SEAL: Speech Embedding Alignment Learning for Speech Large Language Model with Retrieval-Augmented Generation
作者: Chunyu Sun, Bingyu Liu, Zhichao Cui, Junhan Shi, Anbin Qi, Tian-hao Zhang, Dinghao Zhou, Lewei Lu
分类: eess.AS, cs.CL, cs.SD
发布日期: 2025-01-26 (更新: 2025-12-10)
💡 一句话要点
提出SEAL:通过语音嵌入对齐学习实现语音大语言模型的检索增强生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大语言模型 检索增强生成 语音嵌入 跨模态检索 语音识别 嵌入对齐
📋 核心要点
- 现有SLLM的RAG方法依赖ASR和文本检索的两阶段流程,存在高延迟和误差传递的问题。
- SEAL提出统一的嵌入框架,通过语音和文本编码器及共享缩放层,将两种模态映射到公共嵌入空间。
- 实验表明,SEAL在提高检索精度的同时,将流水线延迟降低了50%,并具有良好的鲁棒性。
📝 摘要(中文)
本文提出了一种用于语音大语言模型(SLLM)的检索增强生成(RAG)的语音嵌入对齐学习框架(SEAL)。现有的基于嵌入的检索模型在文本和多模态大语言模型应用中取得了显著进展,但应用于SLLM时,通常依赖于自动语音识别(ASR)与文本检索的两阶段流程,导致高延迟和误差传递。为了解决这些问题,SEAL提出了一个统一的嵌入框架,消除了对中间文本表示的需求。该框架包含独立的语音和文本编码器,以及一个共享的缩放层,将两种模态映射到公共嵌入空间。实验结果表明,该模型在实现更高检索精度的同时,将流水线延迟降低了50%。此外,本文还对端到端语音检索的挑战进行了理论分析,并提出了有效语音-文档匹配的架构原则。大量的实验证明了该方法在不同声学条件和说话人变化下的鲁棒性,为多模态SLLM检索系统开辟了新的范例。
🔬 方法详解
问题定义:现有语音大语言模型(SLLM)的检索增强生成(RAG)方法,通常采用两阶段流程:首先使用自动语音识别(ASR)将语音转换为文本,然后使用文本检索技术进行文档检索。这种方法的主要痛点在于:一是引入了额外的延迟,因为需要先进行语音识别;二是ASR的错误会传递到后续的检索阶段,影响检索的准确性。
核心思路:SEAL的核心思路是消除对中间文本表示的依赖,直接在语音和文本的嵌入空间中进行检索。通过学习一个公共的嵌入空间,使得语义相似的语音和文本片段在该空间中的距离更近。这样,可以直接使用语音查询来检索相关的文档,避免了ASR带来的延迟和错误。
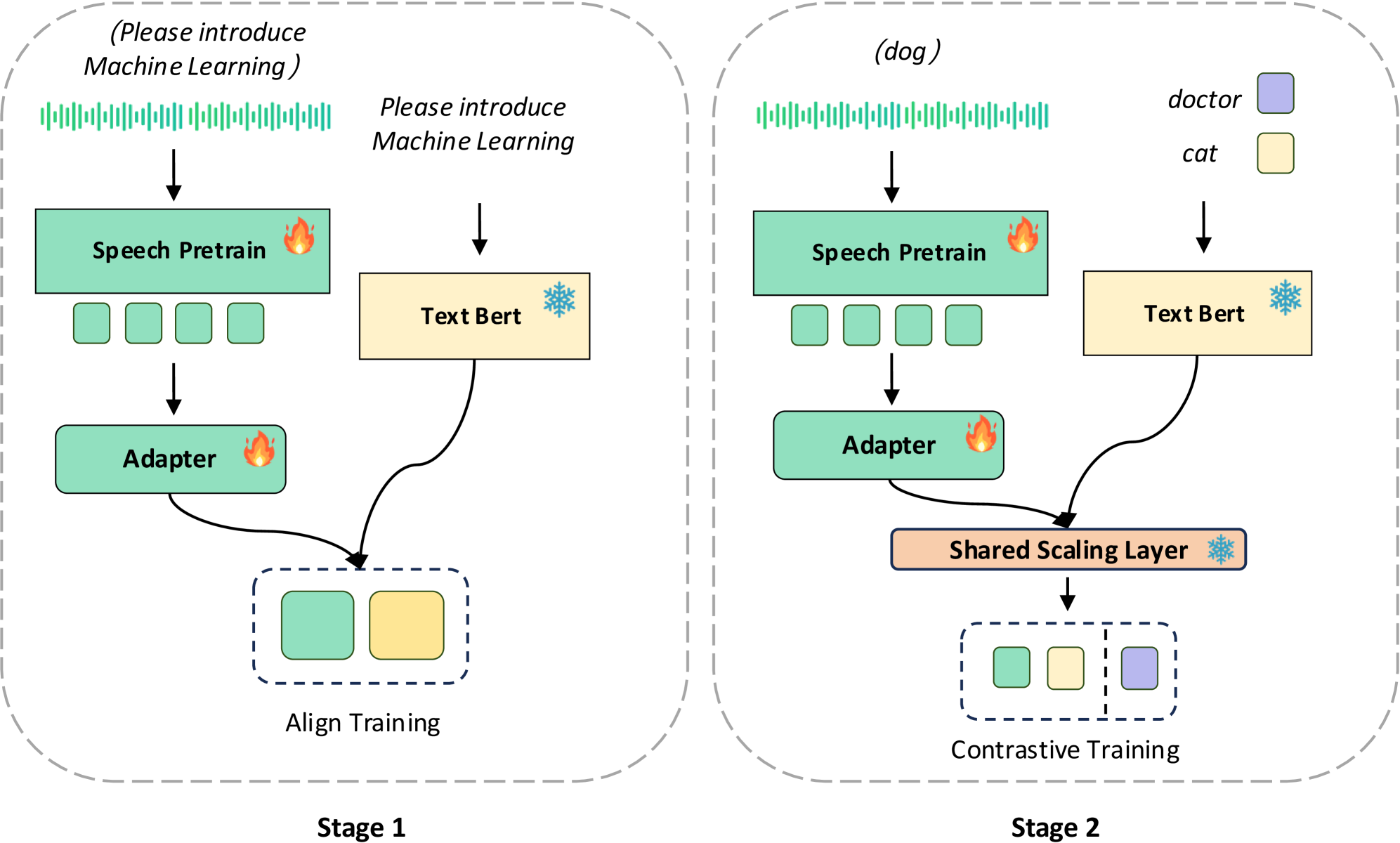
技术框架:SEAL框架包含以下几个主要模块:1) 语音编码器:将输入的语音信号转换为语音嵌入向量。2) 文本编码器:将输入的文本转换为文本嵌入向量。3) 共享缩放层:将语音和文本嵌入向量映射到公共的嵌入空间。4) 检索模块:在公共嵌入空间中,根据语音查询的嵌入向量,检索最相关的文档嵌入向量。整个流程无需经过ASR环节,实现了端到端的语音检索。
关键创新:SEAL最重要的技术创新点在于提出了一个统一的嵌入框架,能够直接在语音和文本的嵌入空间中进行检索,避免了传统方法中ASR的误差传递和延迟。与现有方法的本质区别在于,SEAL不再依赖于中间的文本表示,而是直接学习语音和文本之间的语义关系。
