Self-supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models
作者: Qika Lin, Tianzhe Zhao, Kai He, Zhen Peng, Fangzhi Xu, Ling Huang, Jingying Ma, Mengling Feng
分类: cs.CL, cs.AI
发布日期: 2025-01-30
💡 一句话要点
提出自监督量化表示SSQR,实现知识图谱与大语言模型的无缝集成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大语言模型 自监督学习 量化表示 指令跟随
📋 核心要点
- 现有方法难以有效整合知识图谱的结构信息与大语言模型,存在自然鸿沟。
- 提出自监督量化表示(SSQR)方法,将知识图谱压缩成离散代码,对齐语言模型输入格式。
- 实验表明,SSQR优于现有方法,微调后的LLaMA模型在知识图谱任务上表现更优,且token使用量更少。
📝 摘要(中文)
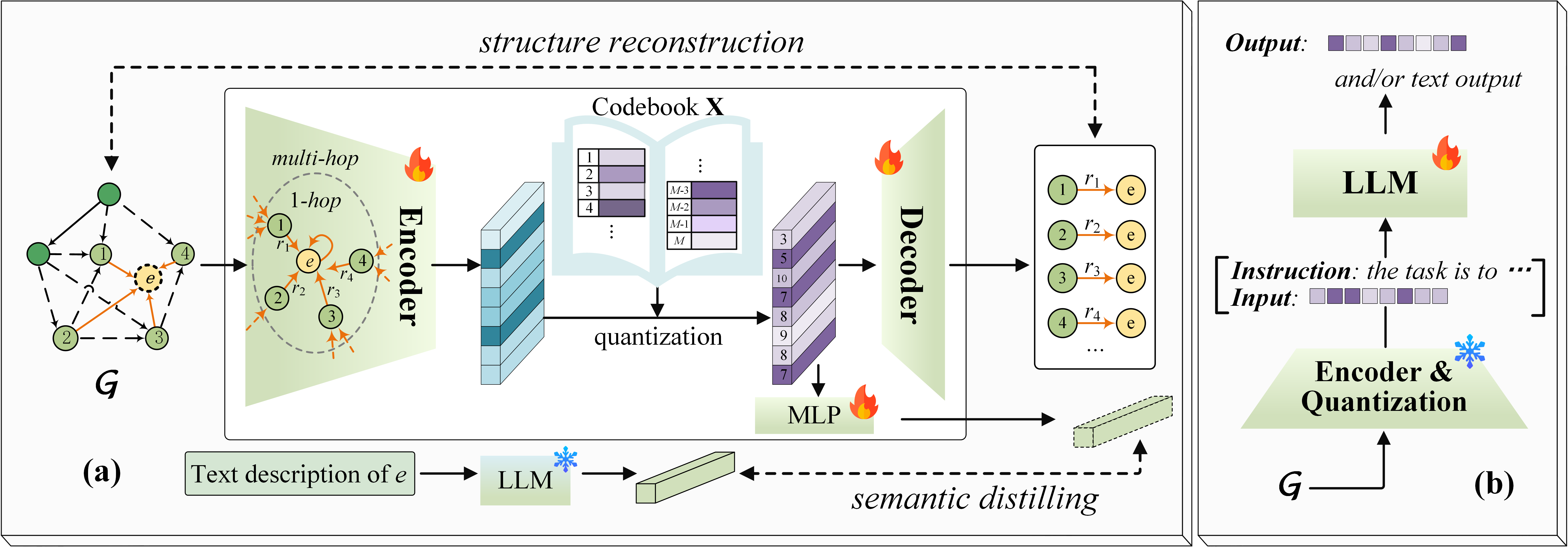
为了有效整合知识图谱(KG)的整体结构信息与大语言模型(LLM),本文提出了一种两阶段框架,旨在学习和应用每个实体的量化代码,从而实现KG与LLM的无缝集成。首先,提出了一种自监督量化表示(SSQR)方法,将KG的结构和语义知识压缩成离散代码(即tokens),使其与语言句子的格式对齐。其次,通过将这些学习到的代码视为特征直接输入到LLM,设计了KG指令跟随数据,从而实现无缝集成。实验结果表明,SSQR优于现有的无监督量化方法,产生了更易区分的代码。此外,微调后的LLaMA2和LLaMA3.1在KG链接预测和三元组分类任务上也表现出卓越的性能,每个实体仅使用16个tokens,而不是传统提示方法中的数千个。
🔬 方法详解
问题定义:现有方法在将知识图谱的结构化信息融入大语言模型时面临挑战,因为知识图谱的结构与自然语言的格式存在差异。传统的prompting方法需要大量的tokens来表示实体,效率较低,且难以捕捉知识图谱的整体结构信息。因此,需要一种方法能够将知识图谱的信息压缩成与语言模型兼容的格式,同时保持其结构和语义信息。
核心思路:本文的核心思路是通过自监督学习的方式,将知识图谱中的实体表示为离散的量化代码(tokens)。这些tokens能够捕捉实体的结构和语义信息,并且与语言模型的输入格式对齐。通过将这些tokens作为特征输入到语言模型中,可以实现知识图谱与语言模型的无缝集成。
技术框架:该框架包含两个主要阶段。第一阶段是自监督量化表示(SSQR)的学习,该阶段利用知识图谱的结构和语义信息,通过自监督学习的方式,将每个实体映射到一个离散的量化代码。第二阶段是知识图谱指令跟随数据的构建和语言模型的微调,该阶段将学习到的量化代码作为特征,构建知识图谱指令跟随数据,并使用这些数据对语言模型进行微调,使其能够更好地利用知识图谱的信息。
关键创新:该方法最重要的创新点在于提出了自监督量化表示(SSQR)方法,该方法能够将知识图谱的结构和语义信息压缩成离散的量化代码,从而实现知识图谱与语言模型的无缝集成。与现有的无监督量化方法相比,SSQR能够产生更易区分的代码,更好地捕捉知识图谱的信息。与传统的prompting方法相比,SSQR只需要少量的tokens即可表示实体,效率更高。
