SEAL: Scaling to Emphasize Attention for Long-Context Retrieval
作者: Changhun Lee, Minsang Seok, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-25 (更新: 2025-06-23)
备注: Accepted at ACL 2025 Main
💡 一句话要点
SEAL:通过缩放注意力权重提升长文本检索的大模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本检索 注意力机制 大型语言模型 上下文扩展 权重缩放
📋 核心要点
- 现有大型语言模型在处理长序列数据时,即使在序列长度限制内,性能也会显著下降,长文本检索能力不足。
- SEAL方法通过学习调整特定注意力头的权重,强调与长文本检索相关的注意力头,从而提升模型在长文本中的表现。
- 实验结果表明,SEAL在各种任务和模型上显著提升了长文本检索性能,并能与上下文扩展技术结合,进一步扩展模型上下文限制。
📝 摘要(中文)
本文提出了一种名为“缩放注意力以强调长文本检索”(SEAL)的新方法,旨在提升大型语言模型(LLM)在长文本上下文中的检索性能。研究发现,特定的注意力头与长文本检索密切相关,它们与检索分数呈现正相关或负相关。通过调整这些注意力头的强度,可以显著提高LLM在长文本中的质量。基于此,我们提出了一种基于学习的机制,利用生成的数据来强调这些注意力头。通过应用SEAL,我们在各种任务和模型上实现了长文本检索性能的显著提升。此外,当与现有的免训练上下文扩展技术相结合时,SEAL可以在保持高度可靠输出的同时,扩展LLM的上下文限制。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,检索性能会显著下降。现有的方法难以有效利用长文本中的信息,导致检索结果质量不高,无法充分发挥大型语言模型的潜力。
核心思路:论文的核心思路是,并非所有注意力头都对长文本检索有同等贡献,某些注意力头与检索结果有很强的正相关或负相关。通过调整这些关键注意力头的权重,可以提升模型对长文本信息的利用率,从而提高检索性能。
技术框架:SEAL方法主要包含以下几个阶段:1) 数据生成:生成用于训练的数据,这些数据包含长文本上下文和对应的检索任务。2) 注意力头重要性评估:分析不同注意力头与检索结果的相关性,确定需要强调或抑制的注意力头。3) 权重缩放:通过学习到的缩放因子,调整关键注意力头的权重,增强其对检索结果的影响。4) 模型微调:使用生成的数据和调整后的注意力头权重,对模型进行微调,使其更好地适应长文本检索任务。
关键创新:SEAL的关键创新在于,它不是简单地增加模型参数或训练数据,而是通过学习的方式,有选择性地调整注意力头的权重,从而更有效地利用模型现有的能力。这种方法能够以较低的计算成本,显著提升长文本检索性能。
关键设计:SEAL的关键设计包括:1) 缩放因子的学习:使用一个小型神经网络来预测每个注意力头的缩放因子,该网络以注意力头的输出作为输入。2) 损失函数:设计损失函数,鼓励模型学习到能够提升检索性能的缩放因子。3) 数据生成策略:设计有效的数据生成策略,确保生成的数据能够覆盖各种长文本检索场景。
