Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning
作者: Yiqun Chen, Lingyong Yan, Weiwei Sun, Xinyu Ma, Yi Zhang, Shuaiqiang Wang, Dawei Yin, Yiming Yang, Jiaxin Mao
分类: cs.CL, cs.IR
发布日期: 2025-01-25 (更新: 2025-10-07)
备注: NeurIPS 2025
💡 一句话要点
提出MMOA-RAG,通过多智能体强化学习优化检索增强生成,提升问答准确性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多智能体强化学习 问答系统 知识库 联合优化
📋 核心要点
- 现有RAG方法通常独立优化各个组件,忽略了组件间的依赖关系,导致整体性能受限。
- MMOA-RAG将RAG流程视为多智能体合作任务,通过强化学习协调各组件目标,实现联合优化。
- 实验表明,MMOA-RAG在多个QA基准上显著提升了RAG流程的性能,优于现有基线方法。
📝 摘要(中文)
检索增强生成(RAG)被广泛用于将外部知识融入大型语言模型,从而提高问答(QA)任务的事实性和减少幻觉。标准的RAG流程包括查询重写、文档检索、文档过滤和答案生成等组件。然而,这些组件通常通过监督微调单独优化,这可能导致各个组件的目标与生成准确答案的总体目标不一致。尽管最近的研究探索了使用强化学习(RL)来优化特定的RAG组件,但这些方法通常侧重于只有两个组件的简单流程,或者没有充分解决模块之间复杂的相互依赖和协作交互。为了克服这些限制,我们提出将具有多个组件的复杂RAG流程视为多智能体合作任务,其中每个组件都可以被视为一个RL智能体。具体来说,我们提出了MMOA-RAG,即用于RAG的多模块联合优化算法,该算法采用多智能体强化学习来协调所有智能体的目标,以实现统一的奖励,例如最终答案的F1分数。在各种QA基准上进行的实验表明,MMOA-RAG有效地提高了流程的整体性能,并且优于现有的基线。此外,全面的消融研究验证了各个组件的贡献,并表明MMOA-RAG可以适应不同的RAG流程和基准。
🔬 方法详解
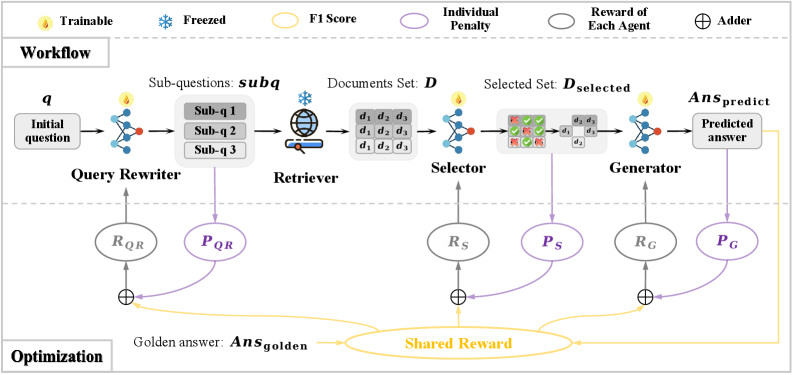
问题定义:现有RAG流程的各个组件(如查询重写、文档检索、文档过滤、答案生成)通常是独立优化的,这意味着每个组件的目标可能与最终生成准确答案的总体目标不一致。这种独立优化忽略了组件之间的复杂依赖关系和协作交互,导致整个RAG流程的性能瓶颈。现有方法要么只关注简单流程,要么无法充分解决组件间的协同问题。
核心思路:MMOA-RAG的核心思路是将整个RAG流程视为一个多智能体合作任务。每个RAG组件被视为一个独立的智能体,通过多智能体强化学习(MARL)来协调这些智能体的行为,使它们共同朝着生成准确答案的统一目标努力。这种方法能够更好地捕捉组件之间的相互依赖关系,并优化整个流程的性能。
技术框架:MMOA-RAG的技术框架主要包含以下几个模块:1) RAG流程建模:将RAG流程中的每个组件建模为一个智能体。2) 状态空间设计:定义每个智能体的状态空间,包括输入查询、检索到的文档、中间结果等。3) 动作空间设计:定义每个智能体的动作空间,例如查询重写的方式、文档过滤的阈值等。4) 奖励函数设计:设计一个全局奖励函数,例如最终答案的F1分数,用于指导所有智能体的学习。5) 多智能体强化学习算法:使用MARL算法(具体算法未知)来训练所有智能体,使它们能够协同工作,最大化全局奖励。
关键创新:MMOA-RAG的关键创新在于将多智能体强化学习应用于RAG流程的整体优化。与以往独立优化组件或仅优化简单流程的方法不同,MMOA-RAG能够同时优化多个组件,并考虑到它们之间的相互依赖关系。这种方法能够更有效地利用外部知识,提高问答系统的准确性和鲁棒性。
关键设计:具体的技术细节未知,但可以推测可能包括:1) 奖励函数的具体形式,如何平衡准确性和效率。2) MARL算法的选择,例如是否使用集中式训练、分布式执行的框架。3) 状态空间和动作空间的具体设计,如何有效地表示RAG流程中的信息和操作。4) 探索-利用策略的设计,如何在探索新的策略和利用已知的有效策略之间进行平衡。
🖼️ 关键图片
📊 实验亮点
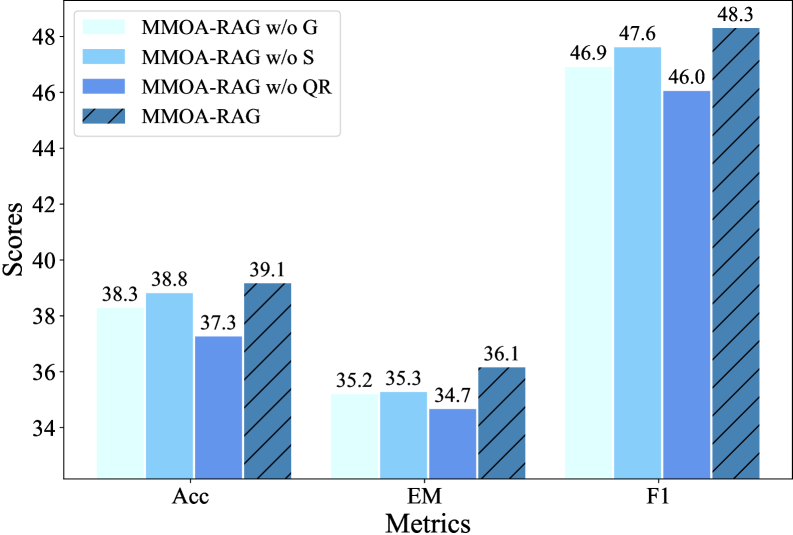
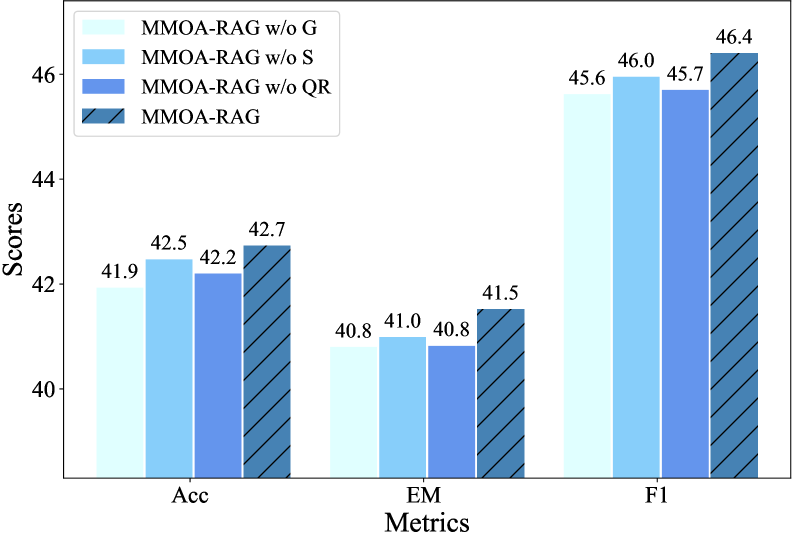
