InnerThoughts: Disentangling Representations and Predictions in Large Language Models
作者: Didier Chételat, Joseph Cotnareanu, Rylee Thompson, Yingxue Zhang, Mark Coates
分类: cs.CL, cs.LG
发布日期: 2025-01-29
备注: Accepted at AISTATS 2025
💡 一句话要点
InnerThoughts:解耦大语言模型中的表征与预测能力,提升问答性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 表征学习 预测模块 知识问答 解耦 Transformer 多项选择
📋 核心要点
- 现有LLM通常仅使用最后一层隐藏状态进行预测,忽略了中间层蕴含的丰富表征信息。
- 本文提出InnerThoughts框架,通过学习独立的预测模块,利用所有层的隐藏状态进行预测,解耦表征与预测。
- 实验表明,该方法在多个困难基准测试中显著提升性能,计算成本远低于监督微调。
📝 摘要(中文)
大型语言模型(LLM)蕴含着丰富的知识,通常通过多项选择问答提示来激发这些知识。模型内部通过多个Transformer层处理提示,并在隐藏状态中构建问题的不同表征。然而,通常只有最后一层和token位置的隐藏状态被用于预测答案标签。本文提出了一种方法,在训练问题集上学习一个小的、独立的神经网络预测模块,该模块以所有层在最后一个时间步的隐藏状态作为输入,并输出预测结果。实际上,这种框架将LLM的表征能力与其预测能力解耦。在多个具有挑战性的基准测试中,我们的方法取得了显著的性能提升,有时可与监督微调程序相媲美,但计算成本却大大降低。
🔬 方法详解
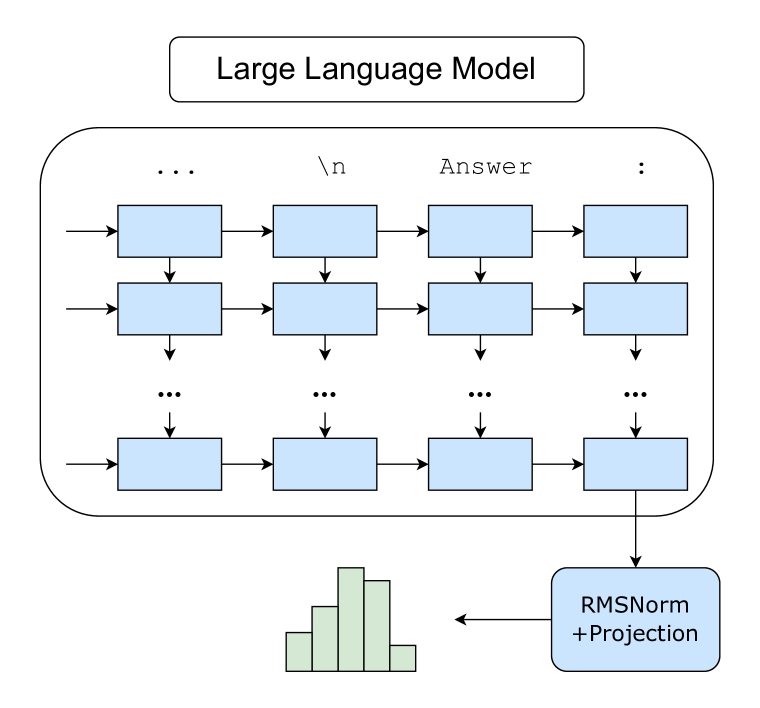
问题定义:现有的大语言模型在进行多项选择问答时,通常只利用最后一层Transformer的隐藏状态进行预测,而忽略了模型中间层所学习到的丰富表征信息。这种做法可能导致信息损失,限制了模型的性能。现有方法,如微调,计算成本高昂,且可能过度拟合。
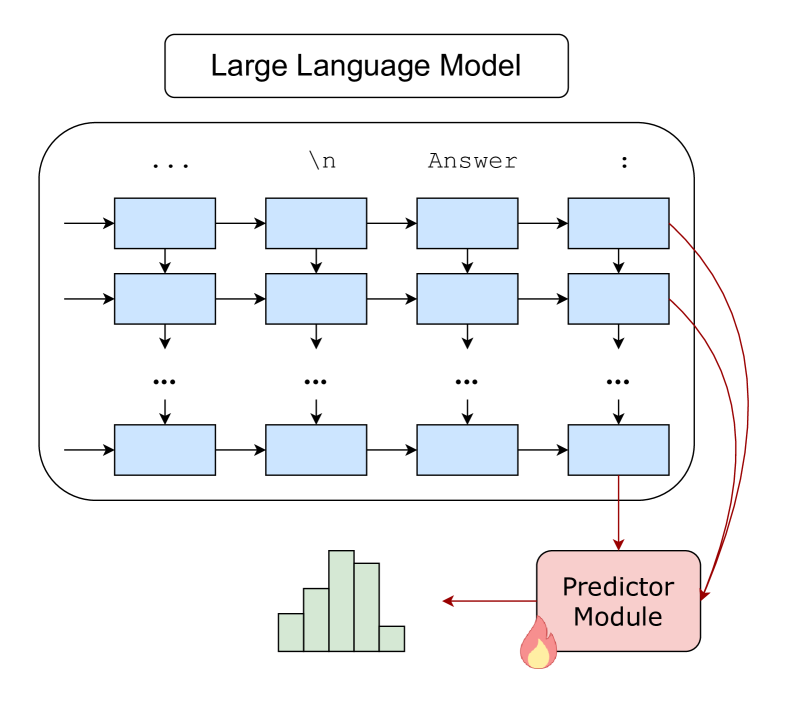
核心思路:本文的核心思路是将大语言模型的表征能力和预测能力解耦。具体来说,就是不再直接使用LLM最后一层的输出进行预测,而是训练一个独立的预测模块,该模块以LLM所有层的隐藏状态作为输入,学习如何利用这些表征进行预测。这样可以更充分地利用LLM学习到的信息,并提高预测的准确性。
技术框架:InnerThoughts框架包含两个主要部分:预训练的大语言模型和独立的预测模块。首先,使用标准的多项选择问答提示,将问题输入到预训练的LLM中。然后,提取LLM每一层在最后一个token位置的隐藏状态。这些隐藏状态被输入到预测模块中。预测模块是一个小的神经网络,它学习如何将这些隐藏状态映射到答案标签。整个过程不需要对LLM进行微调。
关键创新:InnerThoughts的关键创新在于解耦了LLM的表征能力和预测能力。通过训练一个独立的预测模块,可以更灵活地利用LLM学习到的信息,并避免了对LLM进行微调的需要。这使得该方法在计算成本上更具优势,并且可以更容易地应用于不同的LLM。
