Query-Aware Learnable Graph Pooling Tokens as Prompt for Large Language Models
作者: Wooyoung Kim, Byungyoon Park, Wooju Kim
分类: cs.CL
发布日期: 2025-01-29
💡 一句话要点
提出LGPT:一种查询感知的可学习图池化Token方法,用于增强大语言模型处理图数据的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图神经网络 大语言模型 图池化 可学习Token 查询融合 知识图谱问答 图表示学习
📋 核心要点
- 现有图神经网络在处理大规模图数据时面临可扩展性挑战,且将图信息融入大语言模型存在信息损失。
- LGPT方法通过引入可学习的图池化Token,作为大语言模型的prompt,有效平衡了细粒度和全局图信息。
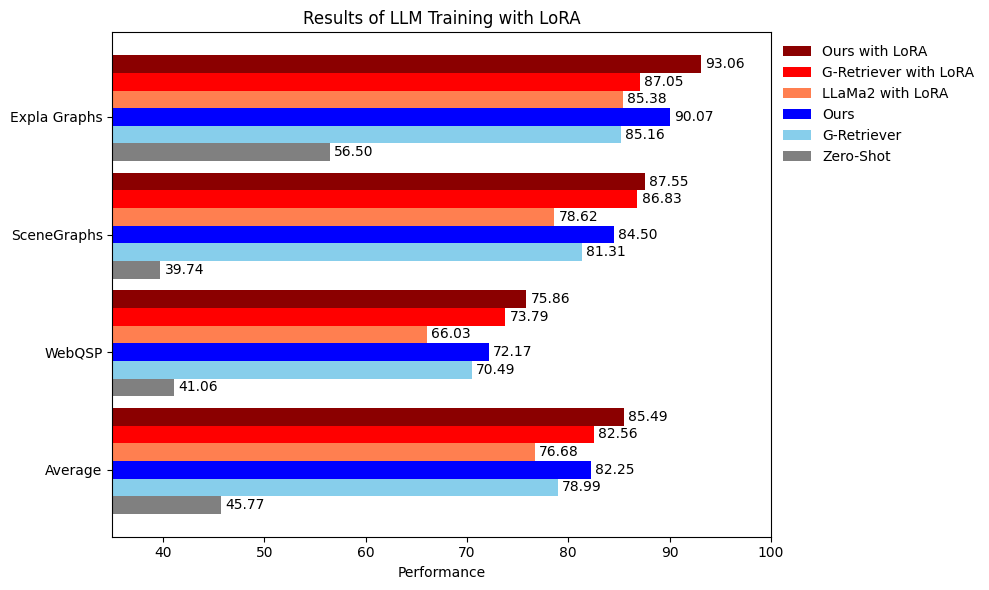
- 实验表明,LGPT在GraphQA任务上无需训练大语言模型即可获得显著性能提升,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为可学习图池化Token(LGPT)的新方法,旨在解决节点级别投影的可扩展性问题以及图级别投影的信息丢失问题。LGPT通过引入可学习参数作为大语言模型中的token,实现了灵活高效的图表示,从而平衡了细粒度和全局图信息。此外,本文还研究了一种早期查询融合技术,该技术在构建图表示之前融合查询上下文,从而产生更有效的图嵌入。实验结果表明,该方法在不训练大语言模型的情况下,在GraphQA基准测试中实现了4.13%的性能提升,证明了其在处理复杂文本属性图数据方面的显著优势。
🔬 方法详解
问题定义:现有方法在将图结构数据融入大型语言模型时面临挑战。节点级别的投影方法计算成本高昂,难以扩展到大型图;而图级别的投影方法则可能丢失重要的细粒度信息。因此,如何在保证效率的同时,充分利用图结构信息是一个关键问题。
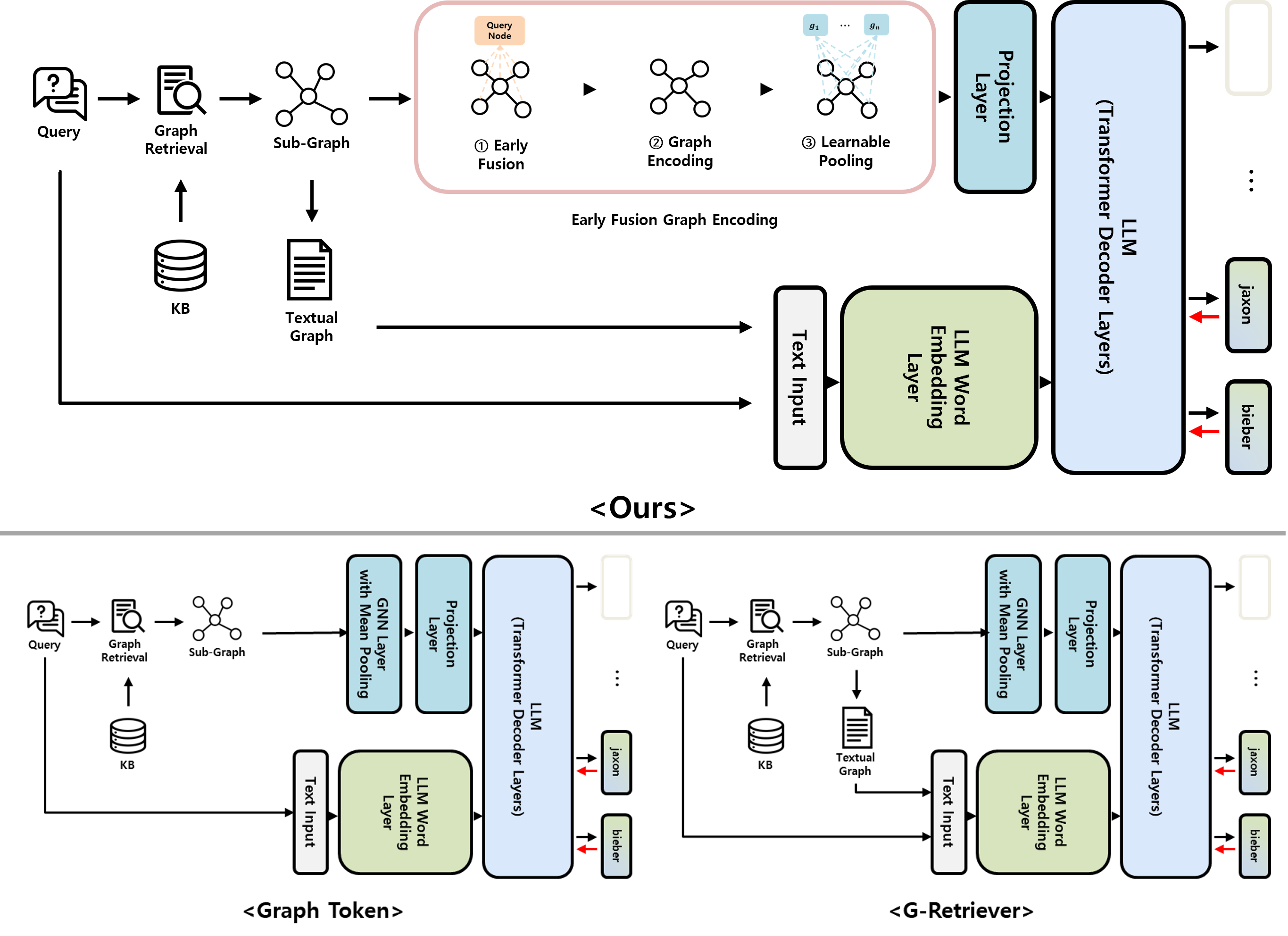