关键设计:SEAL的关键设计包括:1) 语音和文本编码器的选择:可以使用预训练的语音和文本模型,如HuBERT和BERT,也可以根据具体任务进行微调。2) 共享缩放层的设计:可以使用线性层或非线性层,将语音和文本嵌入向量映射到公共嵌入空间。3) 损失函数的设计:可以使用对比学习损失或三元组损失,使得语义相似的语音和文本片段在公共嵌入空间中的距离更近。4) 负样本的选择:在训练过程中,需要选择合适的负样本,以提高模型的区分能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SEAL在检索精度上优于传统的两阶段方法,并且将流水线延迟降低了50%。具体来说,SEAL在多个语音检索数据集上取得了显著的性能提升,证明了其在不同声学条件和说话人变化下的鲁棒性。这些结果表明,SEAL为多模态SLLM检索系统提供了一种新的有效范例。
🎯 应用场景
SEAL技术可广泛应用于语音助手、智能客服、语音搜索等领域。例如,用户可以通过语音提问,快速检索到相关的文档或信息,无需手动输入文本。该技术还可以应用于多语言场景,实现跨语言的语音检索。未来,SEAL有望成为构建更高效、更智能的语音交互系统的关键技术。
📄 摘要(原文)
Embedding-based retrieval models have made significant strides in retrieval-augmented generation (RAG) techniques for text and multimodal large language models (LLMs) applications. However, when it comes to speech larage language models (SLLMs), these methods are limited to a two-stage process, where automatic speech recognition (ASR) is combined with text-based retrieval. This sequential architecture suffers from high latency and error propagation. To address these limitations, we propose a unified embedding framework that eliminates the need for intermediate text representations. Specifically, the framework includes separate speech and text encoders, followed by a shared scaling layer that maps both modalities into a common embedding space. Our model reduces pipeline latency by 50\% while achieving higher retrieval accuracy compared to traditional two-stage methods. We also provide a theoretical analysis of the challenges inherent in end-to-end speech retrieval and introduce architectural principles for effective speech-to-document matching. Extensive experiments demonstrate the robustness of our approach across diverse acoustic conditions and speaker variations, paving the way for a new paradigm in multimodal SLLMs retrieval systems.