MME-Industry: A Cross-Industry Multimodal Evaluation Benchmark
作者: Dongyi Yi, Guibo Zhu, Chenglin Ding, Zongshu Li, Dong Yi, Jinqiao Wang
分类: cs.CL
发布日期: 2025-01-28
备注: 9 pages,2 figures
💡 一句话要点
MME-Industry:面向工业场景的多模态大语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 工业应用 评测基准 领域知识 人工构建 数据验证 跨语言评估
📋 核心要点
- 现有MLLM评测基准缺乏对工业领域应用的全面评估,无法准确反映模型在实际工业场景中的表现。
- MME-Industry基准通过构建包含21个工业领域、1050个高质量问答对的数据集,填补了这一空白。
- 该基准包含非OCR问题和需要专业知识的任务,并提供中英文版本,可有效评估MLLM的跨语言能力。
📝 摘要(中文)
随着多模态大语言模型(MLLMs)的快速发展,涌现了大量的评估基准。然而,对于它们在不同工业应用中的性能进行全面评估仍然有限。本文提出了MME-Industry,这是一个专门为评估MLLMs在工业环境中表现而设计的新基准。该基准包含21个不同的领域,包括1050个问答对,每个领域50个问题。为了确保数据的完整性并防止公共数据集中的潜在泄露,所有问答对均由领域专家手动创建和验证。此外,该基准通过结合可以直接回答的非OCR问题以及需要专业领域知识的任务,有效地提高了复杂性。而且,我们提供了该基准的中文和英文版本,从而可以对MLLMs在这些语言中的能力进行比较分析。我们的发现为MLLMs的实际工业应用提供了有价值的见解,并为未来的模型优化研究指明了有希望的方向。
🔬 方法详解
问题定义:现有的大部分多模态大语言模型评测基准,在工业领域的覆盖度不足,无法有效评估模型在解决实际工业问题时的能力。这些基准可能无法充分测试模型对专业知识的掌握程度,以及处理复杂工业场景问题的能力。因此,需要一个专门面向工业场景的评测基准,以更准确地评估MLLM的性能。
核心思路:MME-Industry的核心思路是构建一个高质量、多样化的工业领域问答数据集,该数据集涵盖多个工业领域,并包含需要专业知识和推理能力的问题。通过人工构建和领域专家验证,确保数据的准确性和可靠性,避免数据泄露。同时,设计包含非OCR问题的任务,以更全面地评估模型的理解能力。
技术框架:MME-Industry基准主要包含以下几个部分:1) 领域选择:选择21个具有代表性的工业领域。2) 数据构建:领域专家手动构建每个领域的50个问答对,共计1050个问答对。3) 数据验证:领域专家对构建的数据进行验证,确保数据的准确性和一致性。4) 多语言支持:提供中文和英文两个版本的数据集。5) 问题类型设计:包含需要OCR的问题和不需要OCR的问题,以评估模型不同的能力。
关键创新:MME-Industry的关键创新在于其专注于工业领域,并采用人工构建和领域专家验证的方式来保证数据的质量和专业性。与现有基准相比,MME-Industry更贴近实际工业应用场景,能够更准确地评估MLLM在工业领域的性能。此外,多语言支持和问题类型的多样性也增强了基准的全面性。
关键设计:MME-Industry的关键设计包括:1) 领域选择:选择覆盖面广、具有代表性的工业领域,如制造业、能源、医疗等。2) 问题设计:设计需要专业知识、推理能力和视觉理解能力的问题,包括非OCR问题。3) 数据验证:采用多轮验证机制,确保数据的准确性和一致性。4) 评估指标:采用准确率、召回率等指标来评估模型的性能。具体参数设置和损失函数等细节未知。
🖼️ 关键图片

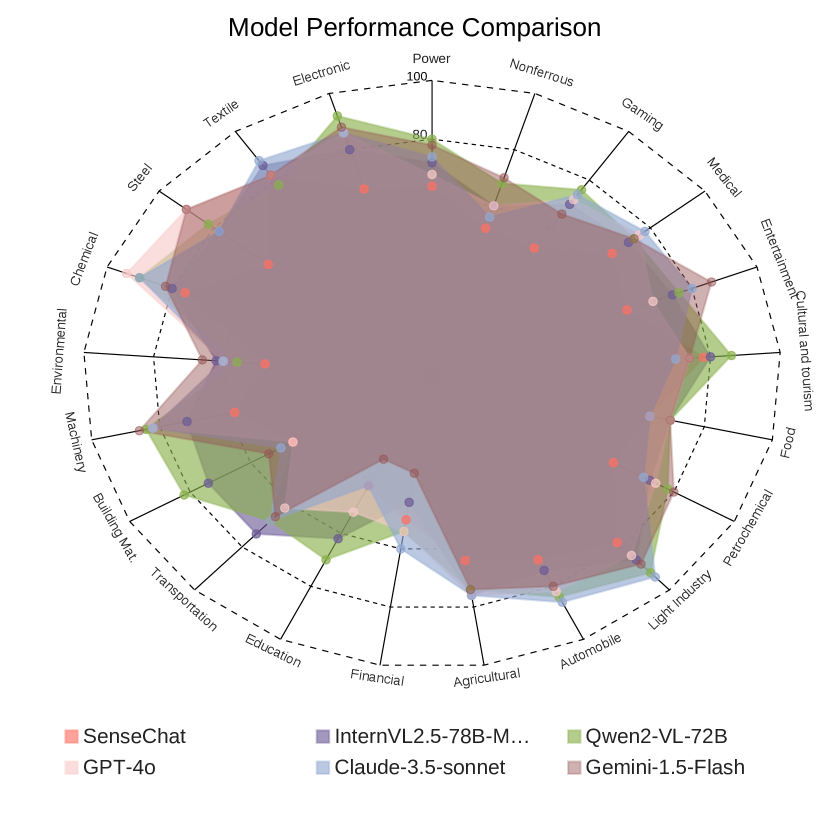
📊 实验亮点
MME-Industry基准包含21个工业领域,共1050个高质量问答对,所有数据均由领域专家手动构建和验证,保证了数据的准确性和可靠性。该基准还提供了中英文版本,并包含非OCR问题,能够全面评估MLLM在工业领域的性能。具体的性能数据和对比基线未知。
🎯 应用场景
MME-Industry可用于评估和比较不同MLLM在工业领域的性能,帮助研究人员和工程师选择合适的模型来解决实际工业问题。该基准还可以促进MLLM在工业领域的应用,例如智能制造、故障诊断、质量检测等。未来,可以基于该基准进一步研究如何优化MLLM在工业场景下的性能,提升工业智能化水平。
📄 摘要(原文)
With the rapid advancement of Multimodal Large Language Models (MLLMs), numerous evaluation benchmarks have emerged. However, comprehensive assessments of their performance across diverse industrial applications remain limited. In this paper, we introduce MME-Industry, a novel benchmark designed specifically for evaluating MLLMs in industrial settings.The benchmark encompasses 21 distinct domain, comprising 1050 question-answer pairs with 50 questions per domain. To ensure data integrity and prevent potential leakage from public datasets, all question-answer pairs were manually crafted and validated by domain experts. Besides, the benchmark's complexity is effectively enhanced by incorporating non-OCR questions that can be answered directly, along with tasks requiring specialized domain knowledge. Moreover, we provide both Chinese and English versions of the benchmark, enabling comparative analysis of MLLMs' capabilities across these languages. Our findings contribute valuable insights into MLLMs' practical industrial applications and illuminate promising directions for future model optimization research.