Divergent Emotional Patterns in Disinformation on Social Media? An Analysis of Tweets and TikToks about the DANA in Valencia
作者: Iván Arcos, Paolo Rosso, Ramón Salaverría
分类: cs.CL, cs.CY, cs.SI
发布日期: 2025-01-28
期刊: Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025), Porto, Portugal, February 23-25, 2025
💡 一句话要点
分析社交媒体上关于西班牙DANA风暴的虚假信息,揭示不同平台的情感模式差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 虚假信息检测 社交媒体分析 情感分析 多模态学习 音频特征 文本分析 GPT-4o
📋 核心要点
- 社交媒体上虚假信息泛滥,现有方法难以有效区分不同平台上的情感表达差异。
- 通过分析文本、音频和情感特征,揭示X和TikTok平台上虚假信息的情感模式差异。
- 实验表明,融合音频特征的RoBERTa模型和GPT-4o在虚假信息检测方面表现优异,提升了准确率和F1-Score。
📝 摘要(中文)
本研究调查了2024年10月29日西班牙瓦伦西亚DANA事件(高空孤立低压)期间,社交媒体平台上虚假信息的传播。我们创建了一个包含650个TikTok和X帖子(原Twitter)的新数据集,并手动标注以区分虚假信息和可信内容。此外,使用GPT-4o的Few-Shot标注方法与手动标注达成高度一致(Cohen's kappa值为0.684)。情感分析表明,X上的虚假信息主要与悲伤和恐惧情绪相关,而TikTok上则与愤怒和厌恶情绪相关。使用LIWC词典的语言分析表明,可信内容使用更清晰和基于事实的语言,而虚假信息则使用否定、感知词和个人轶事来增强可信度。对TikTok帖子音频的分析突出了不同的模式:可信音频具有更明亮的音调和机器人或单调的叙述,以提高清晰度和可信度,而虚假信息音频则利用音调变化、情感深度和操纵性音乐元素来放大参与度。在检测模型中,SVM+TF-IDF实现了最高的F1-Score,在有限数据下表现出色。将音频特征纳入roberta-large-bne模型提高了准确率和F1-Score,超过了其纯文本版本和SVM在准确率方面的表现。GPT-4o Few-Shot也表现良好,展示了大型语言模型在自动虚假信息检测方面的潜力。这些发现表明,利用文本和音频特征对于改进TikTok等多模态平台上的虚假信息检测至关重要。
🔬 方法详解
问题定义:该论文旨在解决社交媒体平台上虚假信息检测的问题,尤其关注在不同平台(如X和TikTok)上,虚假信息的情感表达模式存在差异。现有方法通常只关注文本特征,忽略了音频特征以及不同平台用户情感表达的差异性,导致检测效果不佳。
核心思路:该论文的核心思路是结合文本、音频和情感等多模态特征,分析不同社交媒体平台上虚假信息的情感模式差异,并利用这些差异来提高虚假信息检测的准确性。通过深入分析不同平台用户的情感表达方式,可以更有效地识别和过滤虚假信息。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集与标注:收集关于DANA事件的X和TikTok帖子,并手动标注为虚假信息或可信内容。同时,使用GPT-4o进行Few-Shot标注,并与手动标注进行一致性评估。2) 特征提取:从文本中提取语言特征(使用LIWC词典),从音频中提取音频特征(如音调、音调变化等),并进行情感分析。3) 模型训练与评估:使用SVM+TF-IDF、RoBERTa等模型进行虚假信息检测,并评估模型在不同特征组合下的性能。4) 结果分析:分析不同平台上的情感模式差异,以及音频特征对检测性能的影响。
关键创新:该论文的关键创新在于:1) 首次关注并分析了不同社交媒体平台上虚假信息的情感模式差异。2) 结合了文本和音频等多模态特征,提高了虚假信息检测的准确性。3) 验证了GPT-4o在Few-Shot标注方面的潜力,为自动虚假信息检测提供了新的思路。
关键设计:在数据标注方面,采用了人工标注和GPT-4o Few-Shot标注相结合的方式,保证了标注的准确性和效率。在特征提取方面,使用了LIWC词典进行语言特征分析,并提取了音频的音调、音调变化等特征。在模型训练方面,使用了SVM+TF-IDF和RoBERTa等模型,并针对多模态数据进行了优化。具体参数设置未知。
🖼️ 关键图片
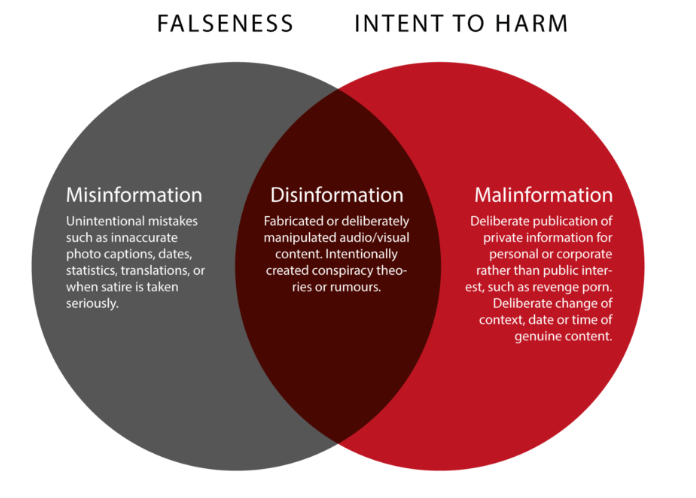


📊 实验亮点
