Error Classification of Large Language Models on Math Word Problems: A Dynamically Adaptive Framework
作者: Yuhong Sun, Zhangyue Yin, Xuanjing Huang, Xipeng Qiu, Hui Zhao
分类: cs.CL
发布日期: 2025-01-26 (更新: 2025-09-08)
备注: 28 pages, 10 figures, accepted by Findings of EMNLP2025
💡 一句话要点
提出动态自适应框架,用于大规模语言模型在数学应用题上的错误分类。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学应用题 错误分类 动态自适应 错误感知提示
📋 核心要点
- 现有数学应用题错误分析方法依赖静态类别,无法全面捕捉LLM的错误模式。
- 提出动态自适应框架,自动进行细粒度的错误分类,减少人为偏差。
- 构建包含30万错误样本的数据集MWPES-300K,并提出错误感知提示EAP,提升推理性能。
📝 摘要(中文)
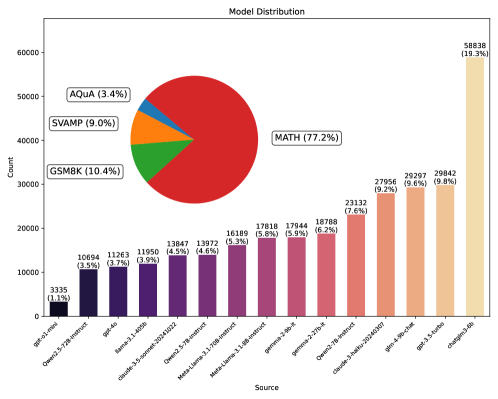
大型语言模型(LLMs)在各个领域展现了卓越的能力。数学应用题(MWPs)是评估LLMs推理能力的关键基准。现有研究主要集中在提高准确性,而忽略了理解和解决潜在的错误模式。目前的错误分类方法依赖于静态和预定义的类别,限制了它们捕捉数学推理中完整错误模式的能力。为了实现系统的错误分析,我们从15个不同大小的LLMs中,使用多种抽样策略,跨四个不同的MWP数据集收集了错误样本。基于此,我们引入了MWPES-300K,一个包含304,865个错误样本的综合数据集,涵盖了不同的错误模式和推理路径。为了减少人为偏差并实现对错误模式的细粒度分析,我们提出了一种用于数学推理中自动动态错误分类的新框架。实验结果表明,数据集特征显著影响错误模式,并且随着模型能力的提高,错误模式从基本表现形式演变为复杂表现形式。通过对错误模式的深入了解,我们提出了错误感知提示(EAP),它将常见的错误模式作为显式指导,从而显著提高了数学推理性能。
🔬 方法详解
问题定义:现有的大型语言模型在解决数学应用题时,虽然取得了显著进展,但仍然存在各种各样的错误。现有的错误分类方法通常依赖于预定义的、静态的类别,这些类别无法充分捕捉到模型在数学推理过程中产生的复杂和动态的错误模式。此外,人工定义的错误类别容易引入主观偏差,限制了错误分析的客观性和细粒度。
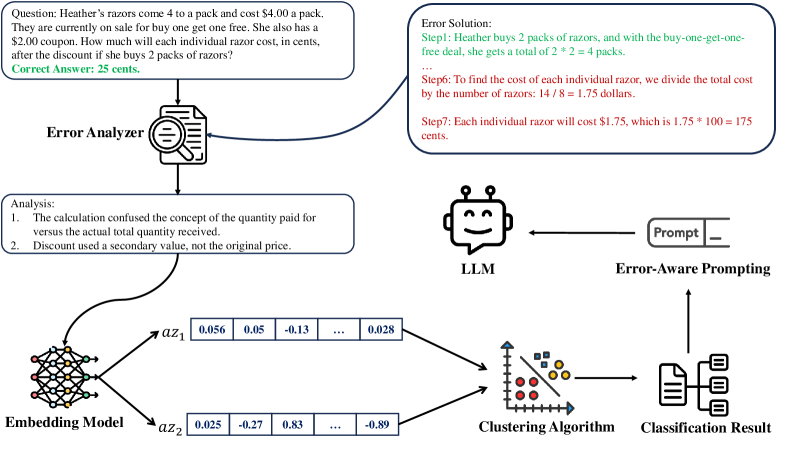
核心思路:本文的核心思路是构建一个动态自适应的错误分类框架,该框架能够自动地识别和分类LLM在解决数学应用题时产生的错误。通过对大量错误样本进行分析,该框架能够学习到不同类型的错误模式,并根据模型的能力和数据集的特点动态地调整错误分类的策略。这种动态自适应的方法能够更全面、更客观地捕捉到LLM的错误模式,为后续的错误纠正和模型改进提供更有效的指导。
技术框架:该框架主要包含以下几个阶段:1) 错误样本收集:从多个LLM和多个MWP数据集中收集大量的错误样本。2) 特征提取:从错误样本中提取相关的特征,例如模型的预测结果、正确的答案、以及问题本身的特征。3) 动态错误分类:使用机器学习或深度学习模型,根据提取的特征对错误样本进行分类。该分类过程是动态的,可以根据模型的能力和数据集的特点进行调整。4) 错误模式分析:对分类结果进行分析,识别出常见的错误模式,并分析这些错误模式产生的原因。
关键创新:该论文的关键创新在于提出了一个动态自适应的错误分类框架,该框架能够自动地识别和分类LLM在解决数学应用题时产生的错误。与现有的静态错误分类方法相比,该框架能够更全面、更客观地捕捉到LLM的错误模式,并为后续的错误纠正和模型改进提供更有效的指导。此外,该论文还构建了一个包含30万错误样本的大规模数据集MWPES-300K,为错误分析和模型改进提供了宝贵的数据资源。
