On the locality bias and results in the Long Range Arena
作者: Pablo Miralles-González, Javier Huertas-Tato, Alejandro Martín, David Camacho
分类: cs.CL, cs.AI
发布日期: 2025-01-24
💡 一句话要点
揭示LRA基准测试的局部性偏差,Transformer通过优化训练可达SOTA
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长程依赖建模 Transformer 局部性偏差 LRA基准测试 位置编码
📋 核心要点
- LRA基准测试旨在评估模型在长程依赖建模中的能力,但现有Transformer变体表现不佳,面临挑战。
- 论文核心思想是揭示LRA测试的局部性偏差,并利用优化训练后的Transformer达到SOTA性能。
- 实验表明,通过缓解数据效率低下问题和适当的位置编码,Transformer在LRA上可达到SOTA性能。
📝 摘要(中文)
长程竞技场(LRA)基准旨在评估Transformer改进方案和替代方案在长程依赖建模任务中的性能。Transformer及其主要变体在该基准上的表现不佳,而诸如状态空间模型(SSM)之类的新架构获得了一些关注,在LRA中大大优于Transformer。最近的研究表明,通过去噪预训练阶段,Transformer可以在LRA中获得与这些新架构相媲美的结果。本文讨论并解释了MEGA和SSM等架构在长程竞技场中的优越性,以及Transformer结果的最新改进,指出了任务的位置和局部性质。我们表明,虽然LRA是长程依赖建模的基准,但实际上大部分性能来自短程依赖。通过使用训练技术来缓解数据效率低下问题,Transformer可以通过适当的位置编码达到最先进的性能。此外,使用相同的技术,我们能够消除SSM卷积内核的所有限制,并学习完全参数化的卷积而不降低性能,这表明SSM背后的设计选择仅仅为这些特定任务增加了归纳偏置和学习效率。我们的见解表明,应谨慎解释LRA结果,并呼吁重新设计基准。
