Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
作者: Arthur Douillard, Yanislav Donchev, Keith Rush, Satyen Kale, Zachary Charles, Zachary Garrett, Gabriel Teston, Dave Lacey, Ross McIlroy, Jiajun Shen, Alexandre Ramé, Arthur Szlam, Marc'Aurelio Ranzato, Paul Barham
分类: cs.CL
发布日期: 2025-01-30
💡 一句话要点
提出流式DiLoCo算法,通过通信重叠显著降低分布式LLM训练的带宽需求。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式训练 大型语言模型 通信优化 参数同步 量化
📋 核心要点
- 现有分布式LLM训练方法受限于高带宽通信需求,限制了worker的地理分布和扩展性。
- 论文提出流式DiLoCo算法,通过参数子集同步、通信重叠和量化技术降低带宽需求。
- 实验表明,该方法在保持模型质量的同时,显著降低了训练所需的带宽,降低幅度达两个数量级。
📝 摘要(中文)
大型语言模型(LLM)的训练通常分布在大量的加速器上,以减少训练时间。由于内部状态和参数梯度需要在每个梯度步骤中进行交换,因此所有设备需要位于具有低延迟、高带宽通信链路的位置,以支持所需的大量交换比特。最近,像DiLoCo这样的分布式算法放宽了这种共址约束:加速器可以被分组为“worker”,worker之间的同步只不频繁地发生。这意味着worker可以使用较低带宽的通信链路,而不影响学习质量。然而,在这些方法中,worker之间的通信仍然需要与之前相同的峰值带宽,因为同步需要所有参数在所有worker之间交换。在本文中,我们通过三种方式改进了DiLoCo。首先,我们按顺序同步参数的子集,而不是一次性同步所有参数,这大大降低了峰值带宽。其次,我们允许worker在同步时继续训练,这减少了实际运行时间。第三,我们量化worker交换的数据,这进一步降低了worker之间的带宽。通过适当地组合这些修改,我们通过实验表明,我们可以分布式地训练数十亿规模的参数,并达到与之前相似的质量,但将所需的带宽降低了两个数量级。
🔬 方法详解