关键设计:在动态错误分类阶段,可以使用各种机器学习或深度学习模型,例如聚类算法、分类算法、或神经网络。关键的设计在于如何选择合适的特征,以及如何设计动态调整分类策略的机制。例如,可以根据模型的能力和数据集的特点,动态地调整特征的权重,或者动态地调整分类的阈值。此外,还可以使用强化学习的方法,训练一个能够自动调整分类策略的智能体。
🖼️ 关键图片

📊 实验亮点
实验结果表明,数据集特征显著影响错误模式,且错误模式随模型能力提升而演变。提出的错误感知提示(EAP)通过将常见错误模式作为显式指导,显著提高了数学推理性能。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于提升大型语言模型在数学推理任务中的准确性和可靠性。通过深入理解和解决LLM的错误模式,可以开发更有效的错误纠正机制和模型改进策略,从而提高LLM在教育、金融、科学研究等领域的应用价值。此外,该研究提出的动态错误分类框架也可以推广到其他自然语言处理任务中。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains. Math Word Problems (MWPs) serve as a crucial benchmark for evaluating LLMs' reasoning abilities. While most research primarily focuses on improving accuracy, it often neglects understanding and addressing the underlying patterns of errors. Current error classification methods rely on static and predefined categories, which limit their ability to capture the full spectrum of error patterns in mathematical reasoning. To enable systematic error analysis, we collect error samples from 15 different LLMs of varying sizes across four distinct MWP datasets using multiple sampling strategies. Based on this extensive collection, we introduce MWPES-300K, a comprehensive dataset containing 304,865 error samples that cover diverse error patterns and reasoning paths. To reduce human bias and enable fine-grained analysis of error patterns, we propose a novel framework for automated dynamic error classification in mathematical reasoning. Experimental results demonstrate that dataset characteristics significantly shape error patterns, which evolve from basic to complex manifestations as model capabilities increase. With deeper insights into error patterns, we propose Error-Aware Prompting (EAP) that incorporates common error patterns as explicit guidance, leading to significant improvements in mathematical reasoning performance.