Diverse Preference Optimization
作者: Jack Lanchantin, Angelica Chen, Shehzaad Dhuliawala, Ping Yu, Jason Weston, Sainbayar Sukhbaatar, Ilia Kulikov
分类: cs.CL
发布日期: 2025-01-30 (更新: 2025-05-22)
💡 一句话要点
提出Diverse Preference Optimization (DivPO),提升语言模型生成内容的多样性,同时保持生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好优化 多样性生成 语言模型 后训练 创造性任务
📋 核心要点
- 现有语言模型后训练方法降低了生成内容的多样性,限制了其在创造性任务中的应用。
- DivPO通过选择稀有但高质量的响应作为正例,常见但低质量的响应作为负例,来优化模型生成多样性。
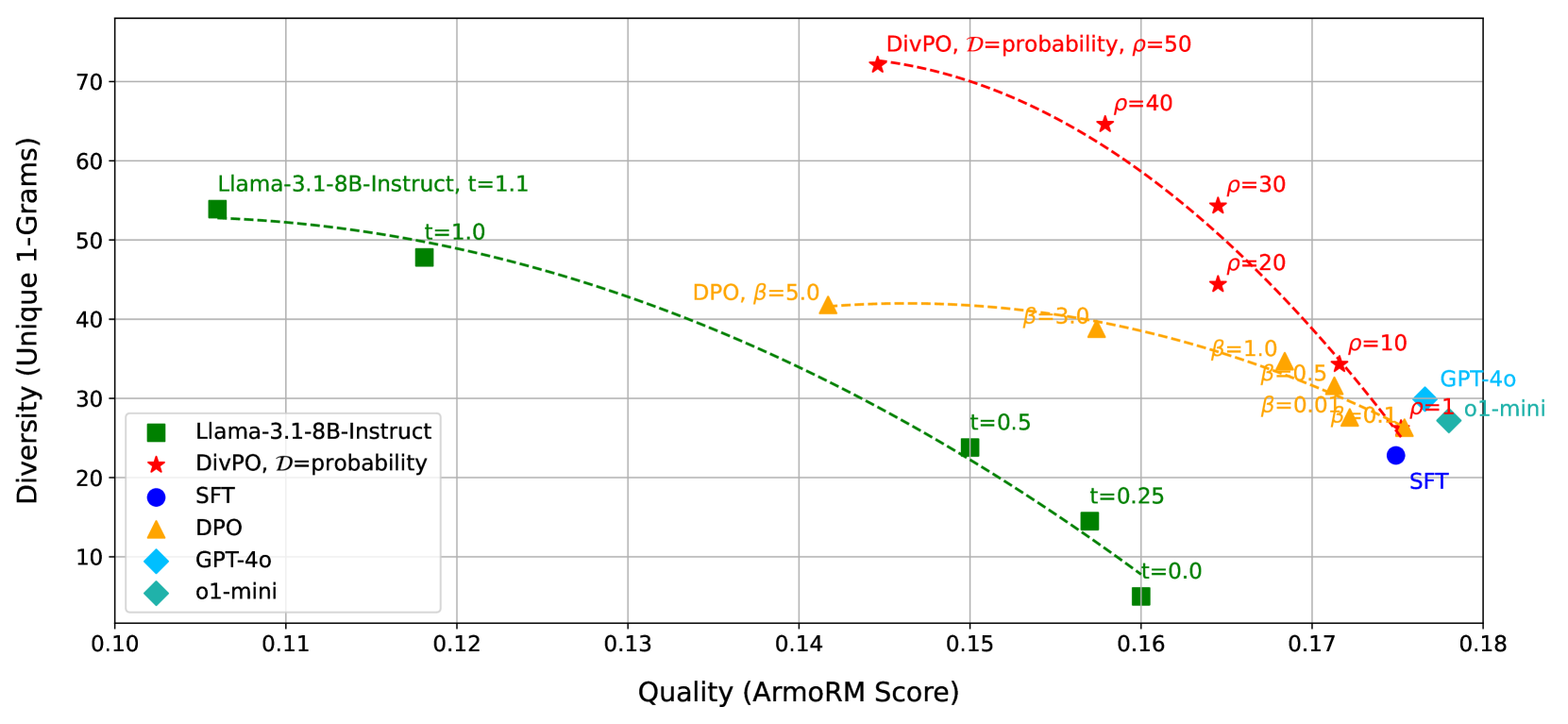
- 实验表明,DivPO在个性属性和故事生成方面显著提升了多样性,同时保持或提升了生成质量。
📝 摘要(中文)
语言模型的后训练,无论是通过强化学习、偏好优化还是监督微调,都倾向于锐化输出概率分布并降低生成响应的多样性。对于需要多样化响应的创造性生成任务来说,这是一个特别突出的问题。本文介绍了一种名为Diverse Preference Optimization (DivPO) 的优化方法,该方法学习生成比标准流程更多样化的响应,同时保持生成质量。在DivPO中,偏好对的选择首先考虑一个响应池,以及它们之间的多样性度量,然后选择被选中的样本作为更稀有但高质量的样本,而拒绝的样本是更常见但低质量的样本。DivPO在保持与标准基线相似的胜率的同时,生成了多45.6%的个性属性,故事多样性提高了74.6%。在通用指令跟随方面,与DPO相比,DivPO的多样性提高了46.2%,胜率提高了2.4%。
🔬 方法详解
问题定义:现有语言模型在经过强化学习、偏好优化或监督微调等后训练后,输出概率分布会变得更加集中,导致生成内容的多样性降低。这对于需要生成多样化结果的创造性任务(如故事生成、角色扮演等)来说是一个显著的瓶颈。现有的偏好优化方法难以兼顾生成质量和多样性。
