs) with human values and away from undesirable behaviors (such as hallucination) has become increasingly important. Recently, steering LLMs towards a desired behavior via activation editing has emerged as an effective method to mitigate harmful generations at inference-time. Activation editing modifies LLM representations by preserving information from positive demonstrations (e.g., truthful) and minimising information from negative demonstrations (e.g., hallucinations). When these demonstrations come from a private dataset, the aligned LLM may leak private information contained in those private samples. In this work, we present the first study of aligning LLM behavior with private datasets. Our work proposes the Private Steering for LLM Alignment (PSA) algorithm to edit LLM activations with differential privacy (DP) guarantees. We conduct extensive experiments on seven different benchmarks with open-source LLMs of different sizes (0.5B to 7B) and model families (LlaMa, Qwen, Mistral and Gemma). Our results show that PSA achieves DP guarantees for LLM alignment with minimal loss in performance, including alignment metrics, open-ended text generation quality, and general-purpose reasoning. We also develop the first Membership Inference Attack (MIA) for evaluating and auditing the empirical privacy for the problem of LLM steering via activation editing. Our experiments support the theoretical guarantees by showing improved guarantees for our PSA algorithm compared to several existing non-private techniques.