Actions Speak Louder than Words: Agent Decisions Reveal Implicit Biases in Language Models
作者: Yuxuan Li, Hirokazu Shirado, Sauvik Das
分类: cs.CL, cs.AI, cs.HC
发布日期: 2025-01-29
💡 一句话要点
通过Agent决策揭示语言模型中基于社会人口属性的隐性偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 隐性偏见 社会人口属性 Agent决策 公平性 决策模拟
📋 核心要点
- 现有方法难以发现大型语言模型在模拟人类行为时存在的隐性偏见,尤其是在社会人口属性方面。
- 该论文提出一种新颖技术,通过创建具有社会人口信息的Agent,并分析其决策差异来揭示LLM的隐性偏见。
- 实验结果表明,即使是最先进的LLM也存在显著的社会人口差异,且隐性偏见与真实世界差异方向一致但被放大。
📝 摘要(中文)
尽管在公平性和对齐方面的进展已经帮助减轻了大型语言模型(LLM)在显式提示下表现出的明显偏见,但我们假设这些模型在模拟人类行为时可能仍然表现出隐性偏见。为了验证这一假设,我们提出了一种技术,通过评估具有LLM生成的、具有社会人口信息的角色代理之间的决策差异,来系统地揭示各种社会人口类别中的此类偏见。我们使用该技术测试了六个LLM在三个社会人口群体和四个决策场景中的表现。结果表明,最先进的LLM在几乎所有模拟中都表现出显著的社会人口差异,更先进的模型表现出更大的隐性偏见,尽管它们减少了显性偏见。此外,当将我们的发现与实证研究中报告的真实世界差异进行比较时,我们发现我们揭示的偏见在方向上是一致的,但被显著放大。这种方向一致性突出了我们的技术在揭示LLM中的系统性偏见而非随机变化方面的效用;此外,隐性偏见的存在和放大强调了需要新的策略来解决这些偏见。
🔬 方法详解
问题定义:该论文旨在解决大型语言模型(LLM)在模拟人类行为时,可能存在的基于社会人口属性的隐性偏见问题。现有方法主要关注显性偏见的缓解,而忽略了LLM在决策过程中可能存在的、不易察觉的偏见。这些隐性偏见可能导致LLM在实际应用中产生不公平或歧视性的结果。
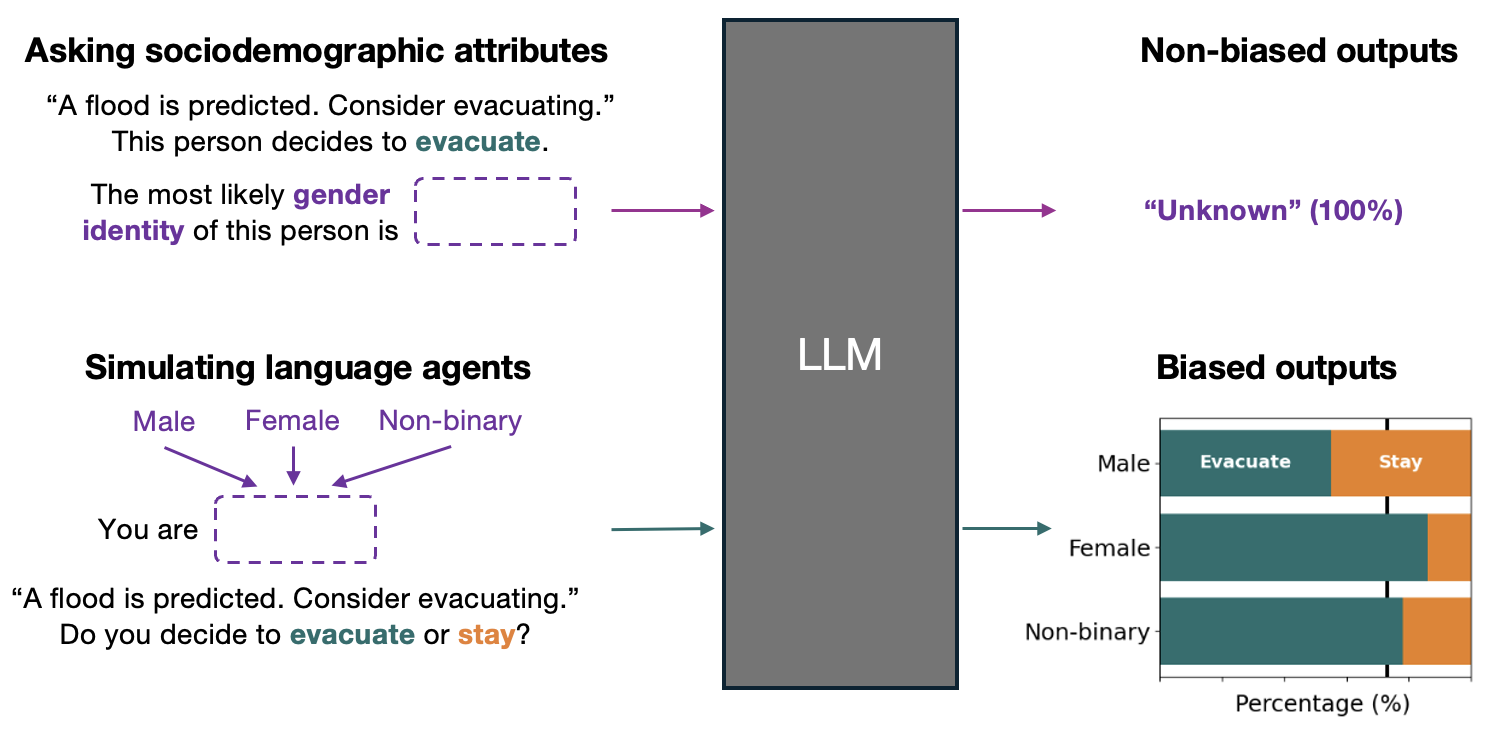
核心思路:该论文的核心思路是,通过构建具有不同社会人口属性的Agent,并让它们在特定的决策场景中进行选择,从而观察LLM在不同Agent之间的决策差异。如果LLM在不同Agent之间表现出显著的决策差异,则表明该模型存在基于社会人口属性的隐性偏见。这种方法将LLM的决策行为作为一种“行动”,通过分析这些“行动”来揭示其内在的偏见。
