Rethinking Table Instruction Tuning
作者: Naihao Deng, Rada Mihalcea
分类: cs.CL, cs.AI
发布日期: 2025-01-24 (更新: 2025-08-01)
备注: Accepted to ACL 2025 Findings. Updates: 07/2025: We release the TAMA-QWen2.5 and TAMA-QWen3 models. 06/2025: We release our project page: https://lit.eecs.umich.edu/TAMA/, code: https://github.com/MichiganNLP/TAMA, huggingface models: https://huggingface.co/collections/MichiganNLP/tama-684eeb3e7f262362856eccd1, and data: https://huggingface.co/datasets/MichiganNLP/TAMA_Instruct
💡 一句话要点
重新思考表格指令调优:更小的学习率和更少的数据即可提升表格理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格理解 指令调优 大型语言模型 超参数优化 领域泛化
📋 核心要点
- 现有表格指令调优研究忽略了超参数选择对模型性能的影响,且缺乏对模型领域外泛化能力和通用能力的全面评估。
- 论文通过系统分析发现,较小的学习率和较少的训练数据可以提升表格理解能力,同时保持模型的通用能力。
- 论文提出了TAMA模型,该模型在表格任务上表现优异,与GPT-3.5和GPT-4相当,并保持了良好的领域外泛化能力。
📝 摘要(中文)
近年来,表格理解领域的研究重点在于对大型语言模型(LLMs)进行指令调优,以适应表格相关任务。然而,现有的研究忽略了超参数选择的影响,并且缺乏对领域外表格理解能力和这些表格LLM通用能力的全面评估。本文评估了现有表格LLM的这些能力,发现与基础模型相比,领域外表格理解能力和通用能力均显著下降。通过系统分析,我们表明学习率等超参数可以显著影响表格特定能力和通用能力。与之前的表格指令调优工作相反,我们证明了较小的学习率和较少的训练实例可以增强表格理解能力,同时保持通用能力。基于我们的发现,我们推出了TAMA,这是一个基于LLaMA 3.1 8B Instruct进行指令调优的表格LLM,在表格任务上达到了与GPT-3.5和GPT-4相当甚至超越的性能,同时保持了强大的领域外泛化能力和通用能力。我们的发现强调了通过仔细选择超参数来降低数据标注成本和更高效地进行模型开发的潜力。我们开源了该项目和我们的模型。
🔬 方法详解
问题定义:现有表格指令调优方法在提升表格理解能力的同时,往往会损害模型的领域外泛化能力和通用能力。此外,超参数的选择对模型性能的影响被忽视,导致模型训练效率低下,数据标注成本高昂。
核心思路:论文的核心思路是通过系统分析超参数(如学习率)对表格LLM性能的影响,找到一个平衡点,使得模型在提升表格理解能力的同时,能够保持甚至提升其领域外泛化能力和通用能力。论文发现,较小的学习率和较少的训练数据可以达到这一目标。
技术框架:论文的技术框架主要包括以下几个步骤:1) 评估现有表格LLM的领域外泛化能力和通用能力;2) 系统分析超参数(如学习率)对模型性能的影响;3) 基于分析结果,提出TAMA模型,并使用较小的学习率和较少的训练数据进行指令调优;4) 在多个表格任务上评估TAMA模型的性能,并与现有模型进行比较。
关键创新:论文的关键创新在于发现了较小的学习率和较少的训练数据可以同时提升表格理解能力和保持模型的通用能力。这一发现颠覆了以往表格指令调优的认知,为更高效的模型开发和更低的数据标注成本提供了新的思路。
关键设计:TAMA模型基于LLaMA 3.1 8B Instruct,并使用较小的学习率进行指令调优。具体的学习率数值在论文中进行了详细的实验分析和选择。此外,论文还探索了不同数量的训练数据对模型性能的影响,并最终选择了合适的训练数据规模。
