Evaluating the Effectiveness of XAI Techniques for Encoder-Based Language Models
作者: Melkamu Abay Mersha, Mesay Gemeda Yigezu, Jugal Kalita
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2025-01-26
期刊: 310(2025)113042
DOI: 10.1016/j.knosys.2025.113042
💡 一句话要点
评估XAI技术在Encoder语言模型中的有效性,LIME表现突出
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释AI XAI 语言模型 评估框架 模型简化 LIME 鲁棒性 一致性
📋 核心要点
- 大型语言模型的黑盒性是挑战,需要可解释AI技术来提高透明度和可信度。
- 论文提出通用评估框架,包含人类推理一致性、鲁棒性、一致性和对比性四个关键指标。
- 实验结果表明,LIME方法在多个指标和模型中表现优异,尤其在人类推理一致性方面。
📝 摘要(中文)
大型语言模型(LLM)的黑盒特性,促使人们开发可解释AI(XAI)技术以提高透明度和可信度。然而,评估这些技术仍然是一个挑战。本研究提出了一个通用的评估框架,使用四个关键指标:人类推理一致性(HA)、鲁棒性、一致性和对比性。我们评估了来自五个不同XAI类别的六种可解释性技术在五个基于Encoder的语言模型(TinyBERT、BERTbase、BERTlarge、XLM-R large和DeBERTa-xlarge)上的有效性,使用IMDB电影评论和Tweet情感提取(TSE)数据集。我们的研究结果表明,基于模型简化的XAI方法(LIME)在多个指标和模型中始终表现优异,在HA方面表现出色,在DeBERTa-xlarge上得分为0.9685,并且随着大型语言模型复杂性的增加,鲁棒性和一致性也表现良好。AMV展示了最佳的鲁棒性,得分低至0.0020。它还在一致性方面表现出色,在所有模型中都获得了接近完美的0.9999分。在对比性方面,LRP表现最佳,尤其是在更复杂的模型上,得分高达0.9371。
🔬 方法详解
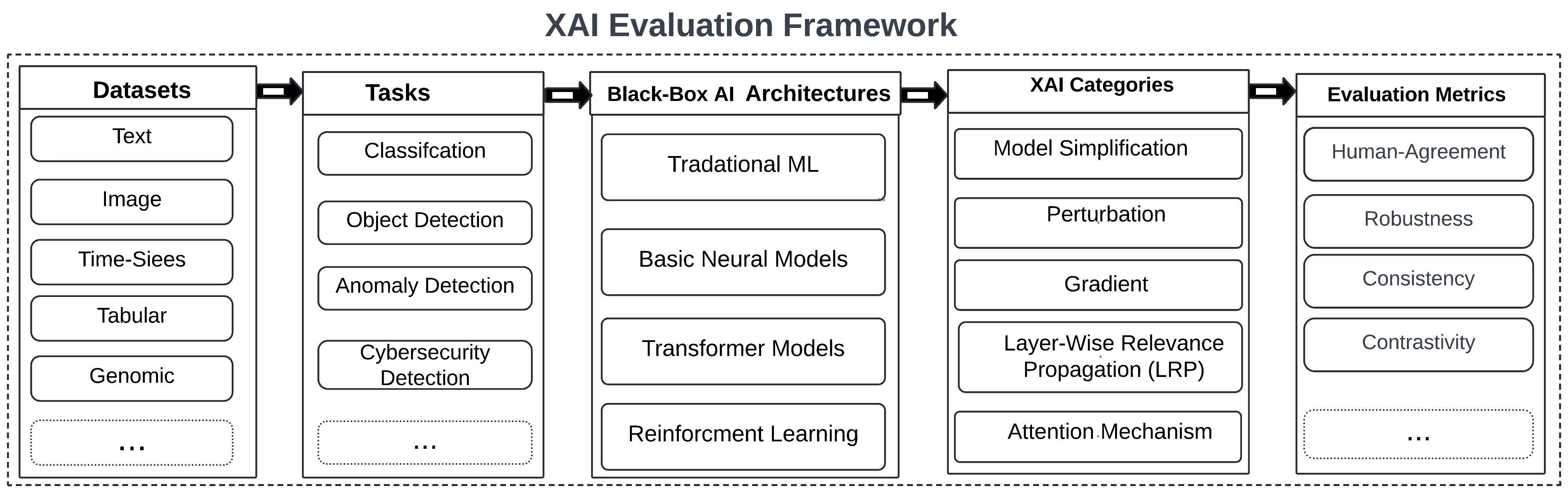
问题定义:论文旨在解决大型语言模型(LLM)的可解释性问题。现有的LLM通常被视为黑盒,难以理解其决策过程,这限制了它们在需要高透明度和可信度的应用中的使用。现有方法在评估XAI技术的有效性方面缺乏统一的标准和全面的评估指标。
核心思路:论文的核心思路是构建一个通用的评估框架,通过多个关键指标(人类推理一致性、鲁棒性、一致性和对比性)来全面评估不同的XAI技术在Encoder-based语言模型中的表现。通过比较不同XAI技术在这些指标上的得分,可以确定哪些技术更适合解释特定类型的模型和任务。
技术框架:该研究的整体框架包括以下几个主要阶段: 1. 选择Encoder-based语言模型:选择了TinyBERT、BERTbase、BERTlarge、XLM-R large和DeBERTa-xlarge。 2. 选择XAI技术:选择了LIME、SHAP、InputXGradient、Grad-CAM、LRP和AMV。 3. 选择数据集:使用了IMDB电影评论和Tweet情感提取(TSE)数据集。 4. 定义评估指标:定义了人类推理一致性(HA)、鲁棒性、一致性和对比性四个指标。 5. 评估XAI技术:使用定义的指标评估不同XAI技术在不同模型和数据集上的表现。 6. 分析结果:分析评估结果,确定哪些XAI技术在哪些方面表现更优。
关键创新:该研究的关键创新在于提出了一个通用的、多维度的XAI技术评估框架。该框架不仅考虑了XAI技术与人类直觉的一致性,还考虑了其鲁棒性、一致性和对比性。这使得可以更全面地了解不同XAI技术的优缺点,并为选择合适的XAI技术提供指导。与现有方法相比,该框架更加系统和全面。
