Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing
作者: Zeping Yu, Sophia Ananiadou
分类: cs.CL
发布日期: 2025-01-24
备注: preprint
💡 一句话要点
提出CommonWords数据集与可解释神经元编辑方法,缓解LLM中的性别偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 性别偏见 神经元编辑 可解释性 偏见缓解
📋 核心要点
- 现有LLM缓解性别偏见的方法缺乏对偏见机制的深入理解,并且容易损害模型本身的性能。
- 论文提出一种可解释的神经元编辑方法,通过选择性地编辑LLM中负责性别偏见的特定神经元来缓解偏见。
- 实验表明,该方法在减少LLM性别偏见的同时,能够有效保留模型原有的能力,优于现有方法。
📝 摘要(中文)
大型语言模型(LLMs)常常表现出性别偏见,对其安全部署构成挑战。现有的偏见缓解方法缺乏对其机制的全面理解,或者会损害模型的核心能力。为了解决这些问题,我们提出了CommonWords数据集,以系统地评估LLM中的性别偏见。我们的分析揭示了模型中普遍存在的偏见,并识别出负责此行为的特定神经元回路,包括性别神经元和通用神经元。值得注意的是,由于神经元之间的分层交互,编辑少量通用神经元也会破坏模型的整体能力。基于这些见解,我们提出了一种可解释的神经元编辑方法,该方法结合了基于logit和基于因果关系的策略,以选择性地定位有偏见的神经元。在五个LLM上的实验表明,我们的方法有效地减少了性别偏见,同时保留了模型原有的能力,优于现有的微调和编辑方法。我们的研究成果贡献了一个新的数据集,对偏见机制的详细分析,以及一个缓解LLM性别偏见的实用解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中普遍存在的性别偏见问题。现有缓解偏见的方法要么缺乏对偏见内在机制的理解,导致效果不佳;要么会过度干预模型,损害其原有的语言能力。因此,如何既能有效减少LLM中的性别偏见,又能保持其原有的性能,是一个重要的挑战。
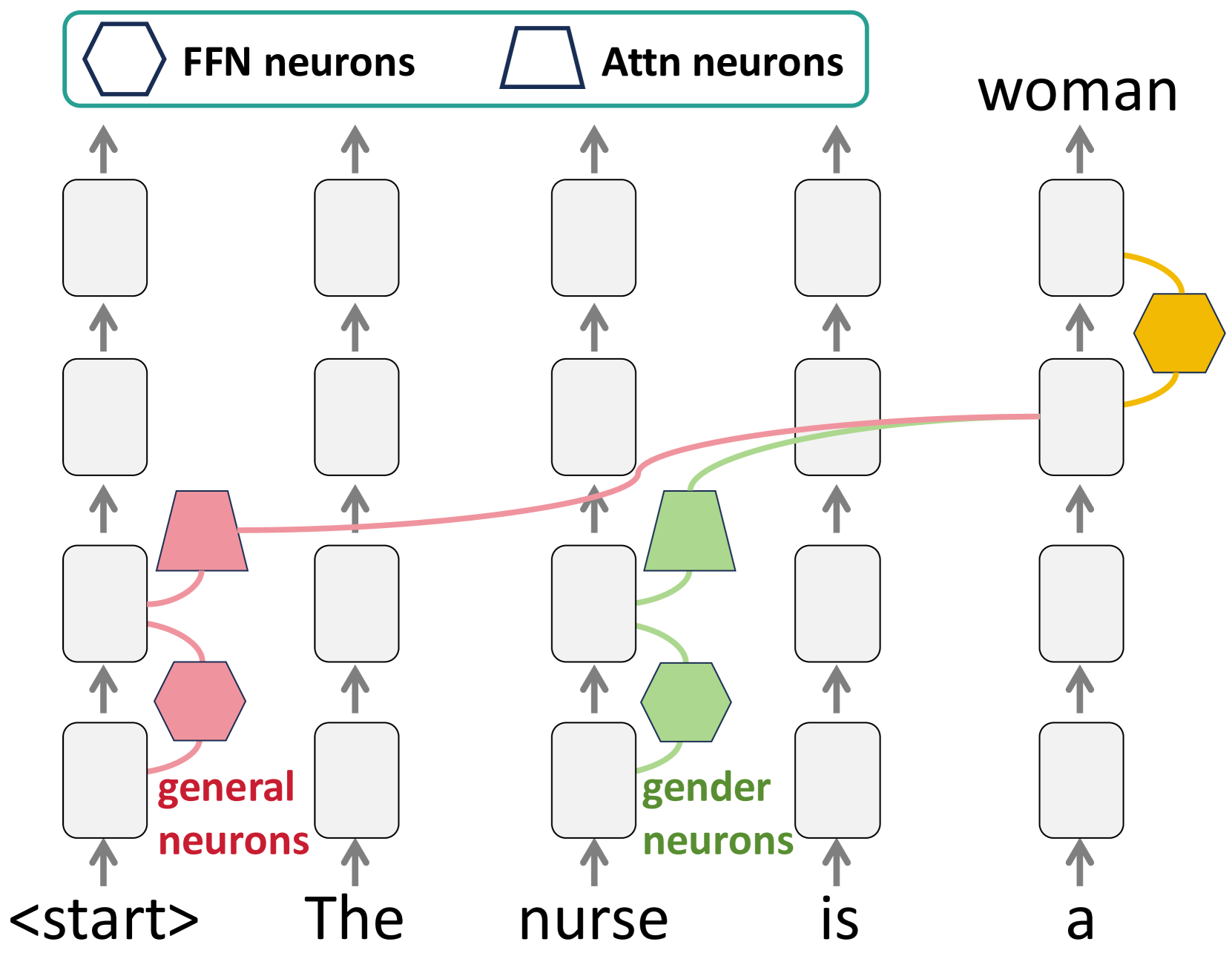
核心思路:论文的核心思路是通过识别并编辑LLM中负责性别偏见的特定神经元来实现偏见缓解。作者认为,LLM中的性别偏见并非随机分布,而是集中在某些特定的神经元回路中。通过精准定位这些神经元并进行干预,可以在不影响模型整体性能的前提下,有效地减少性别偏见。
技术框架:该方法主要包含以下几个阶段:1) 构建CommonWords数据集,用于系统评估LLM中的性别偏见;2) 分析LLM,识别出与性别偏见相关的神经元回路,包括性别神经元和通用神经元;3) 提出一种可解释的神经元编辑方法,该方法结合了基于logit和基于因果关系的策略,以选择性地定位并编辑有偏见的神经元;4) 在多个LLM上进行实验,评估该方法的有效性和性能。
关键创新:该方法最重要的创新点在于其可解释性和选择性。与以往的微调或全局编辑方法不同,该方法能够识别出导致性别偏见的特定神经元,并只对这些神经元进行干预。这种选择性的编辑方式可以最大限度地减少对模型整体性能的影响,同时有效地缓解性别偏见。此外,CommonWords数据集的构建也为系统评估LLM中的性别偏见提供了新的工具。
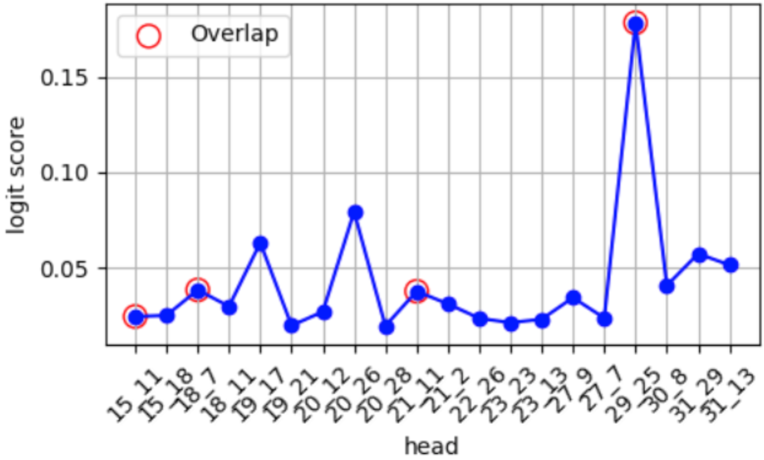
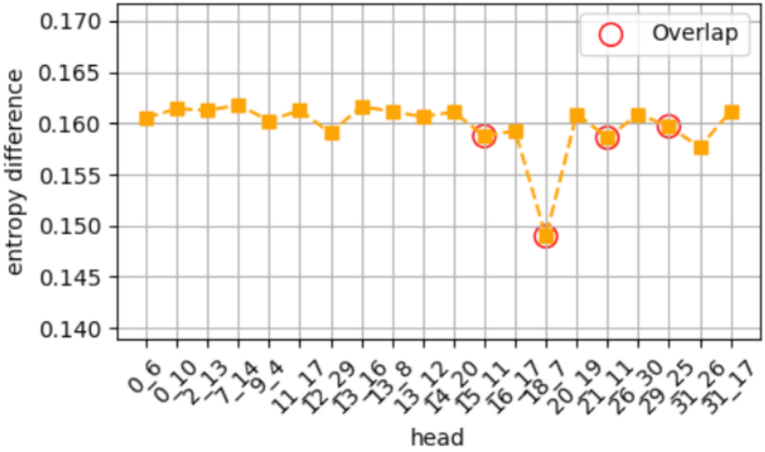
