Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation
作者: Yibo Wang, Tiansheng Huang, Li Shen, Huanjin Yao, Haotian Luo, Rui Liu, Naiqiang Tan, Jiaxing Huang, Dacheng Tao
分类: cs.CL, cs.AI
发布日期: 2025-01-30 (更新: 2026-01-16)
备注: Accepted by NeruIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Panacea:通过后微调扰动缓解大型语言模型的有害微调攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 有害微调攻击 安全对齐 自适应扰动 后微调处理
📋 核心要点
- 现有防御方法难以抵抗有害微调攻击,模型经过少量微调后仍可能学习有害知识,安全性不足。
- Panacea的核心思想是在微调后对模型施加自适应扰动,以恢复模型的安全对齐,同时避免性能下降。
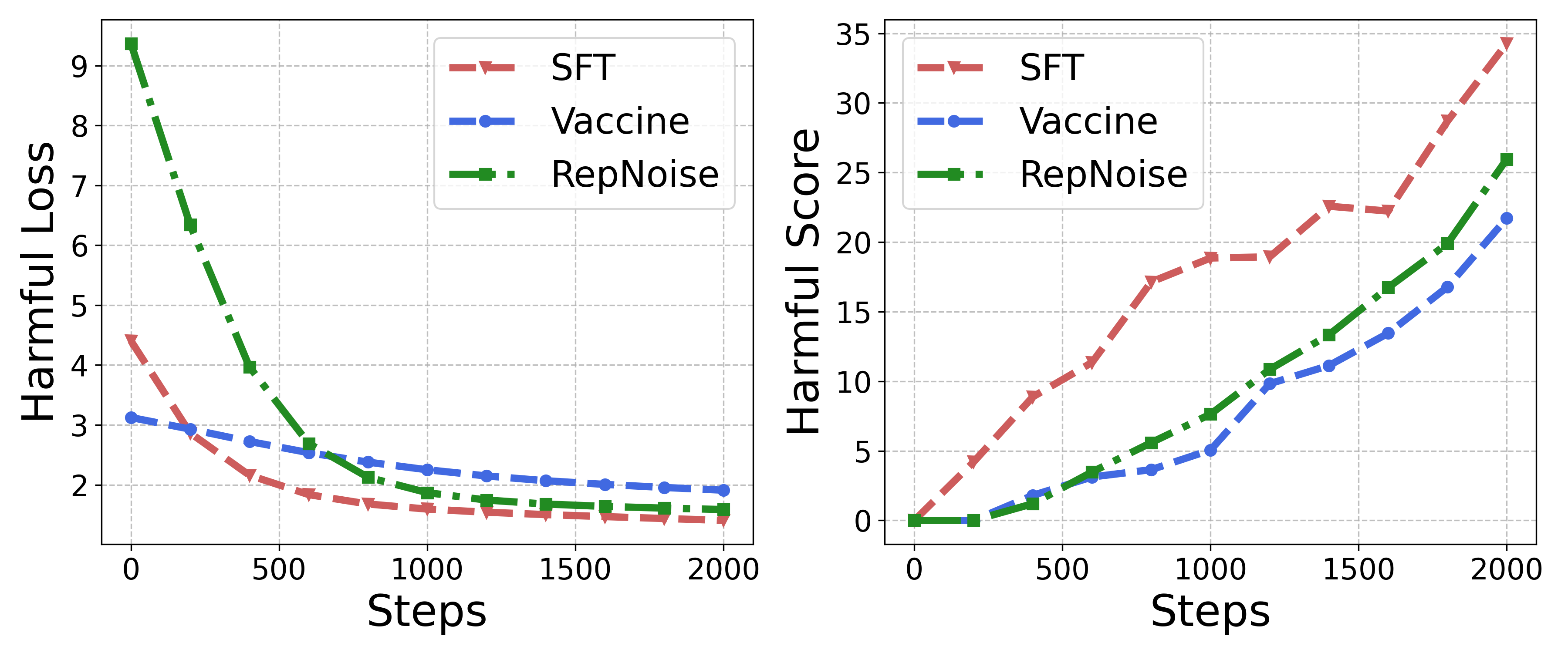
- 实验表明,Panacea能有效降低有害分数高达21.2%,同时保持微调性能,优于现有防御方法。
📝 摘要(中文)
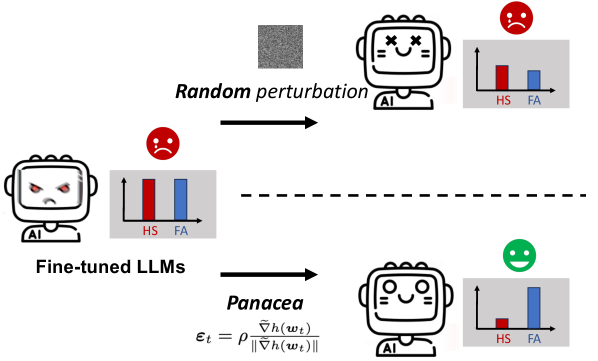
有害微调攻击给微调服务带来了严重的安全风险。主流防御方法旨在“免疫”模型,降低后续有害微调攻击的有效性。然而,我们的评估结果表明,这些防御措施是脆弱的——只需少量微调步骤,模型仍然可以学习到有害知识。为此,我们进一步实验发现,一个非常简单的解决方案——向微调后的模型添加纯随机扰动,可以使模型从有害行为中恢复,尽管这会导致模型微调性能的下降。为了解决微调性能下降的问题,我们进一步提出了Panacea,它优化了一种自适应扰动,该扰动将在微调后应用于模型。Panacea在不影响下游微调性能的情况下,保持了模型的安全对齐性能。在不同的有害比例、微调任务和主流LLM上进行了全面的实验,平均有害分数降低了高达21.2%,同时保持了微调性能。作为一个副产品,我们分析了自适应扰动,并表明各种LLM中的不同层具有不同的安全亲和力,这与之前的一些研究结果相吻合。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在微调过程中遭受恶意攻击的问题。现有的防御方法,如模型免疫,虽然试图阻止有害知识的注入,但往往无法抵抗持续的微调攻击,模型仍然可能学习到有害内容。因此,如何在保证模型安全性的前提下,使其能够正常进行微调,是一个重要的挑战。
核心思路:Panacea的核心思路是在微调之后,通过对模型参数施加一种精心设计的自适应扰动,来消除或减轻有害微调带来的负面影响。这种扰动不是随机的,而是通过优化算法学习得到的,目的是在不影响模型原有性能的前提下,使其对有害内容产生抵抗力。
技术框架:Panacea的整体框架可以分为三个阶段:1) 正常微调阶段:使用包含有害数据的微调数据集对LLM进行微调。2) 扰动优化阶段:设计一个优化目标,该目标旨在最小化有害内容的影响,同时保持模型在下游任务上的性能。使用验证集来优化扰动。3) 扰动应用阶段:将优化后的自适应扰动添加到微调后的模型参数中,得到最终的安全模型。
关键创新:Panacea的关键创新在于提出了自适应扰动的概念,并设计了一种优化算法来学习这种扰动。与简单的随机扰动相比,自适应扰动能够更有效地消除有害影响,同时避免对模型性能造成过大的损害。此外,论文还分析了不同层对安全性的影响,为未来的研究提供了新的视角。
关键设计:Panacea的关键设计包括:1) 扰动的表示方式:扰动可以表示为与模型参数相同维度的向量。2) 优化目标:优化目标通常包含两部分:一部分是衡量模型安全性的指标(例如,有害内容生成概率),另一部分是衡量模型性能的指标(例如,在下游任务上的准确率)。3) 优化算法:可以使用梯度下降等优化算法来学习扰动。4) 扰动应用方式:将学习到的扰动添加到模型参数中,可以使用简单的加法或者更复杂的变换。