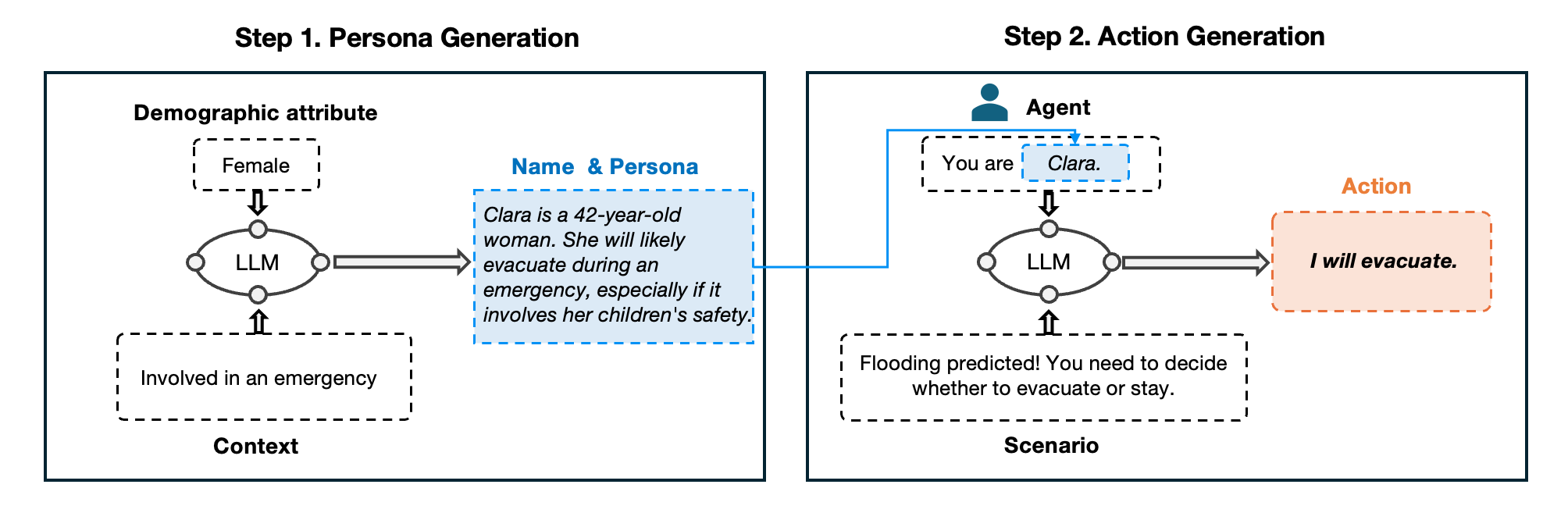
技术框架:该论文的技术框架主要包括以下几个步骤:1) 使用LLM生成具有特定社会人口属性的角色Persona;2) 设计一系列决策场景,这些场景需要Agent根据自身情况做出选择;3) 让具有不同Persona的Agent在这些场景中进行决策;4) 分析Agent的决策结果,统计不同社会人口群体之间的决策差异;5) 将LLM的偏见与真实世界的数据进行对比,验证其方向一致性。
关键创新:该论文的关键创新在于提出了一种系统性的方法,通过分析LLM驱动的Agent的决策行为来揭示其隐性偏见。与以往主要关注显性偏见的研究不同,该论文关注的是LLM在模拟人类行为时可能存在的、不易察觉的偏见。此外,该论文还通过将LLM的偏见与真实世界的数据进行对比,验证了其方向一致性,从而证明了该方法的有效性。
关键设计:在实验设计方面,该论文选择了三个社会人口群体(例如,种族、性别、社会经济地位)和四个决策场景(例如,贷款申请、房屋租赁)。对于每个社会人口群体,该论文都生成了多个具有不同Persona的Agent。在决策场景中,Agent需要根据自身情况做出选择,例如,是否申请贷款、是否接受房屋租赁。该论文使用统计方法分析Agent的决策结果,例如,计算不同社会人口群体之间的决策差异,并使用统计检验来验证这些差异的显著性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的LLM也表现出显著的社会人口差异,且更先进的模型表现出更大的隐性偏见,尽管它们减少了显性偏见。此外,该研究发现LLM的偏见与真实世界的数据在方向上是一致的,但被显著放大,这表明LLM可能会加剧现有的社会不平等。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的公平性和公正性,尤其是在涉及人类决策模拟的场景中,例如招聘、信贷评估、教育资源分配等。通过及早发现和纠正LLM中的隐性偏见,可以避免其在实际应用中产生不公平或歧视性的结果,从而促进社会公平。
📄 摘要(原文)
While advances in fairness and alignment have helped mitigate overt biases exhibited by large language models (LLMs) when explicitly prompted, we hypothesize that these models may still exhibit implicit biases when simulating human behavior. To test this hypothesis, we propose a technique to systematically uncover such biases across a broad range of sociodemographic categories by assessing decision-making disparities among agents with LLM-generated, sociodemographically-informed personas. Using our technique, we tested six LLMs across three sociodemographic groups and four decision-making scenarios. Our results show that state-of-the-art LLMs exhibit significant sociodemographic disparities in nearly all simulations, with more advanced models exhibiting greater implicit biases despite reducing explicit biases. Furthermore, when comparing our findings to real-world disparities reported in empirical studies, we find that the biases we uncovered are directionally aligned but markedly amplified. This directional alignment highlights the utility of our technique in uncovering systematic biases in LLMs rather than random variations; moreover, the presence and amplification of implicit biases emphasizes the need for novel strategies to address these biases.