关键设计:SSQR方法使用对比学习的目标函数,鼓励相似的实体具有相似的量化代码,不相似的实体具有不同的量化代码。具体来说,该方法使用知识图谱的结构信息(例如,实体的邻居)和语义信息(例如,实体的描述)来定义实体的相似度。量化器的设计采用Gumbel-Softmax技巧,使得量化过程可微,从而可以使用梯度下降法进行优化。在构建知识图谱指令跟随数据时,将量化代码作为特征直接输入到语言模型中,避免了使用自然语言描述实体,从而减少了token的使用量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SSQR方法优于现有的无监督量化方法,产生了更易区分的代码。微调后的LLaMA2和LLaMA3.1在KG链接预测和三元组分类任务上也表现出卓越的性能,每个实体仅使用16个tokens,显著减少了token的使用量,同时提升了性能。
🎯 应用场景
该研究成果可应用于知识图谱增强的大语言模型,提升模型在知识密集型任务上的表现,例如问答系统、信息检索、推荐系统等。通过将知识图谱的结构化信息融入大语言模型,可以提高模型推理能力和知识覆盖面,从而更好地服务于实际应用。
📄 摘要(原文)
Due to the presence of the natural gap between Knowledge Graph (KG) structures and the natural language, the effective integration of holistic structural information of KGs with Large Language Models (LLMs) has emerged as a significant question. To this end, we propose a two-stage framework to learn and apply quantized codes for each entity, aiming for the seamless integration of KGs with LLMs. Firstly, a self-supervised quantized representation (SSQR) method is proposed to compress both KG structural and semantic knowledge into discrete codes (\ie, tokens) that align the format of language sentences. We further design KG instruction-following data by viewing these learned codes as features to directly input to LLMs, thereby achieving seamless integration. The experiment results demonstrate that SSQR outperforms existing unsupervised quantized methods, producing more distinguishable codes. Further, the fine-tuned LLaMA2 and LLaMA3.1 also have superior performance on KG link prediction and triple classification tasks, utilizing only 16 tokens per entity instead of thousands in conventional prompting methods.