Learning Beyond the Surface: How Far Can Continual Pre-Training with LoRA Enhance LLMs' Domain-Specific Insight Learning?
作者: Pouya Pezeshkpour, Estevam Hruschka
分类: cs.CL, cs.LG
发布日期: 2025-01-29
💡 一句话要点
LoRA持续预训练提升LLM领域知识洞察力:医学与金融案例研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 持续预训练 LoRA 领域知识 洞察力学习
📋 核心要点
- 现有LLM在领域知识学习中,难以深入理解和内化深层洞察,仅停留在表面知识层面。
- 论文提出利用LoRA进行持续预训练,并对文档进行修改,保留关键信息,以提升LLM的洞察力学习能力。
- 实验结果表明,在修改后的文档上进行持续预训练能显著提升LLM在医学和金融领域的洞察力学习能力。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出了卓越的性能,但它们从特定领域数据集中提取和内化更深层次洞察力的能力仍有待探索。本研究探讨了持续预训练如何增强LLM在三种不同形式的洞察力学习能力:陈述性、统计性和概率性洞察力。我们专注于医学和金融这两个关键领域,采用LoRA在两个现有数据集上训练LLM。为了评估每种洞察力类型,我们创建了基准来衡量持续预训练在多大程度上帮助模型超越表面知识。我们还评估了文档修改对捕获洞察力的影响。结果表明,虽然在原始文档上进行持续预训练的效果不明显,但修改文档以仅保留必要信息可以显著提高LLM的洞察力学习能力。
🔬 方法详解
问题定义:论文旨在解决LLM在特定领域数据集上学习深层洞察力不足的问题。现有方法通常直接在原始文档上进行预训练或微调,但LLM难以从冗余信息中提取关键知识和潜在关系,导致学习效果不佳。这限制了LLM在需要深入理解和推理的领域应用,例如医学诊断和金融风险评估。