🖼️ 关键图片

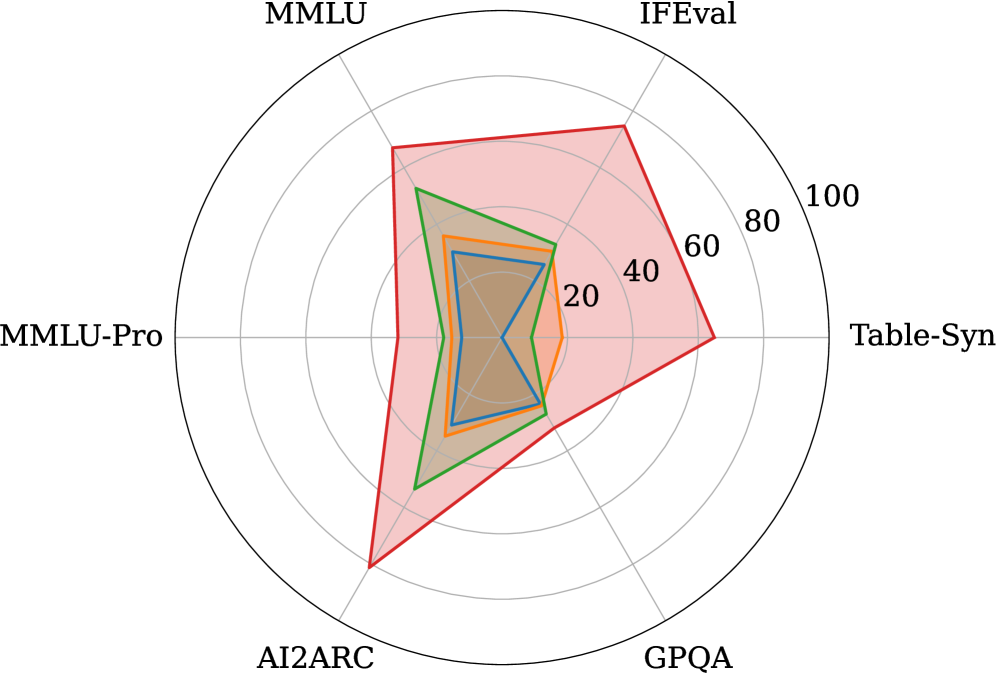
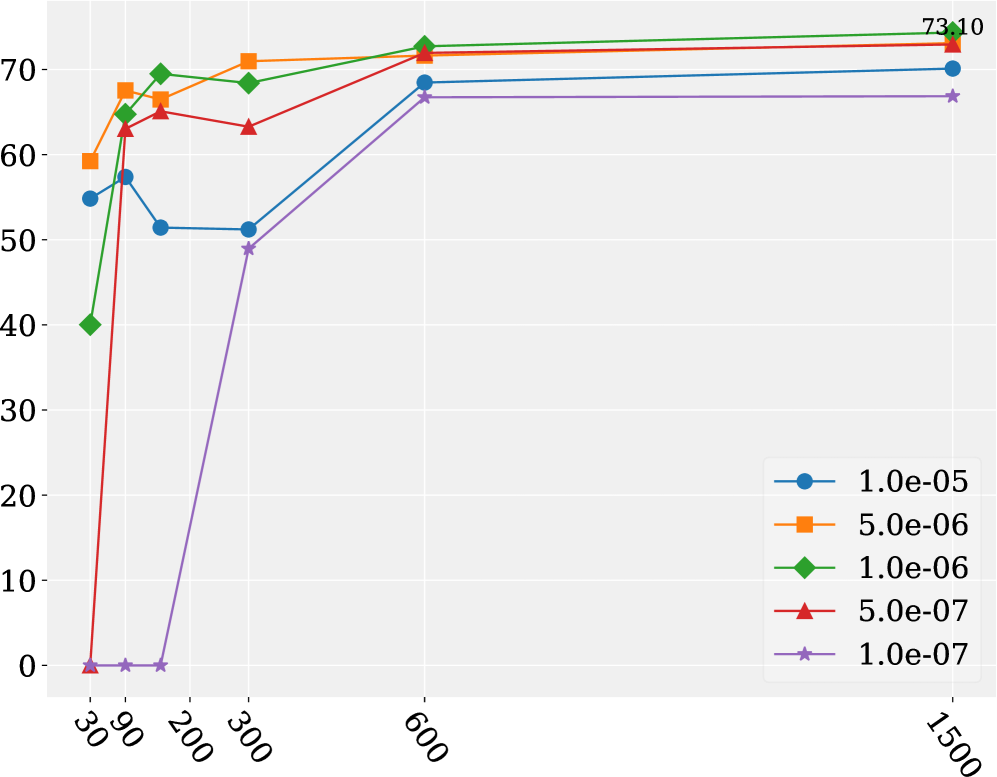
📊 实验亮点
TAMA模型在表格任务上达到了与GPT-3.5和GPT-4相当甚至超越的性能,同时保持了强大的领域外泛化能力和通用能力。实验结果表明,通过仔细选择超参数,可以在提升表格理解能力的同时,避免损害模型的通用能力,从而实现更高效的模型开发。
🎯 应用场景
该研究成果可应用于各种需要表格理解的场景,例如金融分析、数据挖掘、知识图谱构建等。通过降低数据标注成本和提高模型训练效率,可以加速表格理解技术的应用和普及,并为相关领域带来更大的价值。
📄 摘要(原文)
Recent advances in table understanding have focused on instruction-tuning large language models (LLMs) for table-related tasks. However, existing research has overlooked the impact of hyperparameter choices, and also lacks a comprehensive evaluation of the out-of-domain table understanding ability and the general capabilities of these table LLMs. In this paper, we evaluate these abilities in existing table LLMs, and find significant declines in both out-of-domain table understanding and general capabilities as compared to their base models. Through systematic analysis, we show that hyperparameters, such as learning rate, can significantly influence both table-specific and general capabilities. Contrary to the previous table instruction-tuning work, we demonstrate that smaller learning rates and fewer training instances can enhance table understanding while preserving general capabilities. Based on our findings, we introduce TAMA, a TAble LLM instruction-tuned from LLaMA 3.1 8B Instruct, which achieves performance on par with, or surpassing GPT-3.5 and GPT-4 on table tasks, while maintaining strong out-of-domain generalization and general capabilities. Our findings highlight the potential for reduced data annotation costs and more efficient model development through careful hyperparameter selection. We open-source the project and our models.