🔬 方法详解
问题定义:LRA基准测试旨在评估模型处理长程依赖关系的能力,但Transformer及其变体在该基准上表现不佳。现有方法的痛点在于无法有效捕捉长程依赖,导致性能瓶颈。
核心思路:论文的核心思路是指出LRA基准测试实际上对局部依赖关系更加敏感,而非真正的长程依赖。通过优化Transformer的训练方式,使其更好地利用局部信息和位置编码,可以显著提升其在LRA上的性能。
技术框架:论文没有提出新的模型架构,而是侧重于优化现有Transformer的训练流程。具体而言,采用了缓解数据效率低下的训练技术,并强调了位置编码的重要性。通过这些优化,Transformer能够更好地学习和利用LRA任务中的局部依赖关系。
关键创新:论文的关键创新在于揭示了LRA基准测试的局部性偏差。之前的研究主要集中于设计新的模型架构来处理长程依赖,而该论文则指出,LRA的性能瓶颈并非完全在于长程依赖建模能力,而更多地在于对局部信息的有效利用。
关键设计:论文的关键设计在于训练策略的优化,包括缓解数据效率低下的技术和位置编码的选择。此外,论文还通过实验证明,可以移除SSM卷积核的限制,并学习完全参数化的卷积而不降低性能,这表明SSM的优势在于其归纳偏置和学习效率,而非其处理长程依赖的能力。
🖼️ 关键图片
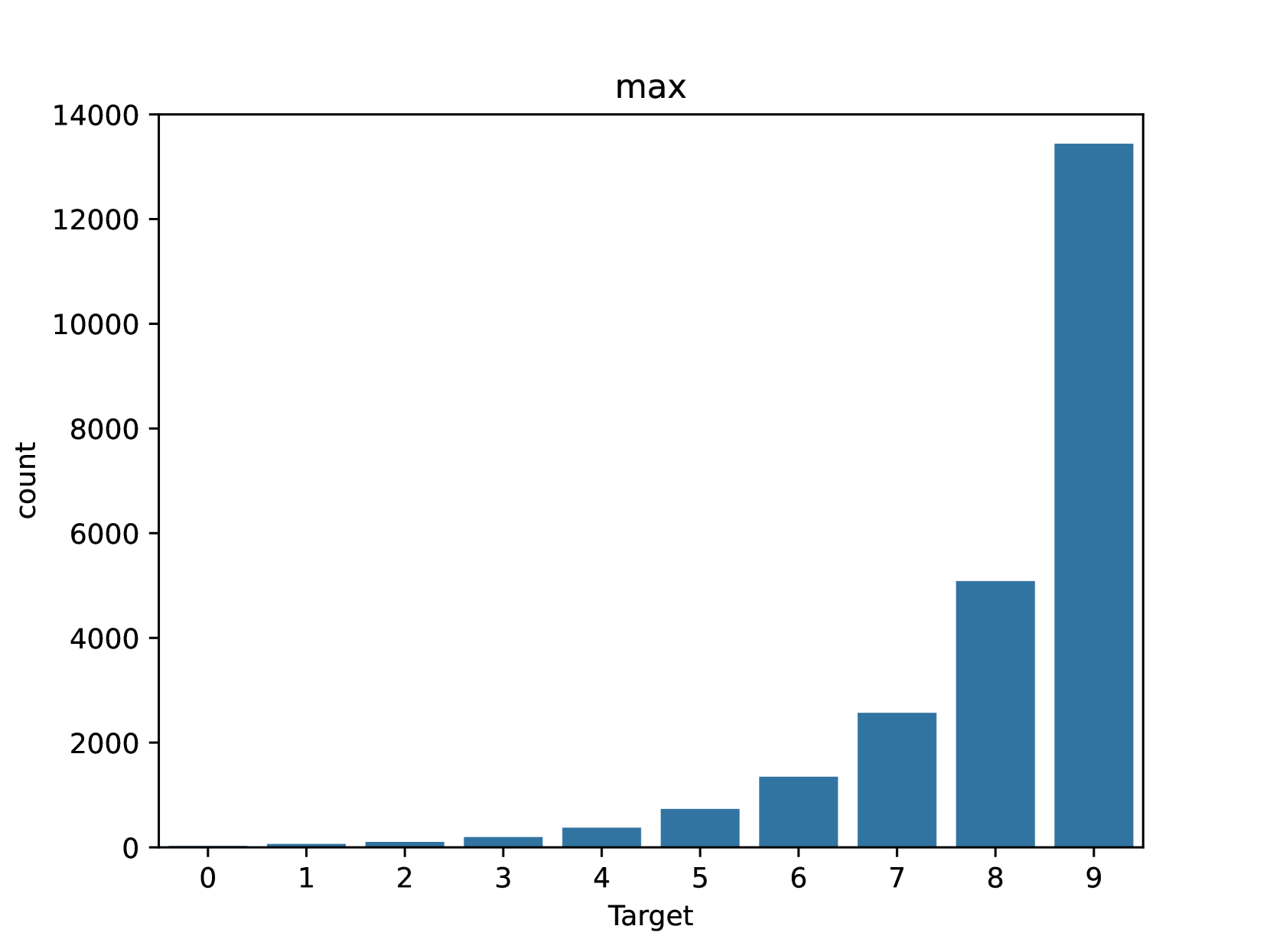
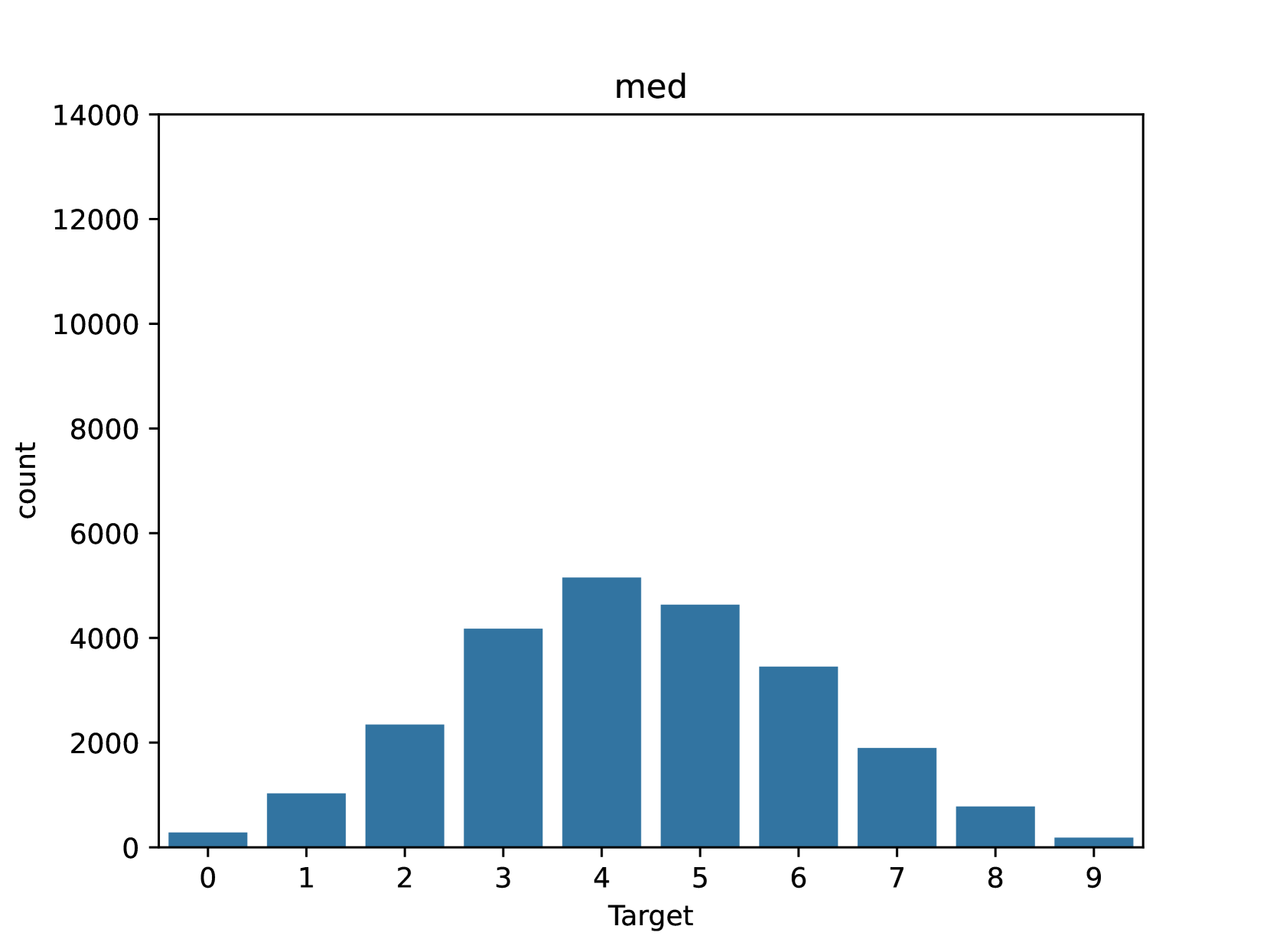
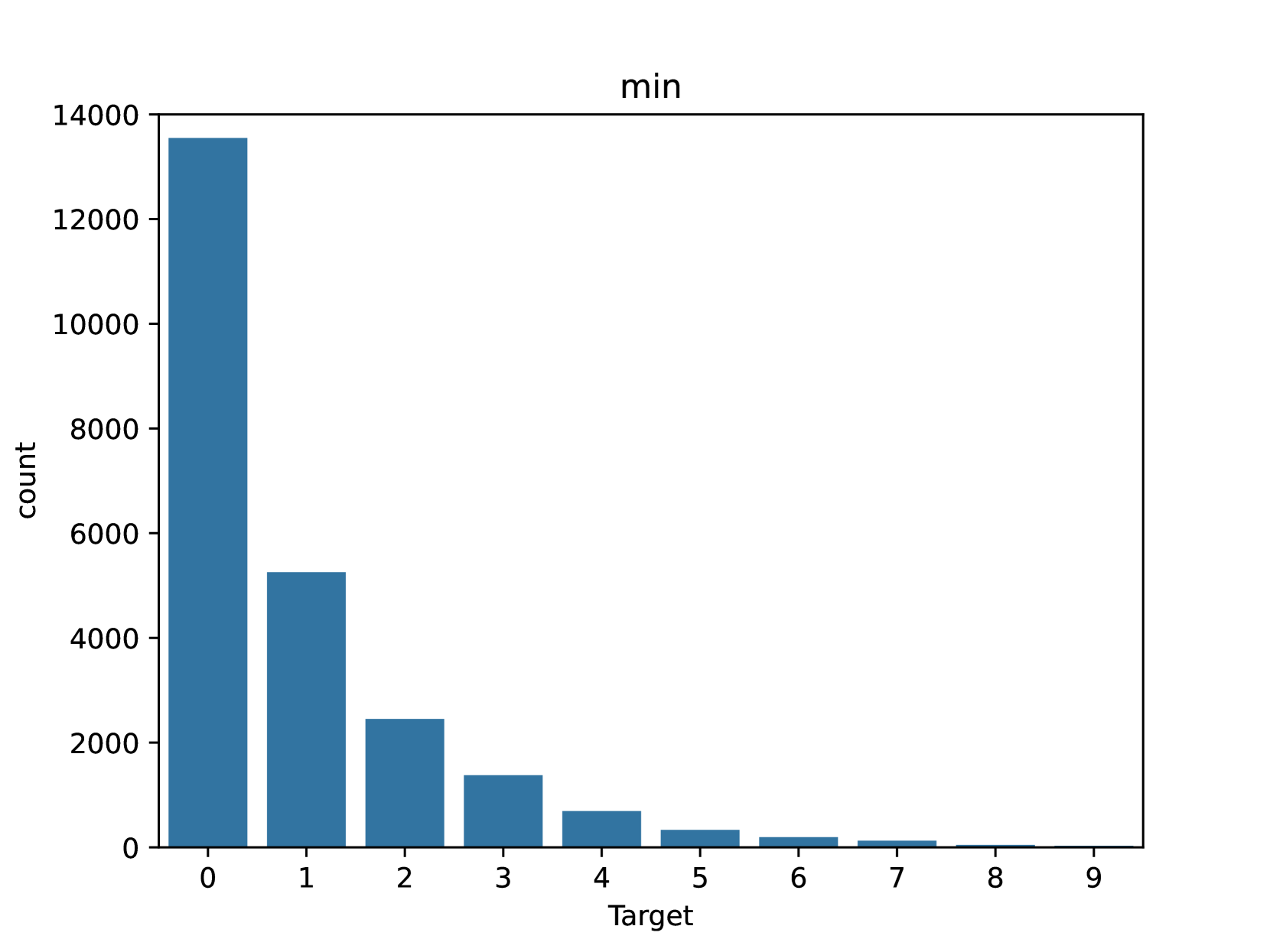
📊 实验亮点