关键设计:预测模块可以使用各种神经网络结构,例如多层感知机(MLP)。损失函数通常使用交叉熵损失,用于衡量预测标签和真实标签之间的差异。关键参数包括预测模块的网络结构、学习率和训练轮数。作者可能探索了不同的隐藏状态组合方式,例如对不同层的隐藏状态进行加权平均。
🖼️ 关键图片

📊 实验亮点
InnerThoughts在多个困难的基准测试中取得了显著的性能提升,例如在某些数据集上,性能提升可与监督微调相媲美,但计算成本却大大降低。具体的数据提升幅度未知,但摘要中明确说明是“considerable improvements”。该方法证明了解耦表征和预测能力可以有效提升LLM的性能。
🎯 应用场景
InnerThoughts框架可广泛应用于各种需要利用大语言模型进行推理和预测的任务,例如知识问答、阅读理解、常识推理等。该方法降低了微调LLM的计算成本,使得在资源受限的环境中也能有效利用LLM的强大能力。未来,该方法可以扩展到其他类型的任务,例如文本生成和对话系统。
📄 摘要(原文)
Large language models (LLMs) contain substantial factual knowledge which is commonly elicited by multiple-choice question-answering prompts. Internally, such models process the prompt through multiple transformer layers, building varying representations of the problem within its hidden states. Ultimately, however, only the hidden state corresponding to the final layer and token position are used to predict the answer label. In this work, we propose instead to learn a small separate neural network predictor module on a collection of training questions, that take the hidden states from all the layers at the last temporal position as input and outputs predictions. In effect, such a framework disentangles the representational abilities of LLMs from their predictive abilities. On a collection of hard benchmarks, our method achieves considerable improvements in performance, sometimes comparable to supervised fine-tuning procedures, but at a fraction of the computational cost.