关键设计: * 人类推理一致性(HA):通过人工标注来评估XAI解释与人类推理的一致性。 * 鲁棒性:通过对输入进行微小扰动来评估XAI解释的稳定性。 * 一致性:通过对同一输入的多次解释来评估XAI解释的一致性。 * 对比性:通过比较不同类别输入的解释来评估XAI解释的区分能力。 * 选择了常用的XAI技术,例如LIME,SHAP,Attention Mechanism Visualization等,保证了实验的代表性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LIME在多个指标和模型中表现优异,尤其是在DeBERTa-xlarge模型上的人类推理一致性(HA)得分高达0.9685。AMV在鲁棒性和一致性方面表现出色,鲁棒性得分低至0.0020,一致性得分接近完美,为0.9999。LRP在对比性方面表现最佳,尤其是在更复杂的模型上,得分高达0.9371。这些结果为选择合适的XAI技术提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种需要理解和信任AI决策的场景,例如金融风险评估、医疗诊断、舆情分析等。通过选择合适的XAI技术,可以提高AI系统的透明度,增强用户对AI决策的信任,并促进AI技术在更广泛领域的应用。未来的研究可以探索更有效的XAI技术和评估方法,以进一步提高AI系统的可解释性。
📄 摘要(原文)
The black-box nature of large language models (LLMs) necessitates the development of eXplainable AI (XAI) techniques for transparency and trustworthiness. However, evaluating these techniques remains a challenge. This study presents a general evaluation framework using four key metrics: Human-reasoning Agreement (HA), Robustness, Consistency, and Contrastivity. We assess the effectiveness of six explainability techniques from five different XAI categories model simplification (LIME), perturbation-based methods (SHAP), gradient-based approaches (InputXGradient, Grad-CAM), Layer-wise Relevance Propagation (LRP), and attention mechanisms-based explainability methods (Attention Mechanism Visualization, AMV) across five encoder-based language models: TinyBERT, BERTbase, BERTlarge, XLM-R large, and DeBERTa-xlarge, using the IMDB Movie Reviews and Tweet Sentiment Extraction (TSE) datasets. Our findings show that the model simplification-based XAI method (LIME) consistently outperforms across multiple metrics and models, significantly excelling in HA with a score of 0.9685 on DeBERTa-xlarge, robustness, and consistency as the complexity of large language models increases. AMV demonstrates the best Robustness, with scores as low as 0.0020. It also excels in Consistency, achieving near-perfect scores of 0.9999 across all models. Regarding Contrastivity, LRP performs the best, particularly on more complex models, with scores up to 0.9371.