论文通过优化Transformer的训练方式,使其在LRA基准测试上达到了SOTA性能。此外,论文还证明,可以移除SSM卷积核的限制,并学习完全参数化的卷积而不降低性能,这表明SSM的优势在于其归纳偏置和学习效率。
🎯 应用场景
该研究的潜在应用领域包括序列建模、自然语言处理和时间序列分析等。通过揭示LRA基准测试的局部性偏差,可以帮助研究人员更有效地评估和改进模型在这些任务中的性能。此外,该研究也为设计更合理的基准测试提供了启示。
📄 摘要(原文)
The Long Range Arena (LRA) benchmark was designed to evaluate the performance of Transformer improvements and alternatives in long-range dependency modeling tasks. The Transformer and its main variants performed poorly on this benchmark, and a new series of architectures such as State Space Models (SSMs) gained some traction, greatly outperforming Transformers in the LRA. Recent work has shown that with a denoising pre-training phase, Transformers can achieve competitive results in the LRA with these new architectures. In this work, we discuss and explain the superiority of architectures such as MEGA and SSMs in the Long Range Arena, as well as the recent improvement in the results of Transformers, pointing to the positional and local nature of the tasks. We show that while the LRA is a benchmark for long-range dependency modeling, in reality most of the performance comes from short-range dependencies. Using training techniques to mitigate data inefficiency, Transformers are able to reach state-of-the-art performance with proper positional encoding. In addition, with the same techniques, we were able to remove all restrictions from SSM convolutional kernels and learn fully parameterized convolutions without decreasing performance, suggesting that the design choices behind SSMs simply added inductive biases and learning efficiency for these particular tasks. Our insights indicate that LRA results should be interpreted with caution and call for a redesign of the benchmark.