核心思路:本文的核心思路是引入可学习的图池化Token(LGPT),将其作为prompt输入到大型语言模型中。这些Token能够学习图的全局和局部特征,从而在不增加计算复杂度的前提下,保留更多的图信息。同时,通过早期查询融合,将查询信息融入图表示,进一步提升性能。
技术框架:整体框架包含以下几个主要阶段:1) 图构建:根据输入数据构建图结构。2) 查询融合(可选):将查询信息与图节点特征进行融合。3) LGPT生成:使用可学习参数生成图池化Token。4) 大语言模型推理:将LGPT作为prompt输入到大语言模型中,进行下游任务的预测。
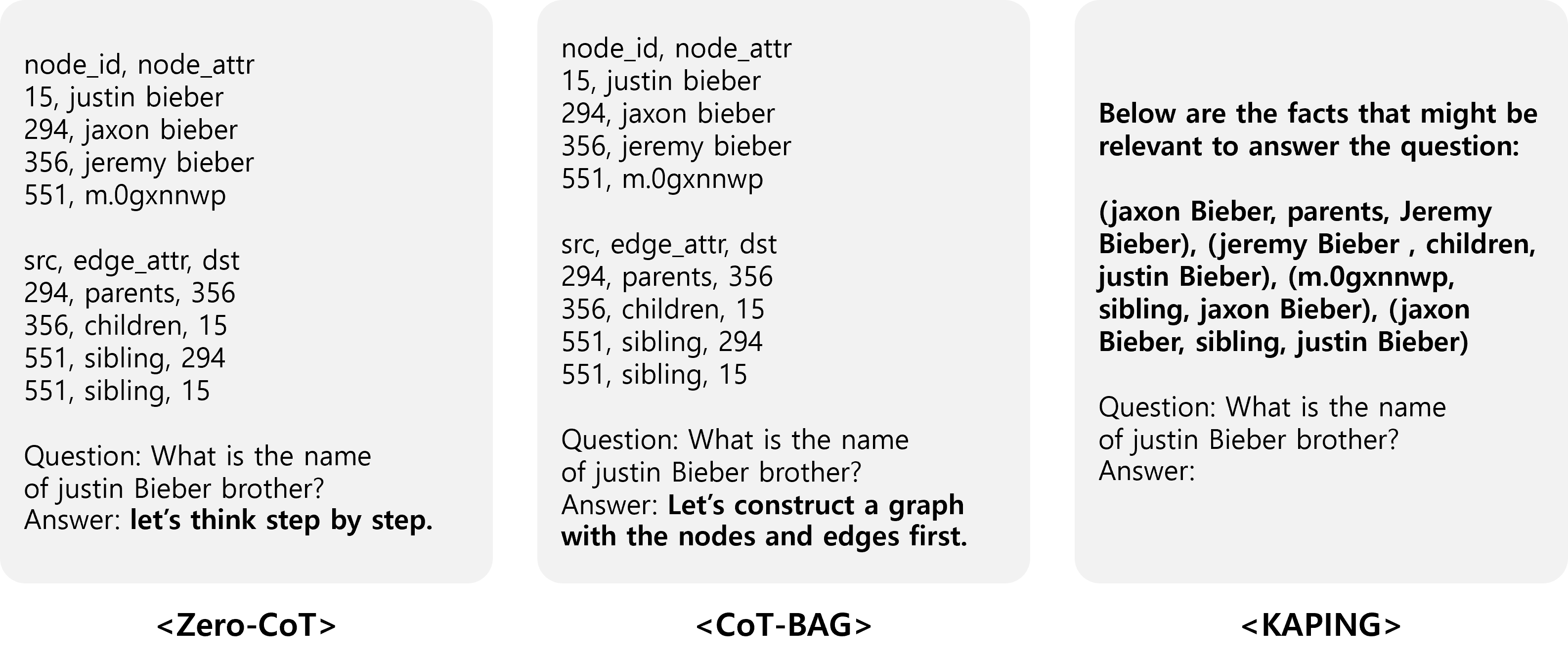
关键创新:最重要的技术创新点在于引入了可学习的图池化Token。与传统的节点或图级别的投影方法不同,LGPT能够学习到更具表达能力的图表示,并且可以灵活地控制信息的粒度。此外,早期查询融合也是一个重要的创新点,它能够将查询信息更早地融入到图表示中,从而提高模型的性能。
关键设计:LGPT的关键设计在于如何学习这些Token。一种可能的实现方式是使用一个小型神经网络,以图节点特征作为输入,输出一组可学习的Token。损失函数可以根据具体的下游任务进行设计,例如,可以使用交叉熵损失函数来训练LGPT,使其能够更好地预测图节点的类别。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LGPT方法在GraphQA基准测试中取得了显著的性能提升,在不训练大语言模型的情况下,性能提升了4.13%。这表明LGPT能够有效地利用图结构信息,并且可以与大型语言模型进行无缝集成,从而提高模型的性能。
🎯 应用场景
该研究成果可广泛应用于需要处理图结构数据的领域,例如知识图谱问答、社交网络分析、推荐系统、生物信息学等。通过将图信息有效地融入大型语言模型,可以提升这些应用在复杂推理和决策方面的能力,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Graph-structured data plays a vital role in numerous domains, such as social networks, citation networks, commonsense reasoning graphs and knowledge graphs. While graph neural networks have been employed for graph processing, recent advancements have explored integrating large language models for graph-based tasks. In this paper, we propose a novel approach named Learnable Graph Pooling Token (LGPT), which addresses the limitations of the scalability issues in node-level projection and information loss in graph-level projection. LGPT enables flexible and efficient graph representation by introducing learnable parameters that act as tokens in large language models, balancing fine-grained and global graph information. Additionally, we investigate an Early Query Fusion technique, which fuses query context before constructing the graph representation, leading to more effective graph embeddings. Our method achieves a 4.13\% performance improvement on the GraphQA benchmark without training the large language model, demonstrating significant gains in handling complex textual-attributed graph data.