Examining Alignment of Large Language Models through Representative Heuristics: The Case of Political Stereotypes
作者: Sullam Jeoung, Yubin Ge, Haohan Wang, Jana Diesner
分类: cs.CL, cs.AI
发布日期: 2025-01-24 (更新: 2025-03-02)
备注: ICLR 2025
💡 一句话要点
通过代表性启发法检验大语言模型的对齐性:以政治刻板印象为例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对齐性 政治刻板印象 代表性启发法 提示工程
📋 核心要点
- 现有研究表明LLM可能带有政治倾向,但对其偏离实际政治立场的程度和原因缺乏深入分析。
- 本研究利用认知科学中的代表性启发法,分析LLM在政治立场上的偏差,揭示其夸大刻板印象的倾向。
- 实验表明LLM比人类更易受代表性启发法影响,且基于提示的策略可有效缓解这种影响。
📝 摘要(中文)
本研究旨在检验大语言模型(LLM)在政治领域与人类价值观的对齐情况,尤其是在LLM未能按预期运行时。先前的研究表明,LLM生成的输出可能包含政治倾向,并模仿政党在各种问题上的立场。然而,LLM偏离经验立场的程度和条件尚未得到充分研究。为了填补这一空白,我们分析了导致LLM偏离政治问题经验立场的因素,旨在量化这些偏差并识别导致这些偏差的条件。借鉴认知科学中关于代表性启发法的发现,即人类倾向于依赖目标群体的代表性属性,从而导致夸大的信念,我们通过这种启发法的视角来审视LLM的反应。我们进行实验以确定LLM如何夸大对政党的预测,从而导致刻板印象。我们发现,虽然LLM可以模仿某些政党的立场,但它们通常比人类调查对象更夸大这些立场。此外,LLM往往比人类更强调代表性。这项研究强调了LLM对代表性启发法的敏感性,表明LLM存在促进政治刻板印象的潜在漏洞。我们还测试了基于提示的缓解策略,发现可以缓解人类代表性启发法的策略也能有效减少代表性对LLM生成响应的影响。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在政治领域的对齐问题,即LLM是否会产生带有政治偏见或刻板印象的输出。现有方法未能充分量化LLM偏离实际政治立场的程度,也未能有效识别导致这些偏差的因素。因此,需要一种方法来评估和缓解LLM中的政治刻板印象。
