New Evaluation Paradigm for Lexical Simplification
作者: Jipeng Qiang, Minjiang Huang, Yi Zhu, Yunhao Yuan, Chaowei Zhang, Xiaoye Ouyang
分类: cs.CL
发布日期: 2025-01-25
💡 一句话要点
提出一种新的词汇简化评估范式,解决现有数据集无法评估LLM简化句子的难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 词汇简化 大型语言模型 数据集构建 人机协作 多LLM协作
📋 核心要点
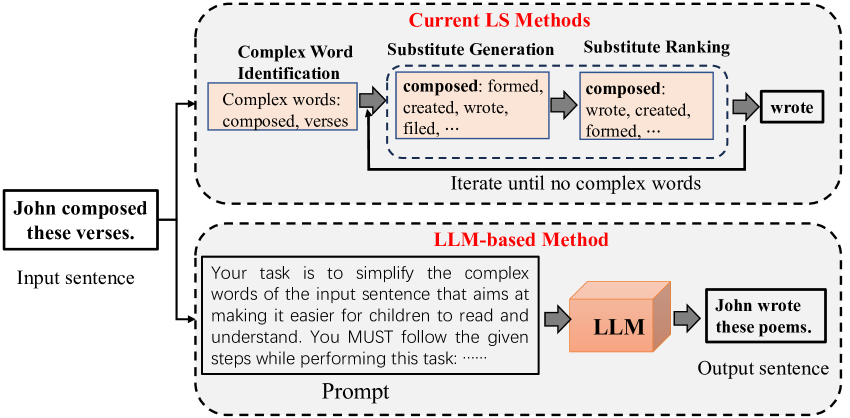
- 现有词汇简化数据集主要针对传统pipeline,无法有效评估大型语言模型直接生成简化句子的能力。
- 提出一种新颖的人工-机器协作标注方法,构建包含句子中所有复杂词及其替代词的综合数据集。
- 探索了基于多LLM协作的词汇简化方法,并在实验中显著超越了现有基线方法。
📝 摘要(中文)
词汇简化(LS)方法通常采用三步流程:复杂词识别、替代词生成和替代词排序,每个步骤都有独立的评估数据集。我们发现,大型语言模型(LLM)可以通过单个提示直接简化句子,绕过传统流程。然而,现有的LS数据集不适合评估这些LLM生成的简化句子,因为它们侧重于为单个复杂词提供替代词,而没有识别句子中的所有复杂词。为了解决这个问题,我们提出了一种新的人工-机器协作标注方法,用于构建一个一体化的LS数据集。自动化方法生成潜在替代词池,然后由人工标注者评估,并根据需要建议额外的替代方案。此外,我们探索了基于LLM的方法,包括单提示、上下文学习和思维链技术。我们引入了一种多LLM协作方法来模拟LS任务的每个步骤。实验结果表明,基于多LLM方法的LS显著优于现有基线。
🔬 方法详解
问题定义:论文旨在解决现有词汇简化(LS)评估数据集的不足。传统LS数据集主要关注为单个复杂词提供替代词,而忽略了句子中可能存在的其他复杂词,并且无法有效评估直接生成简化句子的大型语言模型(LLM)。现有方法的痛点在于缺乏一个能够全面评估LLM简化句子质量的综合性数据集。
核心思路:论文的核心思路是构建一个包含句子中所有复杂词及其替代词的“一体化”LS数据集,并利用人工-机器协作的方式提高标注效率和质量。同时,探索利用多LLM协作模拟传统LS流程,并将其作为一种新的简化方法。
技术框架:该研究的技术框架主要包含两个部分:一是数据集构建,采用人工-机器协作的方式,首先由自动化方法生成潜在替代词池,然后由人工标注者进行评估和补充;二是基于LLM的简化方法,包括单提示、上下文学习和思维链等技术,并引入多LLM协作策略,模拟复杂词识别、替代词生成和替代词排序等步骤。
关键创新:该论文的关键创新在于:1) 提出了一个新颖的词汇简化评估范式,通过构建包含句子中所有复杂词及其替代词的综合数据集,解决了现有数据集无法有效评估LLM简化句子的难题;2) 探索了多LLM协作在词汇简化任务中的应用,并证明了其优越性。
关键设计:在数据集构建方面,采用了自动化方法生成替代词池,并由人工标注者进行评估和补充,以提高标注效率和质量。在LLM应用方面,探索了单提示、上下文学习和思维链等技术,并设计了多LLM协作策略,模拟传统LS流程的各个步骤。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于多LLM协作的词汇简化方法显著优于现有基线方法。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。但结论表明,该方法在词汇简化任务中具有显著优势。
🎯 应用场景
该研究成果可应用于机器翻译、文本摘要、教育辅助等领域。构建的综合性词汇简化数据集能够促进LLM在文本简化方面的研究和应用,提高文本的可读性和易理解性,帮助不同语言水平或认知能力的人群更好地理解文本内容。未来,该方法有望应用于更广泛的自然语言处理任务中。
📄 摘要(原文)
Lexical Simplification (LS) methods use a three-step pipeline: complex word identification, substitute generation, and substitute ranking, each with separate evaluation datasets. We found large language models (LLMs) can simplify sentences directly with a single prompt, bypassing the traditional pipeline. However, existing LS datasets are not suitable for evaluating these LLM-generated simplified sentences, as they focus on providing substitutes for single complex words without identifying all complex words in a sentence. To address this gap, we propose a new annotation method for constructing an all-in-one LS dataset through human-machine collaboration. Automated methods generate a pool of potential substitutes, which human annotators then assess, suggesting additional alternatives as needed. Additionally, we explore LLM-based methods with single prompts, in-context learning, and chain-of-thought techniques. We introduce a multi-LLMs collaboration approach to simulate each step of the LS task. Experimental results demonstrate that LS based on multi-LLMs approaches significantly outperforms existing baselines.