TensorLLM: Tensorising Multi-Head Attention for Enhanced Reasoning and Compression in LLMs
作者: Yuxuan Gu, Wuyang Zhou, Giorgos Iacovides, Danilo Mandic
分类: cs.CL, cs.LG
发布日期: 2025-01-26 (更新: 2025-05-15)
备注: Accpeted for IEEE International Joint Conference on Neural Networks (IJCNN 2025). The code is available at https://github.com/guyuxuan9/TensorLLM
💡 一句话要点
TensorLLM:通过张量化多头注意力提升LLM推理能力与压缩率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多头注意力 张量分解 模型压缩 模型去噪 推理加速 Tucker分解
📋 核心要点
- 现有LLM权重去噪方法主要关注Transformer中的FFN,忽略了核心的MHA模块,导致模型推理能力提升受限。
- 论文提出TensorLLM框架,通过多头张量化和Tucker分解压缩MHA权重,实现更高维度的结构化去噪。
- 实验表明,TensorLLM在提升LLM推理能力的同时,实现了高达250倍的MHA权重压缩,且无需额外训练数据。
📝 摘要(中文)
大型语言模型(LLM)的推理能力可以通过对其权重进行结构化去噪来提高。然而,现有技术主要集中在Transformer块的前馈网络(FFN)去噪上,无法有效利用多头注意力(MHA)块,而MHA是Transformer架构的核心。为了解决这个问题,我们提出了一个新颖的直观框架,其核心是通过多头张量化过程和Tucker分解执行MHA压缩。这通过在多个注意力头的权重之间强制执行共享的高维子空间,实现了MHA权重更高维度的结构化去噪和压缩。我们证明,这种方法始终如一地增强了LLM在多个基准数据集上的推理能力,适用于仅编码器和仅解码器架构,同时在MHA权重中实现了高达约250倍的压缩率,所有这些都不需要任何额外的数据、训练或微调。此外,我们表明,所提出的方法可以与现有的仅基于FFN的去噪技术无缝结合,以进一步提高LLM的推理性能。
🔬 方法详解
问题定义:现有的大型语言模型压缩和优化方法,主要集中在Transformer结构中的前馈神经网络(FFN)层,而忽略了多头注意力(MHA)层。MHA层是Transformer的核心,其权重参数量巨大,但缺乏有效的结构化去噪和压缩方法,限制了模型推理能力的提升和部署效率。