🖼️ 关键图片
📊 实验亮点
Panacea在不同有害比例、微调任务和主流LLM上进行了全面的实验,结果表明,Panacea能够显著降低模型的有害分数,平均降幅高达21.2%,同时保持了微调性能。这表明Panacea是一种有效的防御有害微调攻击的方法,优于现有的随机扰动方法。此外,论文还分析了不同层对安全性的影响,为未来的研究提供了新的视角。
🎯 应用场景
Panacea可应用于各种需要对大型语言模型进行微调的场景,尤其是在数据来源不可靠或存在潜在恶意攻击风险的情况下。例如,在金融、医疗等敏感领域,可以利用Panacea来确保模型在微调后不会产生有害或不安全的行为。该研究有助于提升AI系统的安全性和可靠性,促进其在更广泛领域的应用。
📄 摘要(原文)
Harmful fine-tuning attack introduces significant security risks to the fine-tuning services. Main-stream defenses aim to vaccinate the model such that the later harmful fine-tuning attack is less effective. However, our evaluation results show that such defenses are fragile--with a few fine-tuning steps, the model still can learn the harmful knowledge. To this end, we do further experiment and find that an embarrassingly simple solution--adding purely random perturbations to the fine-tuned model, can recover the model from harmful behaviors, though it leads to a degradation in the model's fine-tuning performance. To address the degradation of fine-tuning performance, we further propose Panacea, which optimizes an adaptive perturbation that will be applied to the model after fine-tuning. Panacea maintains model's safety alignment performance without compromising downstream fine-tuning performance. Comprehensive experiments are conducted on different harmful ratios, fine-tuning tasks and mainstream LLMs, where the average harmful scores are reduced by up-to 21.2%, while maintaining fine-tuning performance. As a by-product, we analyze the adaptive perturbation and show that different layers in various LLMs have distinct safety affinity, which coincide with finding from several previous study. Source code available at https://github.com/w-yibo/Panacea.