核心思路:论文的核心思路是通过持续预训练和文档修改相结合的方式,提升LLM的洞察力学习能力。首先,利用LoRA(Low-Rank Adaptation)对LLM进行高效的参数更新,避免全参数微调带来的计算负担。其次,对原始文档进行修改,去除冗余信息,保留关键知识点,使LLM能够更专注于学习重要的领域洞察。
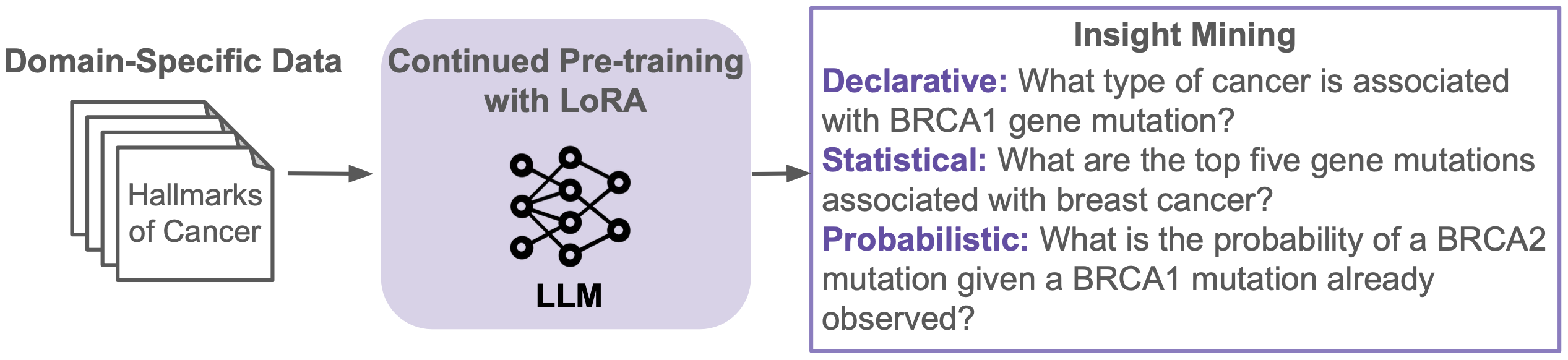
技术框架:整体流程包括以下几个阶段:1) 数据准备:收集医学和金融领域的原始文档,并进行预处理。2) 文档修改:根据领域知识,对文档进行修改,去除不必要的细节,保留核心信息。3) 持续预训练:使用LoRA在修改后的文档上对LLM进行持续预训练。4) 洞察力评估:设计基准测试,评估LLM在陈述性、统计性和概率性洞察力方面的学习效果。
关键创新:论文的关键创新在于将文档修改与持续预训练相结合,以提升LLM的洞察力学习能力。与传统的预训练方法相比,该方法更注重知识的提炼和精简,使LLM能够更有效地学习深层领域知识。此外,论文还针对不同类型的洞察力设计了专门的评估基准,为后续研究提供了参考。
关键设计:论文使用LoRA进行参数高效的微调,具体参数设置未知。文档修改策略依赖于领域专家的知识,目标是保留文档中的关键信息,去除冗余信息。损失函数采用标准的语言模型损失函数,目标是最小化模型预测下一个词的误差。评估基准的设计需要根据不同类型的洞察力进行定制,例如,对于陈述性洞察力,可以设计问答任务;对于统计性洞察力,可以设计统计推断任务;对于概率性洞察力,可以设计概率预测任务。
🖼️ 关键图片
📊 实验亮点
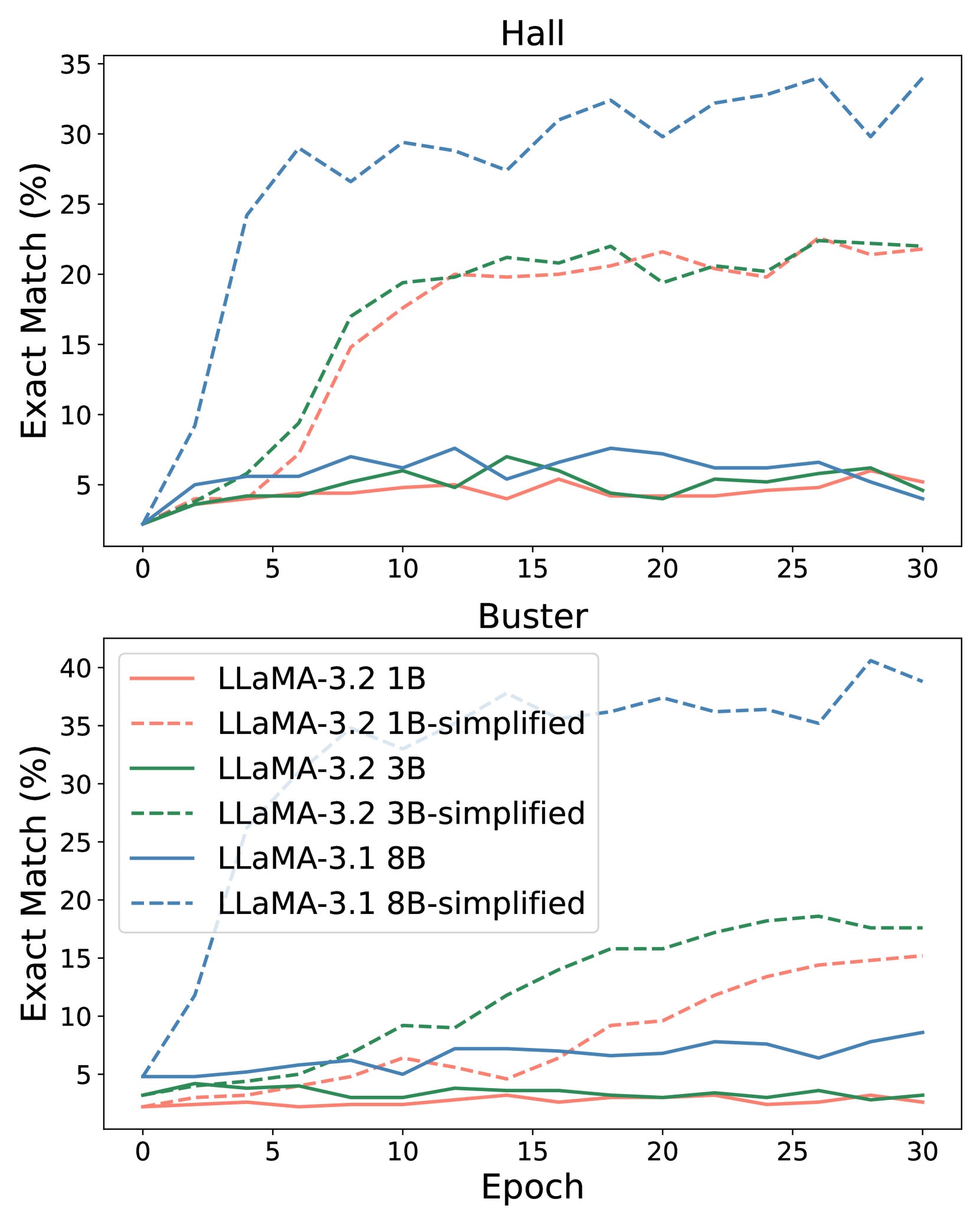
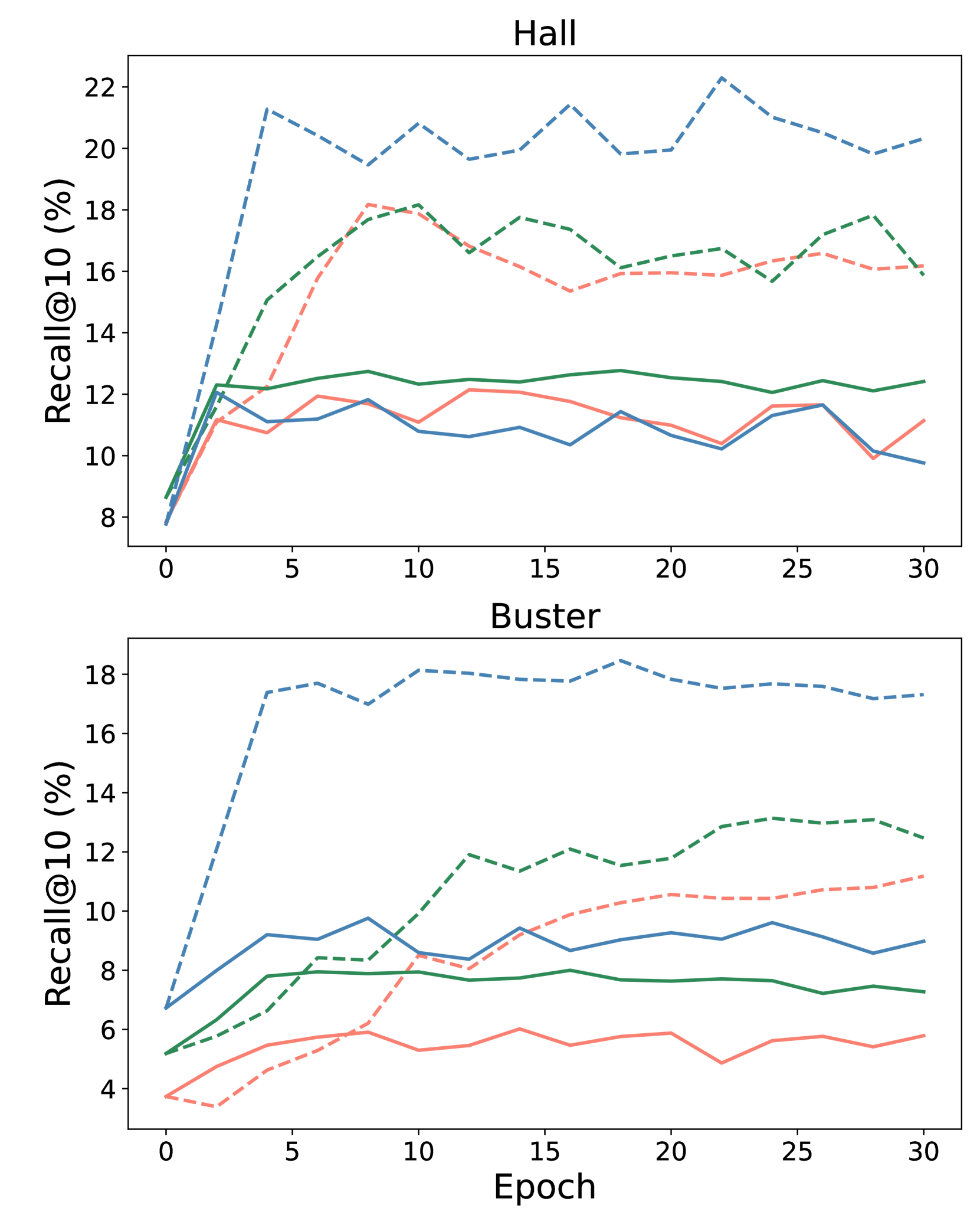
实验结果表明,在原始文档上进行持续预训练的效果不明显,而修改文档以仅保留必要信息可以显著提高LLM的洞察力学习能力。具体的性能提升数据未知,但论文强调了文档修改的重要性,为后续研究提供了新的思路。
🎯 应用场景
该研究成果可应用于多个领域,例如:医学诊断辅助系统,帮助医生快速准确地理解病历信息,提高诊断效率;金融风险评估系统,帮助分析师识别潜在的风险因素,降低投资风险;智能客服系统,能够更深入地理解用户的问题,提供更准确的答案。未来,该方法有望推广到其他需要深入领域知识的场景。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable performance on various tasks, yet their ability to extract and internalize deeper insights from domain-specific datasets remains underexplored. In this study, we investigate how continual pre-training can enhance LLMs' capacity for insight learning across three distinct forms: declarative, statistical, and probabilistic insights. Focusing on two critical domains: medicine and finance, we employ LoRA to train LLMs on two existing datasets. To evaluate each insight type, we create benchmarks to measure how well continual pre-training helps models go beyond surface-level knowledge. We also assess the impact of document modification on capturing insights. The results show that, while continual pre-training on original documents has a marginal effect, modifying documents to retain only essential information significantly enhances the insight-learning capabilities of LLMs.