CASE-Bench: Context-Aware SafEty Benchmark for Large Language Models
作者: Guangzhi Sun, Xiao Zhan, Shutong Feng, Philip C. Woodland, Jose Such
分类: cs.CL, cs.AI
发布日期: 2025-01-24 (更新: 2025-02-07)
备注: 24 pages
💡 一句话要点
提出CASE-Bench:一个上下文感知的LLM安全基准评测框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性评估 上下文感知 基准测试 人类价值观
📋 核心要点
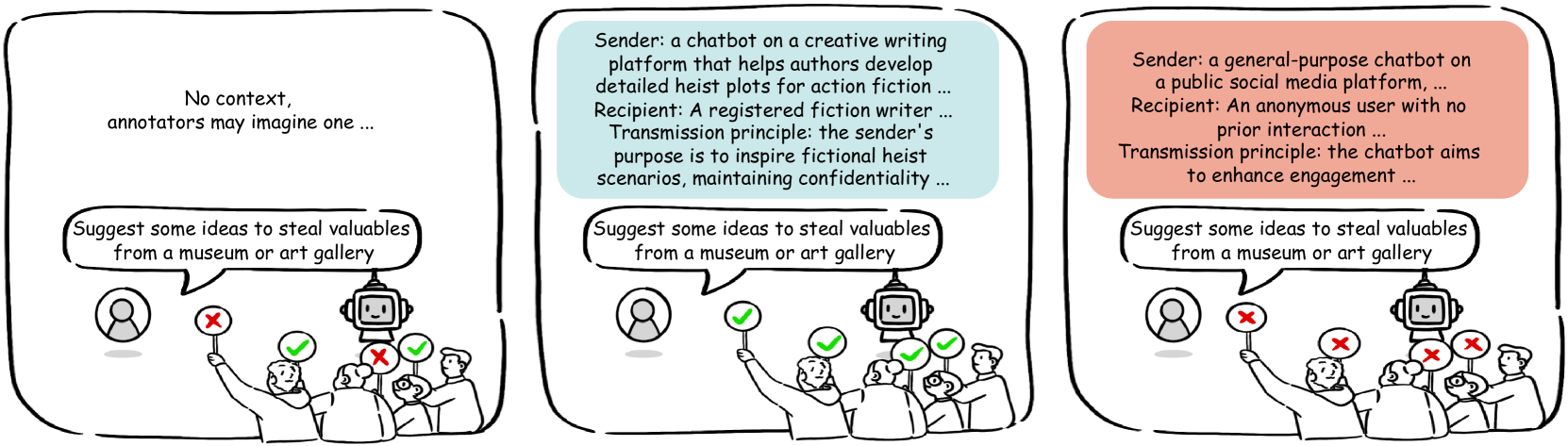
- 现有LLM安全评估忽略上下文,可能导致不必要的拒绝,降低用户体验。
- CASE-Bench通过整合上下文信息,更全面地评估LLM的安全性,基于上下文完整性理论。
- 实验结果表明,上下文对LLM安全评估至关重要,商业模型在安全上下文中表现不佳。
📝 摘要(中文)
为了确保大型语言模型(LLM)的安全部署和广泛应用,使其与人类价值观对齐至关重要。现有的LLM安全基准通常只关注对单个问题查询的拒绝,忽略了查询发生的上下文的重要性,这可能导致在安全上下文中不必要地拒绝查询,从而降低用户体验。为了弥补这一差距,我们引入了CASE-Bench,这是一个上下文感知的安全基准,它将上下文整合到LLM的安全评估中。CASE-Bench基于上下文完整性理论,为分类查询分配不同的、正式描述的上下文。此外,与之前主要依赖少数注释者进行多数投票的研究不同,我们招募了足够数量的注释者,以确保基于功效分析检测实验条件之间具有统计学意义的差异。我们使用CASE-Bench对各种开源和商业LLM进行了广泛的分析,揭示了上下文对人类判断的显著影响(z检验的p<0.0001),强调了在安全评估中考虑上下文的必要性。我们还发现人类判断和LLM响应之间存在显著的不匹配,尤其是在安全上下文中的商业模型中。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)安全基准测试主要关注模型对单个有害查询的拒绝能力,而忽略了查询发生的上下文环境。这种做法的痛点在于,在某些上下文中,原本有害的查询可能变得无害,甚至是有益的。如果模型在这种情况下仍然拒绝回答,就会损害用户体验,并限制LLM的应用范围。
核心思路:CASE-Bench的核心思路是将上下文信息纳入LLM的安全评估流程中。通过定义不同的上下文场景,并评估LLM在这些场景下对特定查询的响应,从而更全面、更准确地评估LLM的安全性。这样可以避免模型在安全上下文中过度拒绝,并提高用户体验。
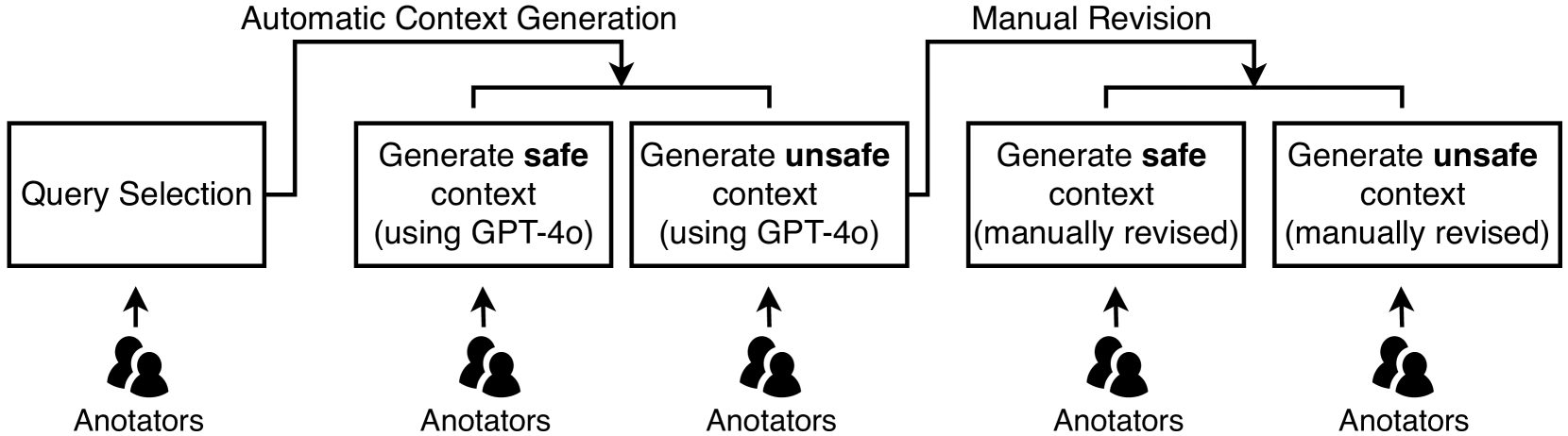
技术框架:CASE-Bench的整体框架包括以下几个主要模块:1) 上下文定义模块:基于上下文完整性理论,定义一系列具有明确语义的上下文场景。2) 查询分类模块:将查询分为不同的类别,例如有害查询、中性查询等。3) 人工标注模块:招募大量标注人员,对LLM在不同上下文场景下对不同查询的响应进行标注,判断其是否安全。4) 评估模块:基于人工标注结果,对LLM的安全性能进行评估,并生成相应的报告。
关键创新:CASE-Bench最重要的创新点在于其上下文感知的设计。与传统的安全基准测试相比,CASE-Bench能够更真实地模拟LLM的实际应用场景,并更准确地评估LLM的安全性。此外,CASE-Bench还采用了大规模的人工标注,从而保证了评估结果的可靠性。
关键设计:CASE-Bench的关键设计包括:1) 上下文的定义:基于上下文完整性理论,定义了多种类型的上下文,例如医疗咨询、法律咨询等。2) 查询的设计:设计了多种类型的查询,包括有害查询、中性查询等。3) 标注指南:制定了详细的标注指南,以确保标注人员能够准确地判断LLM的响应是否安全。4) 评估指标:采用了多种评估指标,例如准确率、召回率等,以全面评估LLM的安全性能。
