3D-MoE: A Mixture-of-Experts Multi-modal LLM for 3D Vision and Pose Diffusion via Rectified Flow
作者: Yueen Ma, Yuzheng Zhuang, Jianye Hao, Irwin King
分类: cs.CL, cs.CV, cs.RO
发布日期: 2025-01-28
备注: Preprint. Work in progress
💡 一句话要点
提出3D-MoE,通过混合专家模型和修正流扩散提升3D视觉和姿态扩散性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉 多模态学习 大型语言模型 混合专家模型 扩散模型 姿态估计 具身智能
📋 核心要点
- 高质量3D数据匮乏限制了3D视觉研究,现有3D多模态LLM主要关注视觉编码器。
- 将密集激活LLM转化为混合专家模型,并引入修正流扩散调度器,提升模型性能。
- 实验表明,3D-MoE框架在3D问答和任务规划中,以更少的参数实现了性能提升。
📝 摘要(中文)
本文提出了一种用于3D视觉的多模态大型语言模型(LLM)——3D-MoE,旨在提升模型在3D环境中的感知和空间推理能力。相较于传统基于2D图像的视觉推理,3D视觉更具优势,但高质量3D数据的获取存在挑战。该方法将现有密集激活的LLM转换为混合专家(MoE)模型,MoE已被证明在多模态数据处理中有效。除了利用LLM的指令遵循能力外,还通过附加一个扩散头Pose-DiT来实现具身任务规划,该扩散头采用了一种新颖的修正流扩散调度器。在3D问答和任务规划任务上的实验结果表明,3D-MoE框架以更少的激活参数实现了性能的提升。
🔬 方法详解
问题定义:现有3D多模态LLM主要集中在视觉编码器上,忽略了LLM本身的能力增强。此外,在具身任务规划方面,缺乏有效的扩散模型来处理3D姿态生成和控制。因此,需要一种能够充分利用LLM能力,并有效进行3D姿态扩散的模型。
核心思路:论文的核心思路是将现有的、已经预训练好的LLM转化为混合专家模型(MoE)。MoE模型能够根据输入数据的不同,激活不同的专家网络,从而提高模型的容量和效率。此外,通过引入修正流扩散模型,实现对3D姿态的精确控制和生成。
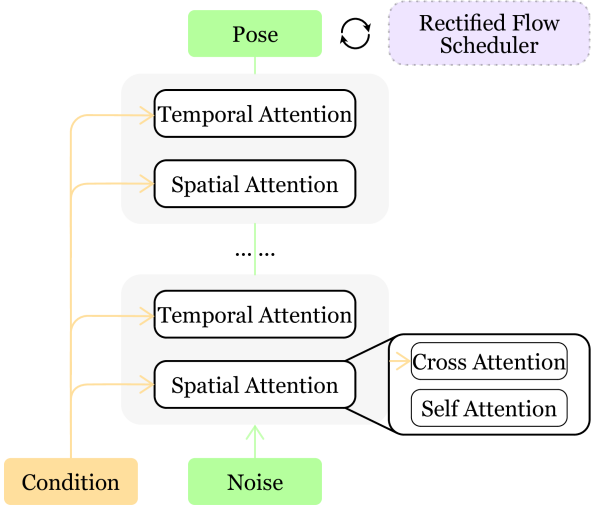
技术框架:3D-MoE框架主要包含两个核心模块:MoE LLM和Pose-DiT扩散头。首先,将预训练的LLM转换为MoE结构,用于处理3D视觉输入和指令。然后,将Pose-DiT扩散头连接到MoE LLM,用于生成3D姿态。Pose-DiT采用修正流扩散调度器,以提高扩散过程的稳定性和效率。
关键创新:论文的关键创新在于将MoE结构引入到3D多模态LLM中,并结合修正流扩散模型进行姿态生成。与传统的密集激活LLM相比,MoE模型能够以更少的计算资源实现更高的性能。修正流扩散调度器的引入,使得姿态生成过程更加稳定和可控。
关键设计:Pose-DiT扩散头采用DiT架构,并使用修正流扩散调度器。修正流扩散调度器的具体实现细节未知,但其目的是优化扩散过程,使其更加高效和稳定。MoE LLM的具体专家数量和路由策略未知,但这些参数的选择会直接影响模型的性能和效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,3D-MoE框架在3D问答和任务规划任务上取得了显著的性能提升。具体的数据和对比基线未知,但论文强调该模型以更少的激活参数实现了性能的提升,表明MoE结构的有效性。Pose-DiT扩散头的引入也为3D姿态生成提供了更精确的控制。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实、增强现实等领域。通过提升3D视觉和空间推理能力,可以使机器人在复杂环境中更好地理解和交互,从而实现更智能化的任务规划和执行。未来,该技术有望推动具身智能的发展,使机器人能够更好地服务于人类。
📄 摘要(原文)
3D vision and spatial reasoning have long been recognized as preferable for accurately perceiving our three-dimensional world, especially when compared with traditional visual reasoning based on 2D images. Due to the difficulties in collecting high-quality 3D data, research in this area has only recently gained momentum. With the advent of powerful large language models (LLMs), multi-modal LLMs for 3D vision have been developed over the past few years. However, most of these models focus primarily on the vision encoder for 3D data. In this paper, we propose converting existing densely activated LLMs into mixture-of-experts (MoE) models, which have proven effective for multi-modal data processing. In addition to leveraging these models' instruction-following capabilities, we further enable embodied task planning by attaching a diffusion head, Pose-DiT, that employs a novel rectified flow diffusion scheduler. Experimental results on 3D question answering and task-planning tasks demonstrate that our 3D-MoE framework achieves improved performance with fewer activated parameters.