关键设计:该方法的关键设计包括:1) CommonWords数据集的设计,该数据集包含多种性别相关的上下文,可以更全面地评估LLM中的性别偏见;2) 基于logit和基于因果关系的神经元选择策略,该策略可以更准确地识别出与性别偏见相关的神经元;3) 神经元编辑的具体方法,例如,可以通过调整神经元的权重或激活函数来改变其行为。具体的参数设置和损失函数等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在五个LLM上均能有效减少性别偏见,同时保持模型原有的能力。与现有的微调和编辑方法相比,该方法在偏见缓解和性能保持方面均取得了更好的效果。具体的性能提升数据和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于各种需要使用LLM的场景,例如智能客服、文本生成、机器翻译等。通过缓解LLM中的性别偏见,可以提高这些应用的公平性和可靠性,避免产生歧视性或冒犯性的内容。未来,该方法可以进一步推广到其他类型的偏见缓解,例如种族偏见、宗教偏见等,从而构建更加公平和包容的人工智能系统。
📄 摘要(原文)
Large language models (LLMs) often exhibit gender bias, posing challenges for their safe deployment. Existing methods to mitigate bias lack a comprehensive understanding of its mechanisms or compromise the model's core capabilities. To address these issues, we propose the CommonWords dataset, to systematically evaluate gender bias in LLMs. Our analysis reveals pervasive bias across models and identifies specific neuron circuits, including gender neurons and general neurons, responsible for this behavior. Notably, editing even a small number of general neurons can disrupt the model's overall capabilities due to hierarchical neuron interactions. Based on these insights, we propose an interpretable neuron editing method that combines logit-based and causal-based strategies to selectively target biased neurons. Experiments on five LLMs demonstrate that our method effectively reduces gender bias while preserving the model's original capabilities, outperforming existing fine-tuning and editing approaches. Our findings contribute a novel dataset, a detailed analysis of bias mechanisms, and a practical solution for mitigating gender bias in LLMs.