实验结果表明,SVM+TF-IDF在有限数据下表现出色,实现了最高的F1-Score。将音频特征纳入roberta-large-bne模型后,准确率和F1-Score均得到提升,超过了纯文本版本和SVM在准确率方面的表现。GPT-4o Few-Shot也表现良好,Cohen's kappa值为0.684,展示了大型语言模型在自动虚假信息检测方面的潜力。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,帮助自动检测和过滤虚假信息,尤其是在突发事件或危机事件期间。通过识别不同平台上的情感模式差异,可以更有效地应对虚假信息的传播,维护社会稳定和公众利益。未来,该方法可以扩展到其他类型的社交媒体平台和事件。
📄 摘要(原文)
This study investigates the dissemination of disinformation on social media platforms during the DANA event (DANA is a Spanish acronym for Depresion Aislada en Niveles Altos, translating to high-altitude isolated depression) that resulted in extremely heavy rainfall and devastating floods in Valencia, Spain, on October 29, 2024. We created a novel dataset of 650 TikTok and X posts, which was manually annotated to differentiate between disinformation and trustworthy content. Additionally, a Few-Shot annotation approach with GPT-4o achieved substantial agreement (Cohen's kappa of 0.684) with manual labels. Emotion analysis revealed that disinformation on X is mainly associated with increased sadness and fear, while on TikTok, it correlates with higher levels of anger and disgust. Linguistic analysis using the LIWC dictionary showed that trustworthy content utilizes more articulate and factual language, whereas disinformation employs negations, perceptual words, and personal anecdotes to appear credible. Audio analysis of TikTok posts highlighted distinct patterns: trustworthy audios featured brighter tones and robotic or monotone narration, promoting clarity and credibility, while disinformation audios leveraged tonal variation, emotional depth, and manipulative musical elements to amplify engagement. In detection models, SVM+TF-IDF achieved the highest F1-Score, excelling with limited data. Incorporating audio features into roberta-large-bne improved both Accuracy and F1-Score, surpassing its text-only counterpart and SVM in Accuracy. GPT-4o Few-Shot also performed well, showcasing the potential of large language models for automated disinformation detection. These findings demonstrate the importance of leveraging both textual and audio features for improved disinformation detection on multimodal platforms like TikTok.