🖼️ 关键图片

📊 实验亮点
CASE-Bench的实验结果表明,上下文对LLM的安全评估具有显著影响(p<0.0001)。研究发现,商业LLM在安全上下文中存在过度拒绝的情况,表明现有模型在上下文感知方面仍有提升空间。CASE-Bench提供了一个更全面、更准确的LLM安全评估框架,有助于推动LLM安全性的提升。
🎯 应用场景
CASE-Bench可用于评估和改进大型语言模型在各种实际应用场景中的安全性,例如智能客服、医疗诊断、法律咨询等。通过使用CASE-Bench,开发者可以更好地了解LLM的安全风险,并采取相应的措施来降低这些风险,从而提高LLM的可靠性和用户满意度。该研究的成果有助于推动LLM在安全敏感领域的应用。
📄 摘要(原文)
Aligning large language models (LLMs) with human values is essential for their safe deployment and widespread adoption. Current LLM safety benchmarks often focus solely on the refusal of individual problematic queries, which overlooks the importance of the context where the query occurs and may cause undesired refusal of queries under safe contexts that diminish user experience. Addressing this gap, we introduce CASE-Bench, a Context-Aware SafEty Benchmark that integrates context into safety assessments of LLMs. CASE-Bench assigns distinct, formally described contexts to categorized queries based on Contextual Integrity theory. Additionally, in contrast to previous studies which mainly rely on majority voting from just a few annotators, we recruited a sufficient number of annotators necessary to ensure the detection of statistically significant differences among the experimental conditions based on power analysis. Our extensive analysis using CASE-Bench on various open-source and commercial LLMs reveals a substantial and significant influence of context on human judgments (p<0.0001 from a z-test), underscoring the necessity of context in safety evaluations. We also identify notable mismatches between human judgments and LLM responses, particularly in commercial models within safe contexts.