实验结果表明,MMOA-RAG在多个QA基准上显著优于现有基线方法。具体性能数据未知,但摘要中提到MMOA-RAG有效地提高了流程的整体性能,并且优于现有的基线。消融研究验证了各个组件的贡献,并表明MMOA-RAG可以适应不同的RAG流程和基准。
🎯 应用场景
MMOA-RAG可应用于各种需要检索外部知识的问答系统,例如智能客服、知识库问答、医疗诊断辅助等。通过提升问答的准确性和可靠性,可以提高用户满意度,降低运营成本,并为决策提供更可靠的依据。未来,该方法还可扩展到其他需要多模块协同的自然语言处理任务,例如文本摘要、机器翻译等。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is widely utilized to incorporate external knowledge into large language models, thereby enhancing factuality and reducing hallucinations in question-answering (QA) tasks. A standard RAG pipeline consists of several components, such as query rewriting, document retrieval, document filtering, and answer generation. However, these components are typically optimized separately through supervised fine-tuning, which can lead to misalignments between the objectives of individual components and the overarching aim of generating accurate answers. Although recent efforts have explored using reinforcement learning (RL) to optimize specific RAG components, these approaches often focus on simple pipelines with only two components or do not adequately address the complex interdependencies and collaborative interactions among the modules. To overcome these limitations, we propose treating the complex RAG pipeline with multiple components as a multi-agent cooperative task, in which each component can be regarded as an RL agent. Specifically, we present MMOA-RAG, Multi-Module joint Optimization Algorithm for RAG, which employs multi-agent reinforcement learning to harmonize all agents' goals toward a unified reward, such as the F1 score of the final answer. Experiments conducted on various QA benchmarks demonstrate that MMOA-RAG effectively boost the overall performance of the pipeline and outperforms existing baselines. Furthermore, comprehensive ablation studies validate the contributions of individual components and demonstrate MMOA-RAG can be adapted to different RAG pipelines and benchmarks.