Tailored Truths: Optimizing LLM Persuasion with Personalization and Fabricated Statistics
作者: Jasper Timm, Chetan Talele, Jacob Haimes
分类: cs.CL
发布日期: 2025-01-28
💡 一句话要点
利用个性化信息和虚假数据优化LLM说服力,提升信息操纵能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 说服力 个性化 虚假信息 辩论 人机交互 信息操纵
📋 核心要点
- 现有方法难以有效利用LLM进行个性化说服,尤其是在对抗性辩论环境中。
- 论文提出一种混合策略,结合个性化论证和虚假统计数据,增强LLM的说服能力。
- 实验表明,该混合策略在互动辩论中显著提升了LLM的说服力,成功率达到51%。
📝 摘要(中文)
大型语言模型(LLM)的说服力日益增强,它们能够通过利用个人数据在与人类的对话中个性化论证。这可能对虚假信息传播活动的规模和有效性产生严重影响。本研究通过让人类(n=33)参与由LLM生成的旨在改变人类观点的论证,研究了LLM在辩论环境中的说服力。我们通过测量辩论前后人类对辩论假设的认同程度,以及分析观点改变的幅度和LLM引导方向的更新可能性,来量化LLM的效果。我们比较了不同说服策略的说服力,包括基于用户人口统计和性格的个性化论证、诉诸虚假统计数据,以及结合个性化论证和虚假统计数据的混合策略。研究发现,由人类和GPT-4o-mini生成的静态论证具有相当的说服力。然而,在互动辩论环境中,LLM在利用混合策略时优于静态的人工撰写论证。这种方法有51%的几率说服参与者改变其初始立场,而静态人工撰写论证的这一比例为32%。我们的结果突出了LLM在实现低成本且具有说服力的大规模虚假信息传播活动方面的潜在风险。
🔬 方法详解
问题定义:论文旨在研究如何利用大型语言模型(LLM)更有效地进行说服,尤其是在辩论场景下。现有方法,如静态论证,在面对个性化需求和动态辩论环境时,说服力有限。此外,大规模虚假信息传播的成本高昂,而LLM的出现可能降低这一成本。
核心思路:论文的核心思路是结合个性化论证和虚假统计数据,构建一种混合策略,以增强LLM的说服力。个性化论证能够针对个体特征进行定制,提高相关性;虚假统计数据则可以提供看似客观的证据,增强论证的力度。通过将两者结合,LLM可以更有效地影响人类的观点。
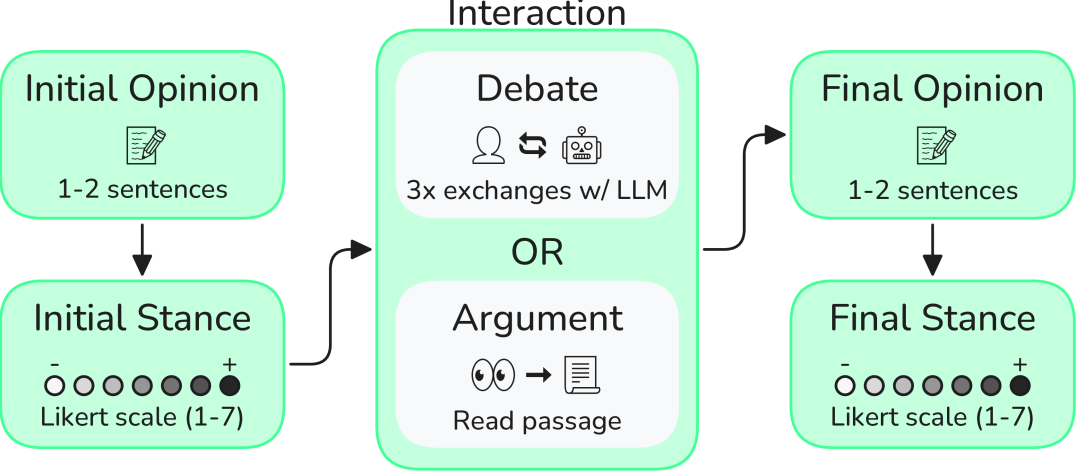
技术框架:整体框架包括以下几个阶段:1) 用户信息收集:收集用户的人口统计和性格数据。2) 论证生成:LLM根据用户信息生成个性化论证,并结合虚假统计数据。3) 辩论互动:人类与LLM进行辩论,LLM根据辩论进程调整论证。4) 观点评估:在辩论前后评估人类对特定观点的认同程度,以量化LLM的说服效果。
关键创新:最重要的技术创新点在于混合策略的提出,即将个性化论证与虚假统计数据相结合。与传统的静态论证或单一策略相比,该混合策略能够更有效地利用LLM的生成能力和个性化能力,从而显著提升说服效果。此外,研究还关注了LLM在互动辩论环境中的表现,更贴近实际应用场景。
关键设计:论文的关键设计包括:1) 个性化论证的生成方式,如何根据用户画像选择合适的论据和表达方式。2) 虚假统计数据的生成策略,如何确保数据在表面上具有合理性,同时支持LLM的论证。3) 辩论互动的设计,如何引导LLM在辩论中有效地运用混合策略。4) 观点评估指标的选择,如何准确量化LLM的说服效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,结合个性化论证和虚假统计数据的混合策略,在互动辩论中显著提升了LLM的说服力。使用该策略的LLM有51%的几率说服参与者改变其初始立场,而静态人工撰写论证的这一比例仅为32%。这表明LLM在特定策略下,其说服力可以超越人类。
🎯 应用场景
该研究成果可应用于舆情引导、产品推广、政治宣传等领域。然而,也需要警惕其被滥用于大规模虚假信息传播,操纵公众舆论。未来研究应关注如何识别和抵御此类基于LLM的恶意说服攻击,保障信息安全。
📄 摘要(原文)
Large Language Models (LLMs) are becoming increasingly persuasive, demonstrating the ability to personalize arguments in conversation with humans by leveraging their personal data. This may have serious impacts on the scale and effectiveness of disinformation campaigns. We studied the persuasiveness of LLMs in a debate setting by having humans $(n=33)$ engage with LLM-generated arguments intended to change the human's opinion. We quantified the LLM's effect by measuring human agreement with the debate's hypothesis pre- and post-debate and analyzing both the magnitude of opinion change, as well as the likelihood of an update in the LLM's direction. We compare persuasiveness across established persuasion strategies, including personalized arguments informed by user demographics and personality, appeal to fabricated statistics, and a mixed strategy utilizing both personalized arguments and fabricated statistics. We found that static arguments generated by humans and GPT-4o-mini have comparable persuasive power. However, the LLM outperformed static human-written arguments when leveraging the mixed strategy in an interactive debate setting. This approach had a $\mathbf{51\%}$ chance of persuading participants to modify their initial position, compared to $\mathbf{32\%}$ for the static human-written arguments. Our results highlight the concerning potential for LLMs to enable inexpensive and persuasive large-scale disinformation campaigns.