SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain
作者: Dakuan Lu, Xiaoyu Tan, Rui Xu, Tianchu Yao, Chao Qu, Wei Chu, Yinghui Xu, Yuan Qi
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-01-26 (更新: 2025-08-24)
备注: 9 pages, 1 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出SCP-116K:一个高质量的理科高等教育领域问题-解答数据集,以及通用的自动抽取流程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学推理 问题解答数据集 大型语言模型 自动抽取 高等教育 STEM教育 知识工程
📋 核心要点
- 高等教育科学领域缺乏高质量的问题-解答数据集,限制了LLM在科学推理方面的发展。
- 论文提出SCP-116K数据集,并设计通用自动抽取流程,从异构数据源构建大规模高质量数据集。
- SCP-116K包含116,756个问题-解答对,旨在促进科学推理研究和LLM性能评估。
📝 摘要(中文)
大型语言模型(LLM)的最新突破,特别是o1模型在数学和科学推理方面的卓越能力,突显了高质量训练数据在提升LLM在STEM学科性能方面的关键作用。虽然数学领域已经受益于越来越多的精选数据集,但高等教育水平的科学领域长期以来一直缺乏类似资源。为了解决这一差距,我们提出了SCP-116K,这是一个新的大规模数据集,包含116,756个高质量的问题-解答对,这些数据对使用精简且高度通用的流程从异构来源自动提取。我们的方法涉及严格的过滤,以确保提取材料的科学严谨性和教育水平,同时保持适应未来扩展或领域转移的能力。通过公开数据集和提取流程,我们旨在促进科学推理研究,实现对新LLM的全面性能评估,并降低在更广泛的科学界复制o1等先进模型成功的门槛。我们相信SCP-116K将成为一个关键资源,促进高水平科学推理任务的进展,并促进LLM开发的进一步创新。数据集和代码可在https://github.com/AQA6666/SCP-116K-open公开获取。
🔬 方法详解
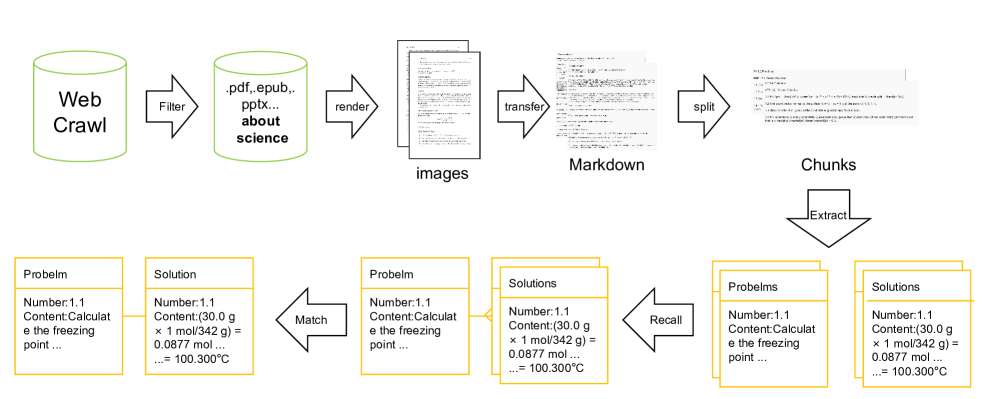
问题定义:现有高等教育科学领域缺乏大规模、高质量的问题-解答数据集,这阻碍了大型语言模型在科学推理能力上的发展。已有的数学数据集相对丰富,但科学领域的数据集构建面临异构数据源、知识严谨性以及教育水平等多重挑战。
核心思路:论文的核心思路是构建一个通用的、可扩展的自动抽取流程,从各种异构数据源中提取高质量的问题-解答对。通过严格的过滤和筛选机制,确保提取的数据在科学性和教育水平上都符合要求,从而为训练和评估科学推理LLM提供可靠的数据基础。
技术框架:该方法包含数据抽取、清洗、过滤和验证等主要阶段。首先,从各种在线资源和教育平台抓取原始数据。然后,利用自然语言处理技术对数据进行清洗和结构化,提取潜在的问题和解答。接着,通过一系列规则和模型对问题-解答对进行过滤,去除不相关、不准确或难度不符合要求的数据。最后,人工抽查验证数据集的质量。
关键创新:该方法的关键创新在于其通用性和可扩展性。通过模块化的设计和灵活的配置,该流程可以适应不同的数据源和领域。此外,论文提出的过滤机制能够有效地去除噪声数据,保证数据集的质量。
关键设计:过滤机制是关键设计之一,它包括基于关键词的过滤、基于规则的过滤和基于模型的过滤。基于关键词的过滤用于去除包含敏感词汇或与目标领域无关的数据。基于规则的过滤利用预定义的规则来检查问题和解答的格式、完整性和一致性。基于模型的过滤则使用预训练的语言模型来评估问题和解答的语义相关性和难度。
🖼️ 关键图片
📊 实验亮点
SCP-116K数据集包含116,756个高质量问题-解答对,规模远大于现有科学领域数据集。通过严格的过滤和验证,确保了数据集的科学严谨性和教育水平。论文提出的自动抽取流程具有良好的通用性和可扩展性,可以方便地应用于其他科学领域。
🎯 应用场景
SCP-116K数据集可用于训练和评估大型语言模型在科学推理、问题求解和知识理解方面的能力。该数据集能够促进智能教育系统的发展,例如智能辅导系统、自动答疑系统等。此外,该数据集还可以用于研究科学知识的表示和推理方法,推动人工智能在科学领域的应用。
📄 摘要(原文)
Recent breakthroughs in large language models (LLMs) exemplified by the impressive mathematical and scientific reasoning capabilities of the o1 model have spotlighted the critical importance of high-quality training data in advancing LLM performance across STEM disciplines. While the mathematics community has benefited from a growing body of curated datasets, the scientific domain at the higher education level has long suffered from a scarcity of comparable resources. To address this gap, we present SCP-116K, a new large-scale dataset of 116,756 high-quality problem-solution pairs, automatically extracted from heterogeneous sources using a streamlined and highly generalizable pipeline. Our approach involves stringent filtering to ensure the scientific rigor and educational level of the extracted materials, while maintaining adaptability for future expansions or domain transfers. By openly releasing both the dataset and the extraction pipeline, we seek to foster research on scientific reasoning, enable comprehensive performance evaluations of new LLMs, and lower the barrier to replicating the successes of advanced models like o1 in the broader science community. We believe SCP-116K will serve as a critical resource, catalyzing progress in high-level scientific reasoning tasks and promoting further innovations in LLM development. The dataset and code are publicly available at https://github.com/AQA6666/SCP-116K-open.