Large Language Models to Diffusion Finetuning
作者: Edoardo Cetin, Tianyu Zhao, Yujin Tang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-27 (更新: 2025-06-03)
备注: Camera-ready version, presented at ICML 2025. Code available at: https://github.com/SakanaAI/L2D
💡 一句话要点
提出一种新的微调方法,使大型语言模型能够通过扩散框架扩展测试时计算能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 扩散模型 微调 自适应计算 ODE求解器
📋 核心要点
- 现有大型语言模型在测试时计算能力扩展方面存在局限性,难以根据任务复杂度调整计算资源。
- 该论文提出利用扩散框架微调大型语言模型,通过增加扩散步骤来提升模型在下游任务中的性能。
- 实验结果表明,该方法能够提高模型准确率,并使其具备根据问题自适应调整计算量的能力。
📝 摘要(中文)
本文提出了一种新的微调方法,使预训练的大型语言模型(LMs)能够通过扩散框架扩展测试时计算能力。通过增加扩散步骤的数量,我们证明了经过微调的模型可以实现单调递增的准确率,直接转化为下游任务性能的提升。此外,通过整合强大的引导技术,我们微调后的模型可以专业地回答特定主题的问题,并通过利用自适应ODE求解器自主地确定给定问题所需的计算量。我们的方法普遍适用于任何使用交叉熵损失预训练的基础模型,并且不修改其任何原始权重,完全保留其强大的单步生成能力。我们证明了我们的方法更有效,并且与传统的微调方法完全兼容,为统一自回归和扩散框架的优势引入了一个正交的新方向。
🔬 方法详解
问题定义:现有的大型语言模型在推理时,计算量通常是固定的,无法根据任务的难度进行调整。对于简单的任务,过多的计算造成了资源浪费;而对于复杂的任务,固定的计算量可能无法达到理想的性能。因此,如何使大型语言模型能够根据任务的复杂度自适应地调整计算量,是一个重要的研究问题。
核心思路:该论文的核心思路是将大型语言模型与扩散模型相结合,利用扩散模型的迭代特性来扩展模型的计算能力。通过将大型语言模型的输出作为扩散过程的初始状态,并增加扩散步骤的数量,可以逐步提高模型的准确率。同时,利用自适应ODE求解器,可以根据任务的复杂度动态地调整扩散步骤的数量,从而实现计算量的自适应调整。
技术框架:该方法主要包含两个阶段:微调阶段和推理阶段。在微调阶段,使用交叉熵损失函数对预训练的大型语言模型进行微调,使其能够生成扩散过程的初始状态。在推理阶段,首先使用微调后的模型生成扩散过程的初始状态,然后通过迭代的扩散步骤逐步提高模型的准确率。同时,使用自适应ODE求解器来动态地调整扩散步骤的数量。
关键创新:该论文的关键创新在于将大型语言模型与扩散模型相结合,并利用自适应ODE求解器来实现计算量的自适应调整。与传统的微调方法相比,该方法可以在不修改原始模型权重的情况下,显著提高模型的性能。此外,该方法还引入了一种新的正交方向,可以统一自回归和扩散框架的优势。