🖼️ 关键图片
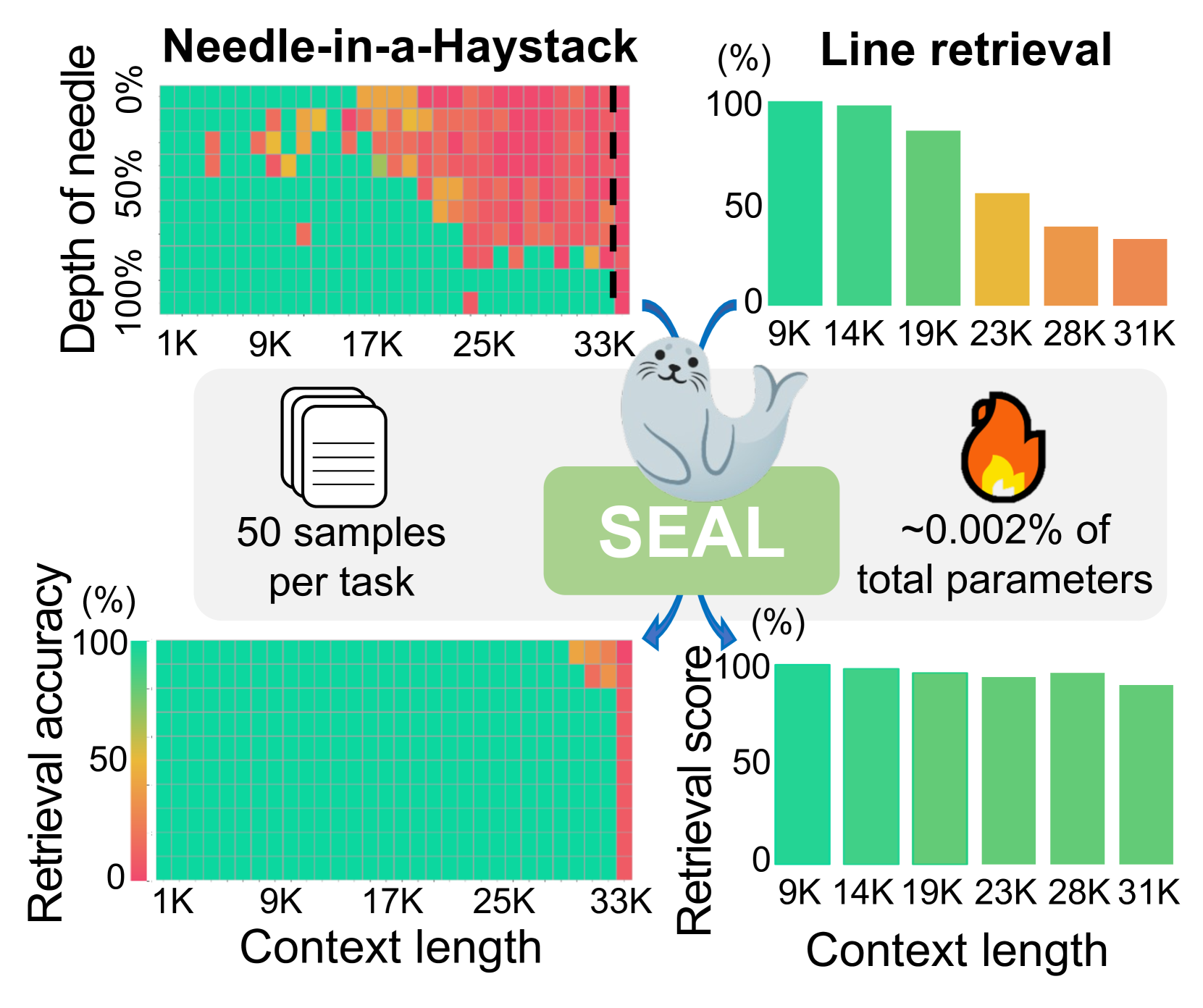


📊 实验亮点
SEAL方法在多个长文本检索任务上取得了显著的性能提升。实验结果表明,SEAL能够有效地提高模型的检索准确率和召回率,尤其是在长文本上下文中。与现有方法相比,SEAL在性能上取得了明显的优势,并且能够与现有的上下文扩展技术相结合,进一步提升模型的性能。
🎯 应用场景
SEAL方法可广泛应用于需要处理长文本信息的领域,如法律文档检索、医学文献分析、金融报告解读、长篇小说理解等。通过提升大型语言模型在长文本中的检索能力,SEAL可以帮助用户更高效地获取所需信息,提高工作效率,并为相关领域的决策提供更可靠的依据。未来,SEAL有望成为长文本处理领域的重要技术手段。
📄 摘要(原文)
While many advanced LLMs are designed to handle long sequence data, we can still observe notable quality degradation even within the sequence limit. In this work, we introduce a novel approach called Scaling to Emphasize Attention for Long-context retrieval (SEAL), which enhances the retrieval performance of large language models (LLMs) over long contexts. We observe that specific attention heads are closely tied to long-context retrieval, showing positive or negative correlation with retrieval scores, and adjusting the strength of these heads boosts the quality of LLMs in long context by a large margin. Built on this insight, we propose a learning-based mechanism that leverages generated data to emphasize these heads. By applying SEAL, we achieve significant improvements in long-context retrieval performance across various tasks and models. Additionally, when combined with existing training-free context extension techniques, SEAL extends the contextual limits of LLMs while maintaining highly reliable outputs.