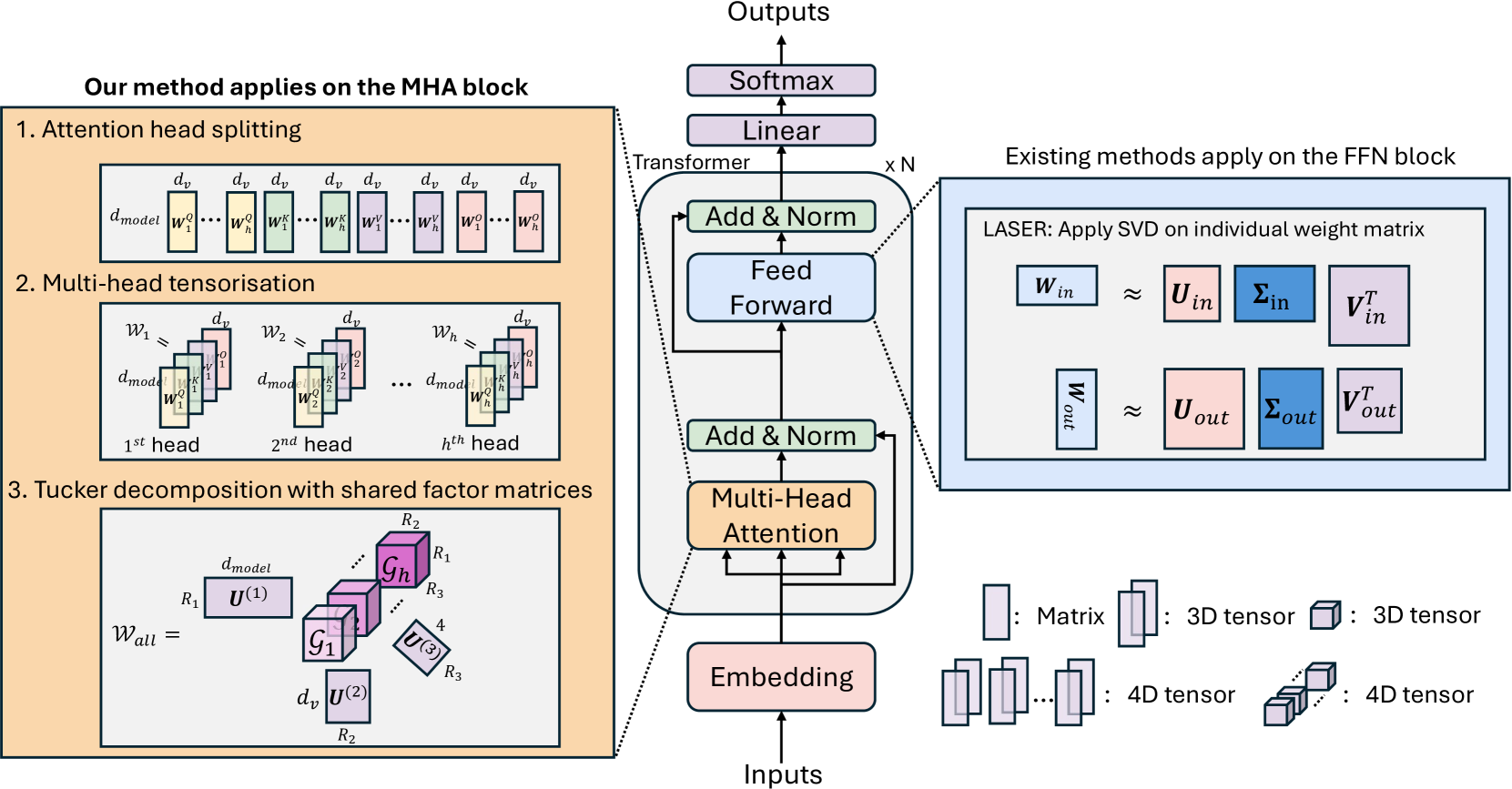
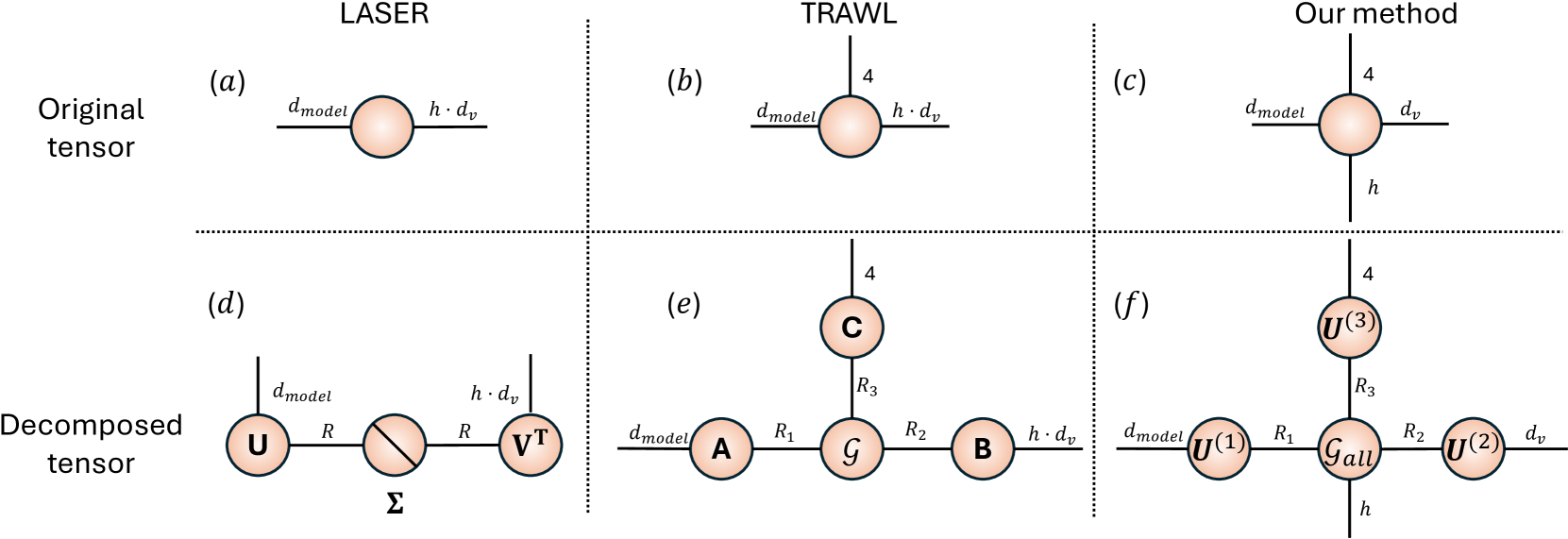
核心思路:论文的核心思路是通过张量分解的方式,对MHA层的权重进行结构化压缩和去噪。具体而言,将多个注意力头的权重视为一个高阶张量,并利用Tucker分解提取共享的低秩子空间。通过在共享子空间上进行操作,可以实现对MHA权重的高效压缩和结构化去噪,从而提升模型的推理能力。
技术框架:TensorLLM框架主要包含以下几个阶段:1) MHA权重张量化:将MHA层的多个注意力头的权重组织成一个高阶张量。2) Tucker分解:对该张量进行Tucker分解,得到核心张量和因子矩阵。核心张量代表了MHA权重中的共享信息,因子矩阵则代表了每个注意力头在该共享空间上的投影。3) 权重重构:利用分解后的核心张量和因子矩阵重构MHA权重。通过控制核心张量的秩,可以实现对MHA权重的压缩。4) 模型推理:将压缩后的MHA权重应用到LLM中进行推理。
关键创新:该方法最重要的创新点在于提出了基于张量分解的MHA权重压缩和去噪方法。与传统的权重剪枝或量化方法不同,TensorLLM通过提取MHA权重中的共享结构,实现了更高维度的结构化去噪,从而在压缩模型的同时,提升了模型的推理能力。此外,该方法无需额外的训练数据或微调,可以直接应用于预训练的LLM。
关键设计:在Tucker分解中,核心张量的秩是一个关键参数,它控制了模型的压缩率和性能。论文通过实验分析了不同秩对模型性能的影响,并提出了选择合适秩的策略。此外,论文还探讨了将TensorLLM与现有的FFN层去噪方法相结合的可能性,实验结果表明,两者可以相互补充,进一步提升模型的推理性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TensorLLM在多个基准数据集上显著提升了LLM的推理能力,同时实现了高达250倍的MHA权重压缩。例如,在某些数据集上,TensorLLM可以将模型的准确率提高1-2个百分点,同时将MHA权重的大小减少到原来的1/250。此外,TensorLLM与现有FFN去噪技术结合使用时,可以进一步提高LLM的推理性能。
🎯 应用场景
TensorLLM具有广泛的应用前景,可用于压缩和加速大型语言模型,降低部署成本,并提升模型在资源受限设备上的推理性能。该方法尤其适用于对推理速度和模型大小有较高要求的场景,如移动设备、边缘计算和嵌入式系统。此外,TensorLLM还可以作为一种通用的模型压缩和去噪技术,应用于其他基于Transformer的深度学习模型。
📄 摘要(原文)
The reasoning abilities of Large Language Models (LLMs) can be improved by structurally denoising their weights, yet existing techniques primarily focus on denoising the feed-forward network (FFN) of the transformer block, and can not efficiently utilise the Multi-head Attention (MHA) block, which is the core of transformer architectures. To address this issue, we propose a novel intuitive framework that, at its very core, performs MHA compression through a multi-head tensorisation process and the Tucker decomposition. This enables both higher-dimensional structured denoising and compression of the MHA weights, by enforcing a shared higher-dimensional subspace across the weights of the multiple attention heads. We demonstrate that this approach consistently enhances the reasoning capabilities of LLMs across multiple benchmark datasets, and for both encoder-only and decoder-only architectures, while achieving compression rates of up to $\sim 250$ times in the MHA weights, all without requiring any additional data, training, or fine-tuning. Furthermore, we show that the proposed method can be seamlessly combined with existing FFN-only-based denoising techniques to achieve further improvements in LLM reasoning performance.