关键设计:该方法的关键设计包括:1) 使用交叉熵损失函数进行微调;2) 将大型语言模型的输出作为扩散过程的初始状态;3) 使用自适应ODE求解器来动态地调整扩散步骤的数量。具体的参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
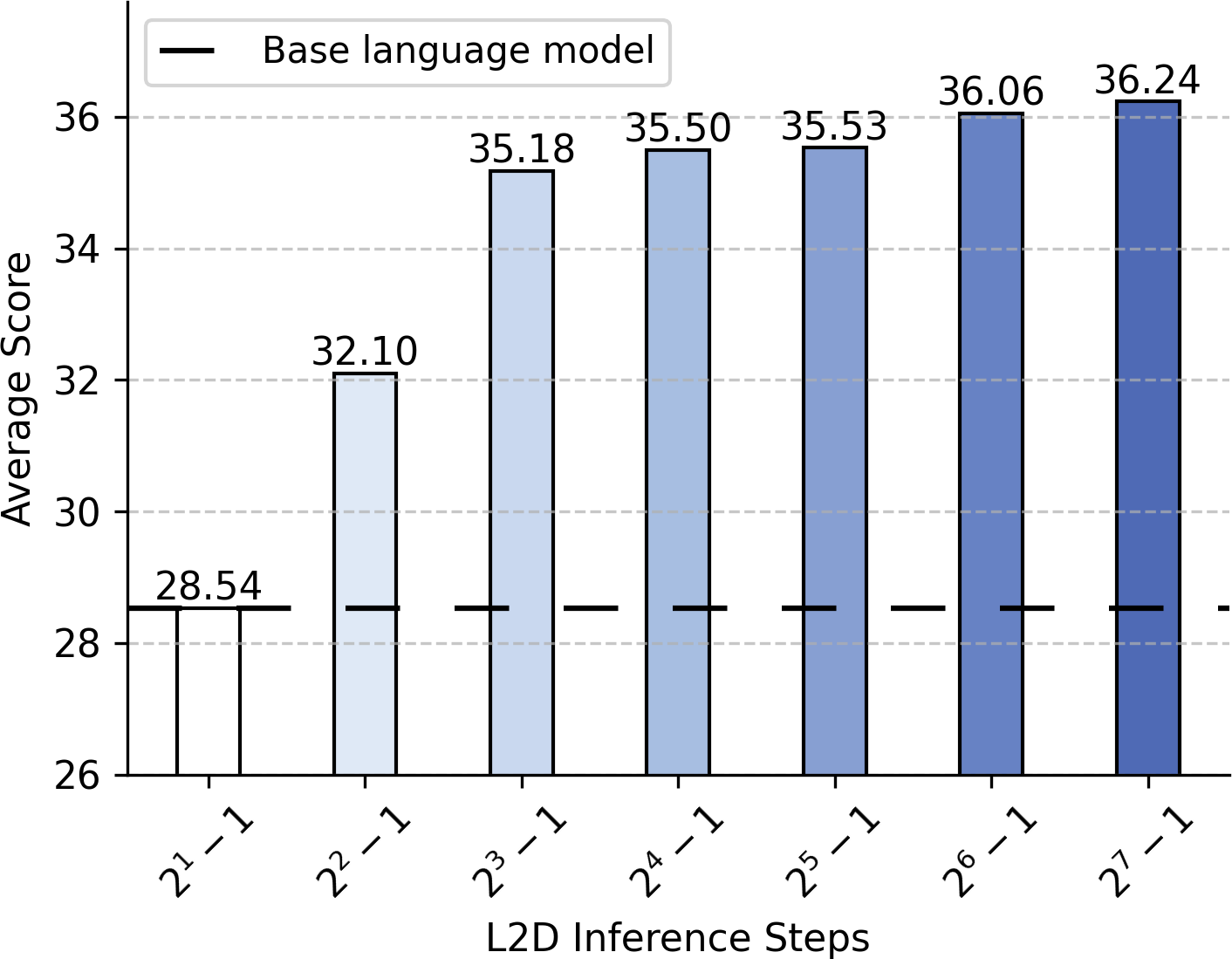


📊 实验亮点
该论文提出的方法能够使大型语言模型在下游任务中实现单调递增的准确率,并通过整合强大的引导技术,使模型能够专业地回答特定主题的问题。此外,模型还能够自主地确定给定问题所需的计算量,从而实现计算资源的有效利用。具体的性能提升数据和对比基线在摘要中未提供,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要大型语言模型进行推理的任务中,例如问答系统、文本生成、机器翻译等。通过自适应调整计算量,可以提高模型的效率和准确率,降低计算成本。未来,该方法有望在资源受限的设备上部署大型语言模型,并促进人工智能技术的普及。
📄 摘要(原文)
We propose a new finetuning method to provide pre-trained large language models (LMs) the ability to scale test-time compute through the diffusion framework. By increasing the number of diffusion steps, we show our finetuned models achieve monotonically increasing accuracy, directly translating to improved performance across downstream tasks. Furthermore, our finetuned models can expertly answer questions on specific topics by integrating powerful guidance techniques, and autonomously determine the compute required for a given problem by leveraging adaptive ODE solvers. Our method is universally applicable to any foundation model pre-trained with a cross-entropy loss and does not modify any of its original weights, fully preserving its strong single-step generation capabilities. We show our method is more effective and fully compatible with traditional finetuning approaches, introducing an orthogonal new direction to unify the strengths of the autoregressive and diffusion frameworks.