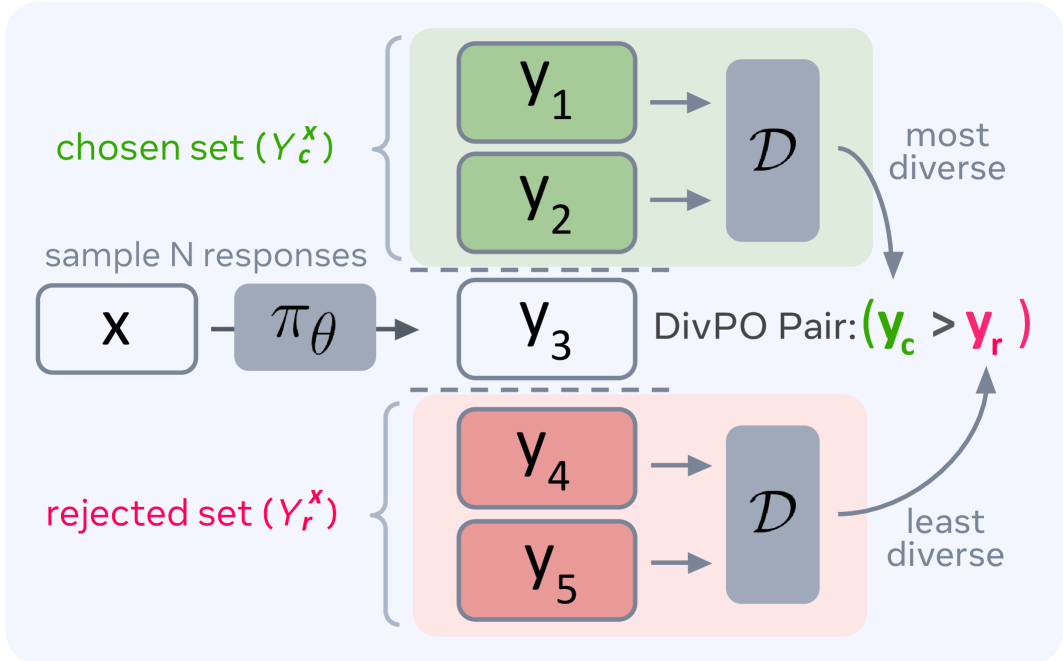
核心思路:DivPO的核心思路是利用多样性指标来指导偏好对的选择。它不是简单地选择整体质量最高的样本作为正例,而是倾向于选择在当前生成结果中相对稀有但质量尚可的样本作为正例,而选择常见的、低质量的样本作为负例。通过这种方式,鼓励模型探索更广阔的生成空间,从而提高生成内容的多样性。
技术框架:DivPO的整体框架基于标准的偏好优化流程,主要包含以下几个步骤:1) 从语言模型中生成一批候选响应;2) 计算候选响应之间的多样性度量(具体度量方式未知);3) 根据多样性度量和质量评估,选择偏好对(正例和负例);4) 使用选择的偏好对训练语言模型,目标是使模型更倾向于生成正例,避免生成负例。
关键创新:DivPO的关键创新在于偏好对的选择策略。传统的偏好优化方法通常只关注生成质量,而忽略了多样性。DivPO通过引入多样性指标,使得偏好对的选择能够同时考虑质量和多样性,从而有效地提升了生成内容的多样性。这种策略可以看作是对传统偏好优化方法的一种改进和扩展。
关键设计:DivPO的关键设计在于如何定义和计算多样性度量,以及如何将多样性度量融入到偏好对的选择过程中。论文中提到使用“稀有性”作为多样性的衡量标准,但具体的计算方法未知。此外,如何平衡质量和多样性之间的关系,也是一个需要仔细考虑的问题。损失函数的设计也至关重要,需要确保模型既能生成高质量的响应,又能保持较高的多样性。
🖼️ 关键图片
📊 实验亮点
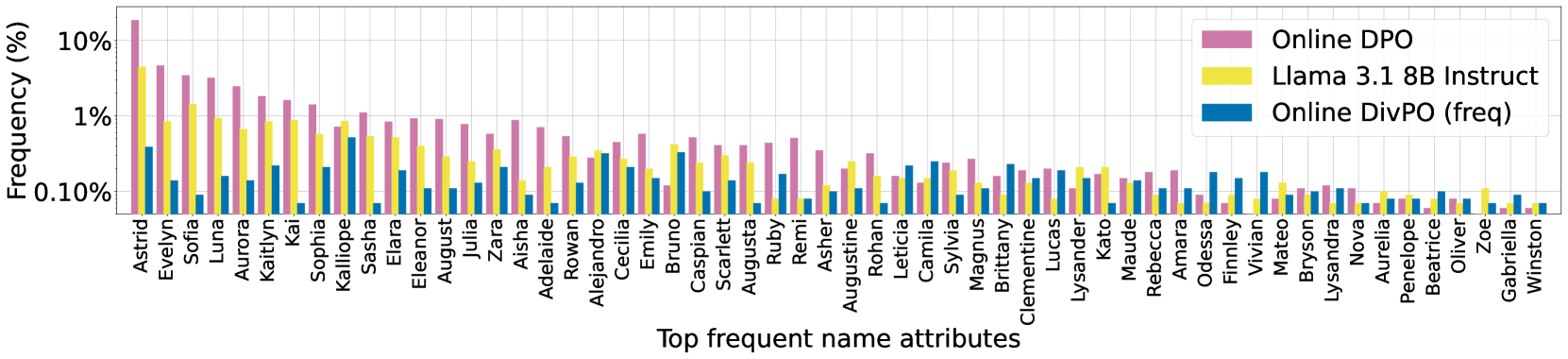
DivPO在个性属性生成任务中,生成了多45.6%的个性属性,故事多样性提高了74.6%,同时保持了与标准基线相似的胜率。在通用指令跟随任务中,DivPO的多样性提高了46.2%,胜率提高了2.4%(与DPO相比)。这些结果表明,DivPO能够在显著提升生成多样性的同时,保持甚至提升生成质量。
🎯 应用场景
DivPO可应用于各种需要生成多样化内容的场景,例如故事生成、角色扮演、对话系统、创意写作辅助等。通过提升生成内容的多样性,可以提高用户体验,激发用户创造力,并为语言模型在创意领域的应用开辟新的可能性。该方法还可能应用于数据增强,通过生成更多样化的数据来提升模型的泛化能力。
📄 摘要(原文)
Post-training of language models, either through reinforcement learning, preference optimization or supervised finetuning, tends to sharpen the output probability distribution and reduce the diversity of generated responses. This is particularly a problem for creative generative tasks where varied responses are desired. In this work we introduce Diverse Preference Optimization (DivPO), an optimization method which learns to generate much more diverse responses than standard pipelines, while maintaining the quality of the generations. In DivPO, preference pairs are selected by first considering a pool of responses, and a measure of diversity among them, and selecting chosen examples as being more rare but high quality, while rejected examples are more common, but low quality. DivPO results in generating 45.6% more diverse persona attributes, and a 74.6% increase in story diversity, while maintaining similar win rates as standard baselines. On general instruction following, DivPO results in a 46.2% increase in diversity, and a 2.4% winrate improvement compared to DPO.