问题定义:现有分布式训练方法,如数据并行,需要频繁地在所有worker之间同步梯度或参数,这导致了对高带宽通信的强烈需求。尤其是在训练大型语言模型时,参数量巨大,同步开销成为瓶颈。DiLoCo等方法虽然减少了同步频率,但每次同步仍然需要传输所有参数,峰值带宽需求并未降低。
核心思路:论文的核心思路是通过将参数同步过程分解为多个小的、流式的同步操作,并允许worker在同步过程中继续训练,从而降低峰值带宽需求并隐藏通信延迟。此外,通过量化通信数据,进一步减少了数据传输量。
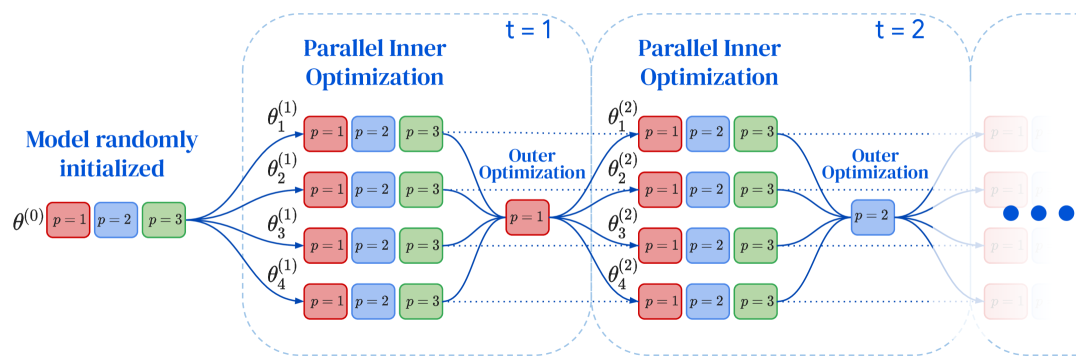
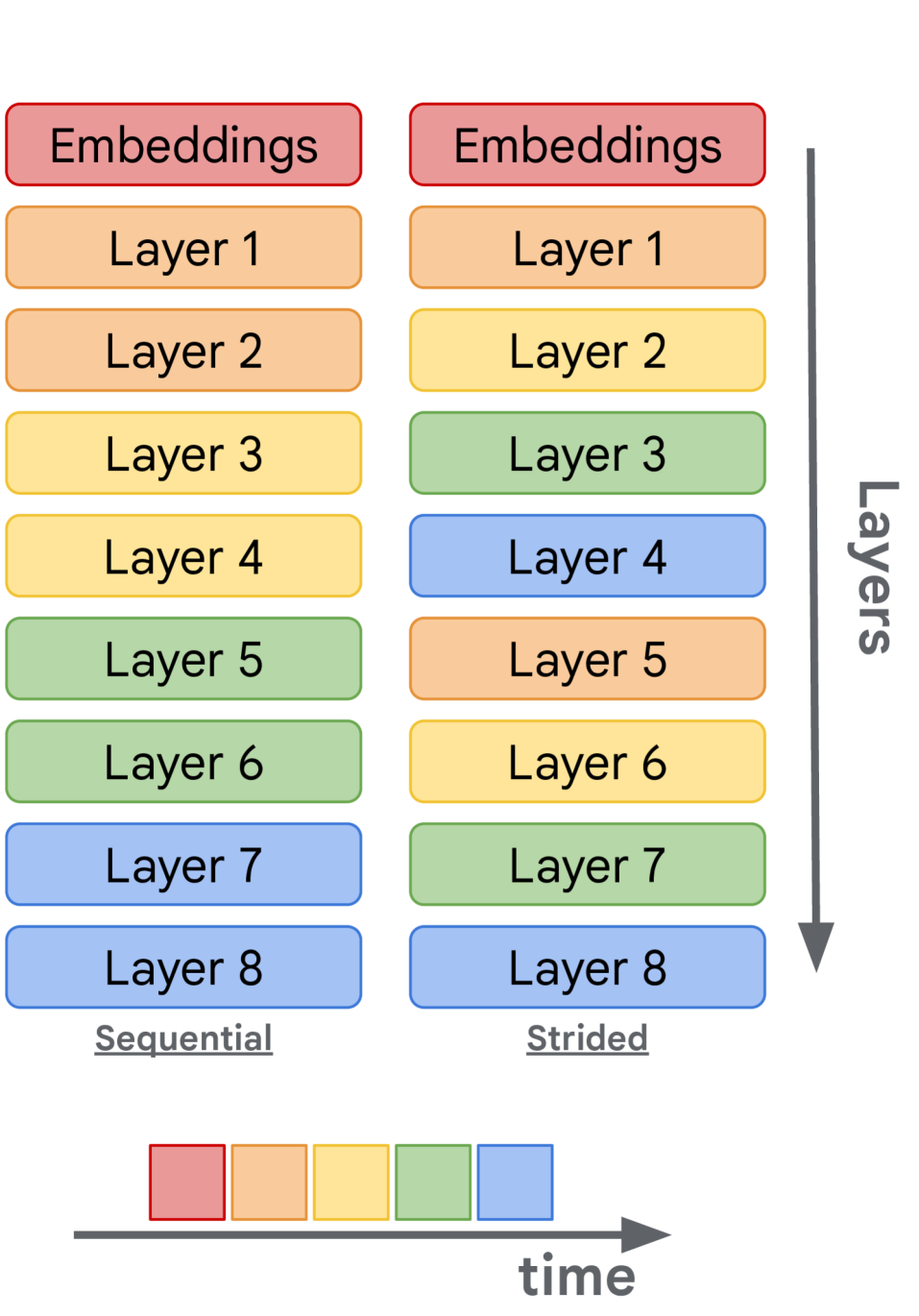
技术框架:流式DiLoCo算法在DiLoCo的基础上进行了改进。整体框架仍然是worker分组的分布式训练模式,但同步过程不再是全局同步,而是:1) 将参数划分为多个子集;2) 依次同步每个子集;3) 在同步某个子集的同时,其他worker可以继续使用旧参数进行训练。此外,在worker之间传输参数子集时,会对其进行量化。
关键创新:最重要的创新在于将全局同步分解为流式同步,并允许通信与计算重叠。这使得worker可以在同步过程中继续训练,有效隐藏了通信延迟,并显著降低了峰值带宽需求。量化也是一个重要的优化手段,进一步减少了通信量。
关键设计:关键设计包括:1) 参数子集的大小:需要平衡同步频率和每次同步的开销;2) 量化方案:选择合适的量化方法,以在降低带宽的同时,尽量减少对模型性能的影响;3) 通信与计算重叠的调度策略:需要合理安排通信和计算任务,以最大化资源利用率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,流式DiLoCo算法可以在训练数十亿参数规模的模型时,达到与原始DiLoCo算法相似的精度,但所需的通信带宽降低了两个数量级。这使得在低带宽环境下训练大型语言模型成为可能,具有重要的实际意义。
🎯 应用场景
该研究成果可应用于大规模分布式机器学习训练,尤其是在通信带宽受限的环境下,例如跨地域的数据中心或边缘计算场景。通过降低带宽需求,可以降低训练成本,并使得更大规模的模型训练成为可能。此外,该方法也有助于推动联邦学习等隐私保护机器学习技术的发展。
📄 摘要(原文)
Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.