RealCritic: Towards Effectiveness-Driven Evaluation of Language Model Critiques
作者: Zhengyang Tang, Ziniu Li, Zhenyang Xiao, Tian Ding, Ruoyu Sun, Benyou Wang, Dayiheng Liu, Fei Huang, Tianyu Liu, Bowen Yu, Junyang Lin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-24
🔗 代码/项目: GITHUB
💡 一句话要点
提出RealCritic以评估语言模型的批评能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 批评能力 闭环评估 推理任务 自我批评 交叉批评 迭代批评
📋 核心要点
- 现有方法在评估语言模型批评能力时面临开放性任务的挑战,难以量化批评的有效性。
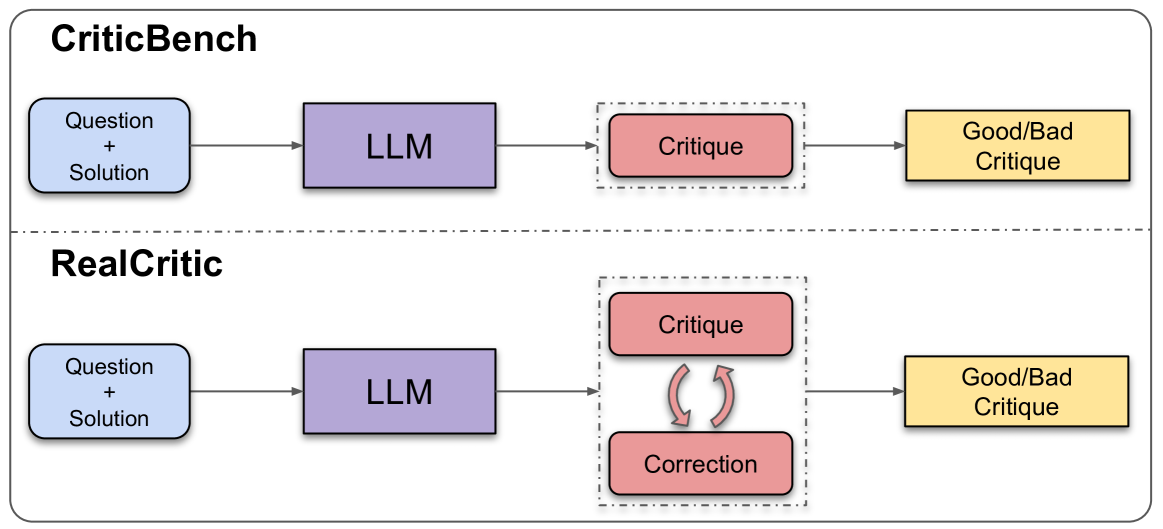
- 本文提出的RealCritic基准采用闭环方法,通过评估批评生成的修正质量来衡量LLMs的批评能力。
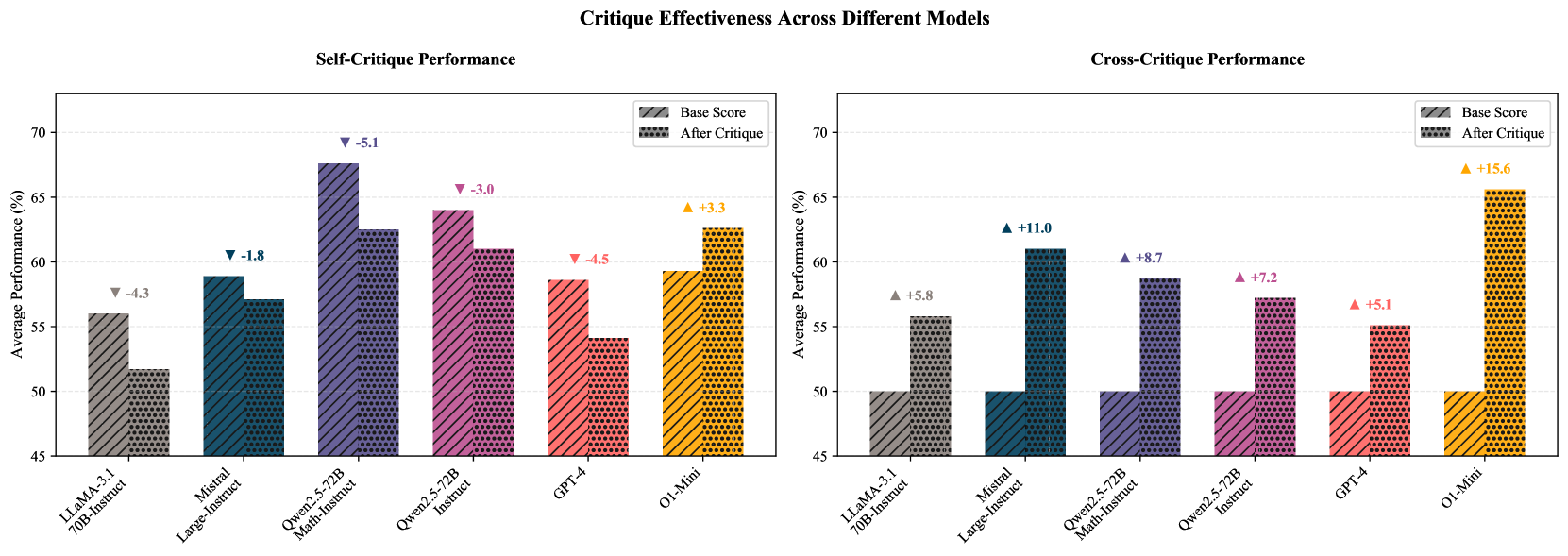
- 实验结果表明,传统LLMs在批评场景中表现不如先进推理模型o1-mini,尤其在自我批评和迭代批评设置中表现更差。
📝 摘要(中文)
批评对于提升大型语言模型(LLMs)的性能至关重要,它能够通过识别缺陷和提出改进建议来促进自我提升和为他人提供建设性反馈。然而,评估LLMs的批评能力面临显著挑战,主要由于任务的开放性。本文提出了一种新的基准,旨在评估LLMs的批评能力。与现有基准通常采用的开放式方法不同,我们的方法采用闭环方法,评估从批评中生成的修正质量。此外,该基准还结合了自我批评、交叉批评和迭代批评等特征,这对于区分先进推理模型与传统模型的能力至关重要。我们在八个具有挑战性的推理任务上实现了该基准,并发现传统LLMs在所有批评场景中显著落后于基于先进推理的模型o1-mini。希望该基准能为未来的进展提供有价值的资源。
🔬 方法详解
问题定义:本文旨在解决如何有效评估大型语言模型的批评能力这一具体问题。现有方法多为开放式评估,难以量化批评的实际效果。
核心思路:论文提出的闭环评估方法,通过分析批评生成的修正质量,提供了一种新的评估视角。这种设计能够更好地反映模型的实际批评能力。
技术框架:整体架构包括数据收集、批评生成、修正评估等主要模块。首先收集多样化的推理任务数据,然后通过LLMs生成批评,最后评估这些批评所产生的修正效果。
关键创新:最重要的技术创新在于引入了自我批评、交叉批评和迭代批评的机制,这些特征使得评估更加全面,能够有效区分不同模型的能力。
关键设计:在参数设置上,采用了多种推理任务以确保评估的广泛性;损失函数设计上,重点关注批评生成的修正质量,以此作为评估标准。
🖼️ 关键图片

📊 实验亮点
实验结果显示,传统LLMs在直接链式思维生成上与先进推理模型o1-mini表现相当,但在所有批评场景中,传统模型的表现显著落后。此外,在自我批评和迭代批评设置中,传统LLMs的表现甚至低于其基线能力,显示出其在批评能力上的不足。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、教育技术和人机交互等。通过有效评估语言模型的批评能力,可以为模型的自我改进和用户反馈提供指导,从而提升模型的实用性和可靠性。未来,该基准可能推动更智能的语言模型发展,促进人机协作的进步。
📄 摘要(原文)
Critiques are important for enhancing the performance of Large Language Models (LLMs), enabling both self-improvement and constructive feedback for others by identifying flaws and suggesting improvements. However, evaluating the critique capabilities of LLMs presents a significant challenge due to the open-ended nature of the task. In this work, we introduce a new benchmark designed to assess the critique capabilities of LLMs. Unlike existing benchmarks, which typically function in an open-loop fashion, our approach employs a closed-loop methodology that evaluates the quality of corrections generated from critiques. Moreover, the benchmark incorporates features such as self-critique, cross-critique, and iterative critique, which are crucial for distinguishing the abilities of advanced reasoning models from more classical ones. We implement this benchmark using eight challenging reasoning tasks. We have several interesting findings. First, despite demonstrating comparable performance in direct chain-of-thought generation, classical LLMs significantly lag behind the advanced reasoning-based model o1-mini across all critique scenarios. Second, in self-critique and iterative critique settings, classical LLMs may even underperform relative to their baseline capabilities. We hope that this benchmark will serve as a valuable resource to guide future advancements. The code and data are available at \url{https://github.com/tangzhy/RealCritic}.