Audio Large Language Models Can Be Descriptive Speech Quality Evaluators
作者: Chen Chen, Yuchen Hu, Siyin Wang, Helin Wang, Zhehuai Chen, Chao Zhang, Chao-Han Huck Yang, Eng Siong Chng
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-01-27 (更新: 2025-03-12)
备注: ICLR 2025
💡 一句话要点
提出ALLD方法,提升音频大语言模型在语音质量评估任务中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频大语言模型 语音质量评估 自然语言处理 LLM蒸馏 多模态学习
📋 核心要点
- 现有音频LLM缺乏对语音质量的感知能力,限制了其在实际应用中的表现。
- 论文提出ALLD方法,通过构建自然语言语音评估语料库并进行LLM蒸馏对齐,提升模型性能。
- 实验表明,ALLD在MOS预测和A/B测试中均超越现有技术,并生成高质量的描述性文本。
📝 摘要(中文)
理想的多模态智能体应能感知其输入模态的质量。近年来,大型语言模型(LLM)已能整合音频系统以处理各种语音相关任务。然而,大多数音频LLM仍未意识到它们所处理语音的质量。这种局限性源于缺乏合适的语音质量评估数据集,导致多任务训练通常排除此项任务。为解决此问题,我们引入了首个基于自然语言的语音评估语料库,该语料库由真实的人工评分生成。除了总体平均意见得分(MOS)外,该语料库还提供跨多个维度的详细分析,并识别质量下降的原因。它还支持对两个语音样本(A/B测试)进行类似人类判断的描述性比较。利用此语料库,我们提出了一种基于LLM蒸馏的对齐方法(ALLD),以指导音频LLM从原始语音中提取相关信息并生成有意义的响应。实验结果表明,ALLD在MOS预测方面优于先前的最先进回归模型,均方误差为0.17,A/B测试准确率为98.6%。此外,生成的响应在两项任务中分别实现了25.8和30.2的BLEU分数,超越了特定任务模型的能力。这项工作推进了音频LLM对语音信号的全面感知,有助于开发真实的听觉和感觉智能体。
🔬 方法详解
问题定义:现有音频大语言模型(LLM)在处理语音任务时,通常忽略了输入语音的质量。这导致模型无法有效识别和处理低质量语音,影响了其在噪声环境或语音通信等场景下的性能。缺乏高质量的语音质量评估数据集是主要瓶颈。
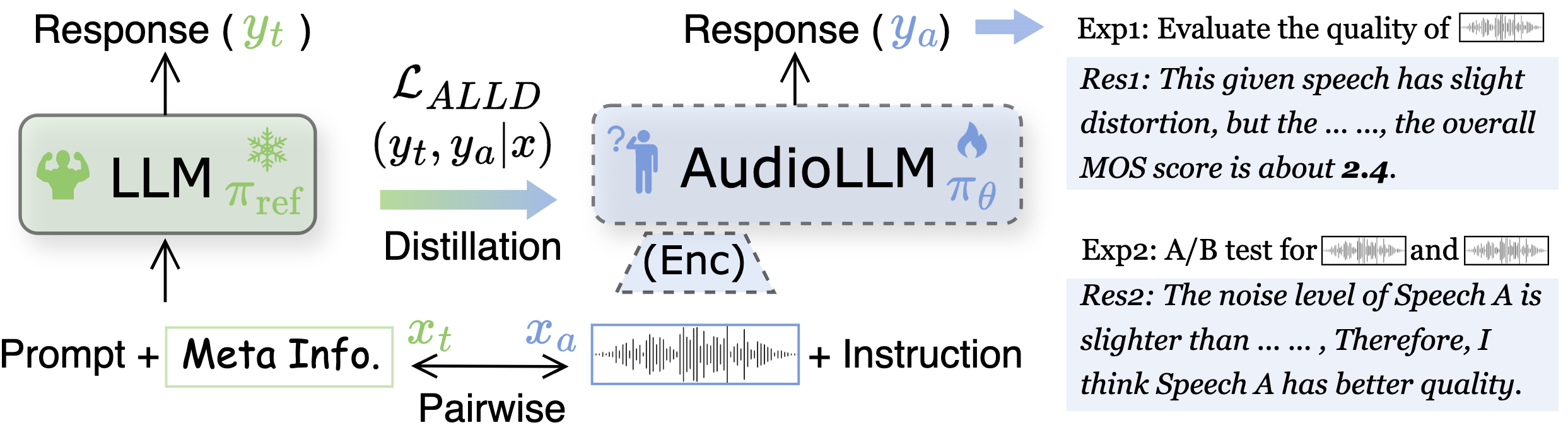
核心思路:论文的核心思路是构建一个包含人工评分的自然语言语音评估语料库,并利用该语料库对音频LLM进行训练,使其能够感知和评估语音质量。通过LLM蒸馏对齐(ALLD)方法,将语音质量评估知识从教师模型迁移到学生模型,从而提升学生模型的性能。
技术框架:ALLD方法包含以下几个主要步骤:1) 构建自然语言语音评估语料库,包含MOS评分、多维度质量分析和A/B测试结果;2) 使用该语料库训练一个教师模型,使其能够预测MOS评分并生成描述性文本;3) 使用教师模型生成的数据对音频LLM(学生模型)进行蒸馏训练,使其能够学习语音质量评估知识;4) 对学生模型进行微调,以进一步提升其性能。
关键创新:论文的关键创新在于:1) 提出了首个基于自然语言的语音评估语料库,填补了该领域的空白;2) 提出了ALLD方法,将LLM蒸馏应用于语音质量评估任务,有效提升了模型性能;3) 实现了音频LLM对语音质量的全面感知,使其能够生成高质量的描述性文本。
关键设计:在ALLD方法中,关键设计包括:1) 语料库的构建方式,确保数据质量和多样性;2) 教师模型的选择和训练,使其能够准确预测MOS评分并生成有意义的描述性文本;3) 蒸馏损失函数的设计,用于指导学生模型学习教师模型的知识;4) 微调策略的选择,以进一步提升学生模型的性能。具体参数设置和网络结构细节在论文正文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
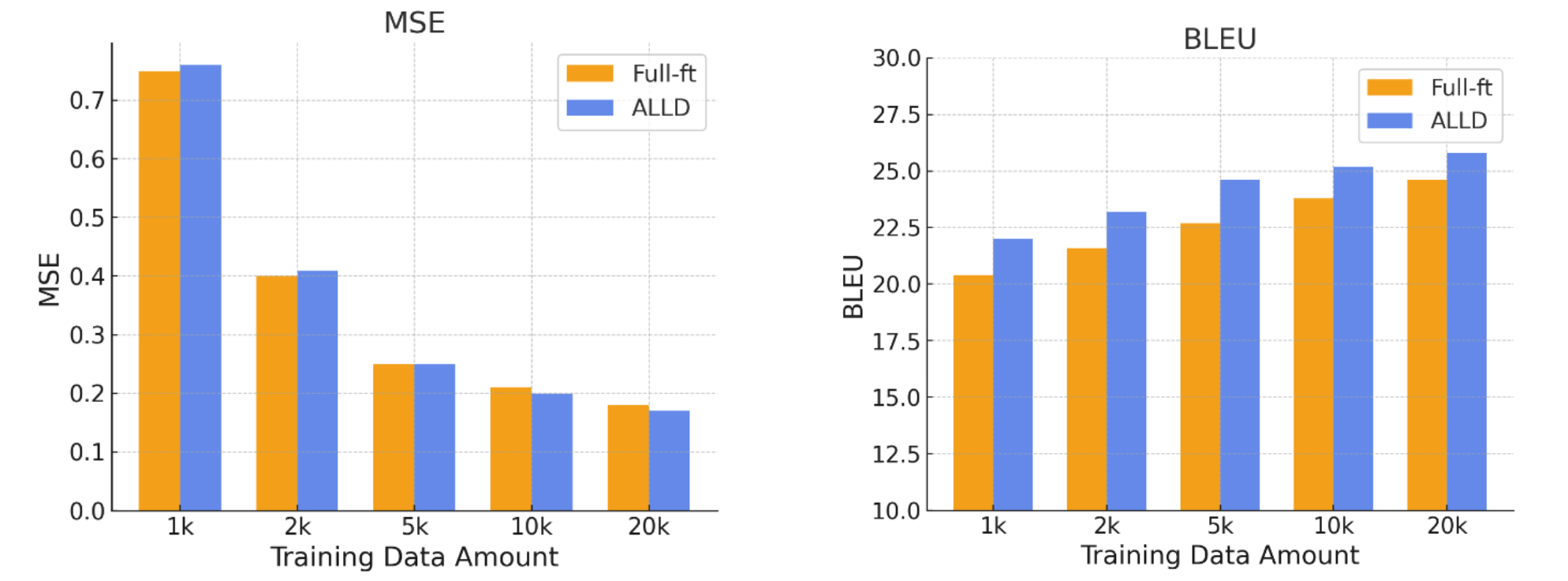
实验结果表明,ALLD方法在MOS预测方面优于先前的最先进回归模型,均方误差降低至0.17。在A/B测试中,ALLD方法取得了98.6%的准确率。此外,ALLD方法生成的响应在两项任务中分别实现了25.8和30.2的BLEU分数,超越了特定任务模型的能力。这些结果表明,ALLD方法能够有效提升音频LLM在语音质量评估任务中的性能。
🎯 应用场景
该研究成果可应用于语音通信、语音识别、语音合成等领域。例如,在语音通信中,可以利用该技术评估语音质量,并根据质量调整传输策略,提升用户体验。在语音识别中,可以利用该技术过滤低质量语音,提高识别准确率。在语音合成中,可以利用该技术评估合成语音的质量,并优化合成算法,生成更自然的语音。未来,该技术有望应用于智能助手、语音交互等领域,提升人机交互的质量。
📄 摘要(原文)
An ideal multimodal agent should be aware of the quality of its input modalities. Recent advances have enabled large language models (LLMs) to incorporate auditory systems for handling various speech-related tasks. However, most audio LLMs remain unaware of the quality of the speech they process. This limitation arises because speech quality evaluation is typically excluded from multi-task training due to the lack of suitable datasets. To address this, we introduce the first natural language-based speech evaluation corpus, generated from authentic human ratings. In addition to the overall Mean Opinion Score (MOS), this corpus offers detailed analysis across multiple dimensions and identifies causes of quality degradation. It also enables descriptive comparisons between two speech samples (A/B tests) with human-like judgment. Leveraging this corpus, we propose an alignment approach with LLM distillation (ALLD) to guide the audio LLM in extracting relevant information from raw speech and generating meaningful responses. Experimental results demonstrate that ALLD outperforms the previous state-of-the-art regression model in MOS prediction, with a mean square error of 0.17 and an A/B test accuracy of 98.6%. Additionally, the generated responses achieve BLEU scores of 25.8 and 30.2 on two tasks, surpassing the capabilities of task-specific models. This work advances the comprehensive perception of speech signals by audio LLMs, contributing to the development of real-world auditory and sensory intelligent agents.