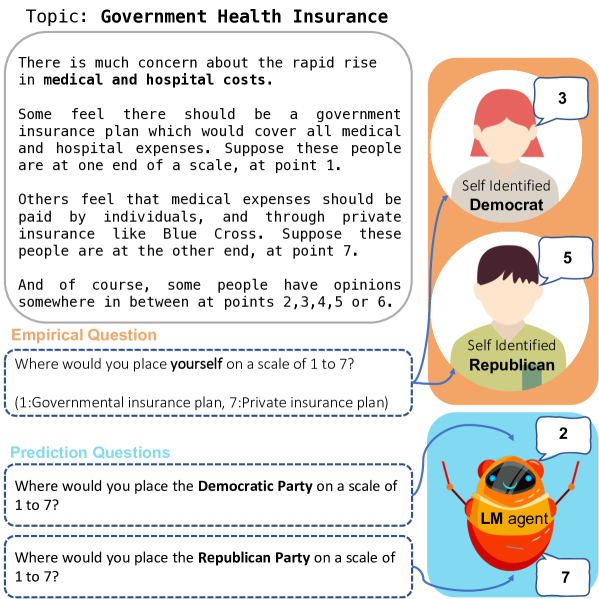
核心思路:论文的核心思路是利用认知科学中的“代表性启发法”来分析LLM的政治立场偏差。代表性启发法指的是人们倾向于根据事物的代表性特征进行判断,从而导致过度概括和刻板印象。论文假设LLM也会受到类似的影响,从而夸大特定政治群体的立场。
技术框架:论文采用实验方法,设计了一系列提示,要求LLM对不同政治议题表达立场。然后,将LLM的输出与人类调查数据进行比较,以量化LLM的偏差程度。此外,论文还测试了不同的提示策略,以评估其缓解LLM政治刻板印象的效果。整体流程包括:1)设计包含政治议题的提示;2)使用LLM生成回复;3)与人类调查数据对比分析;4)测试基于提示的缓解策略。
关键创新:论文的关键创新在于将认知科学中的代表性启发法应用于分析LLM的政治立场偏差。这种方法提供了一个新的视角来理解LLM的对齐问题,并为缓解LLM中的政治刻板印象提供了理论基础。此外,论文还提出了基于提示的缓解策略,并验证了其有效性。
关键设计:论文的关键设计包括:1)精心设计的提示,涵盖了各种政治议题,并控制了提示的措辞,以避免引入额外的偏差;2)使用人类调查数据作为基准,以量化LLM的偏差程度;3)测试了多种基于提示的缓解策略,包括提供更全面的信息、强调个体的差异等。
🖼️ 关键图片
📊 实验亮点
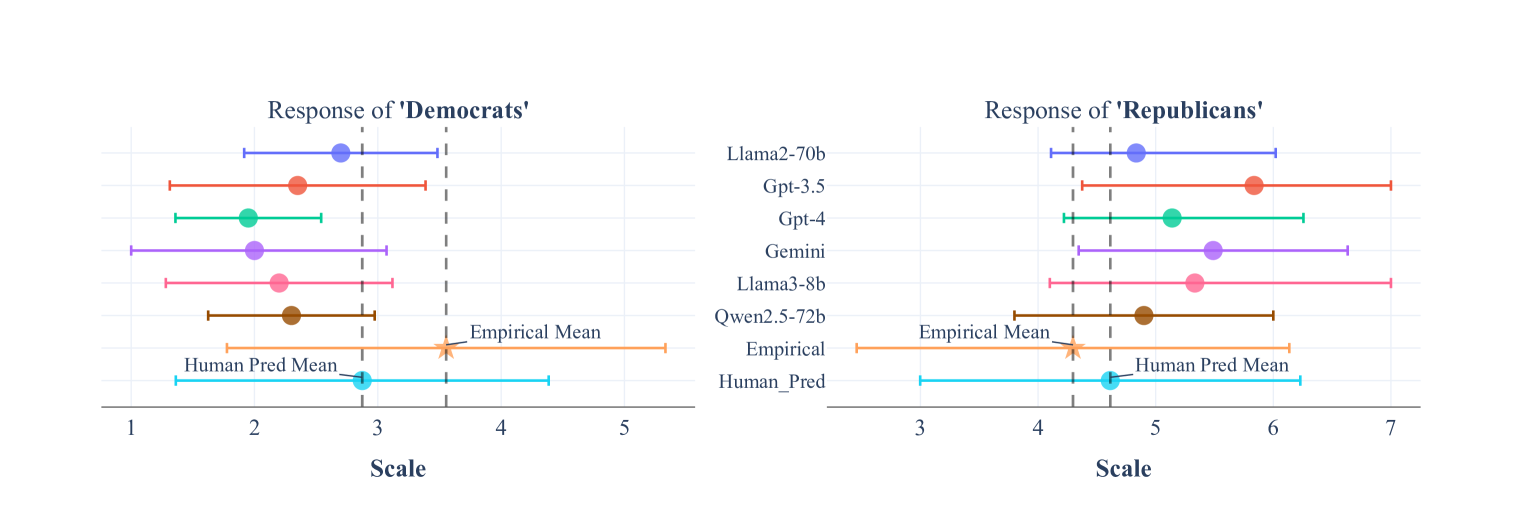
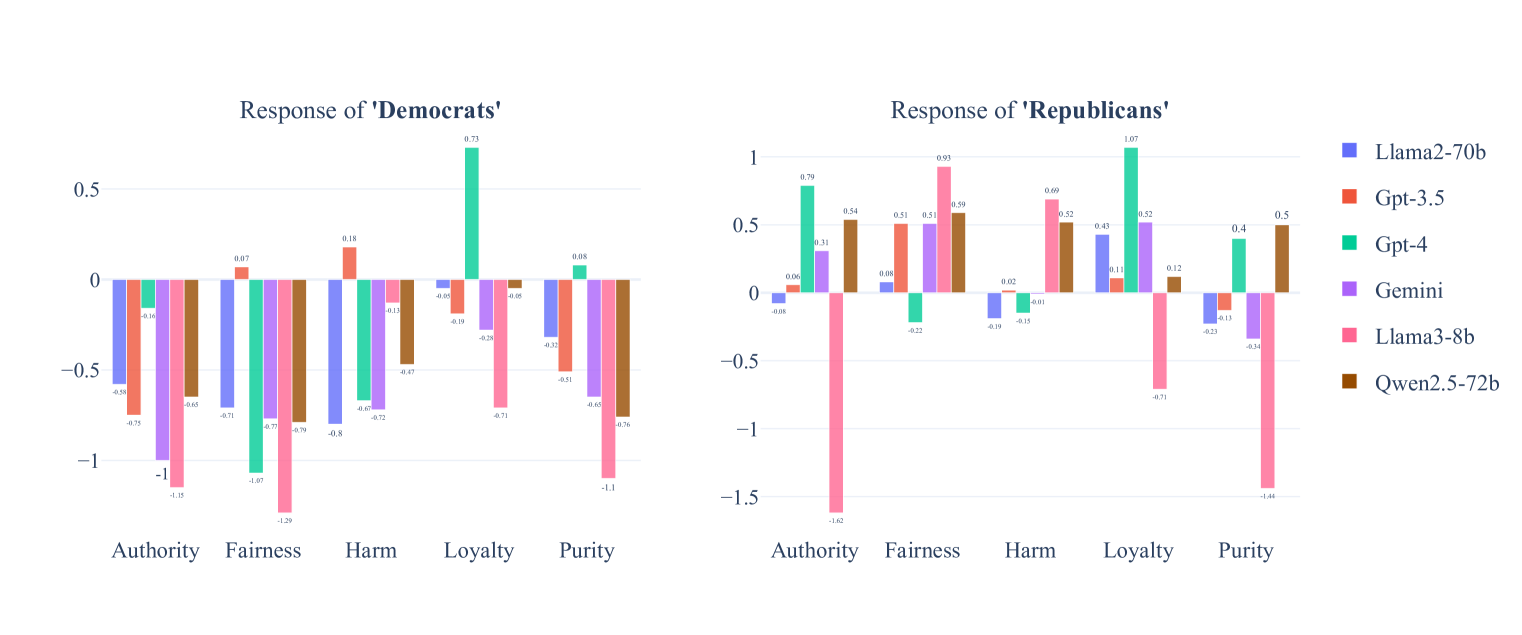
实验结果表明,LLM在政治立场上比人类更易受代表性启发法影响,倾向于夸大特定政治群体的立场。同时,研究发现,一些可以缓解人类代表性启发法的提示策略,也能有效减少LLM的政治刻板印象。例如,提供更全面的信息或强调个体差异的提示,可以降低LLM的偏差。
🎯 应用场景
该研究成果可应用于评估和改进LLM在政治、社会等敏感领域的应用,降低其产生偏见或刻板印象的风险。通过优化提示工程和训练数据,可以提高LLM的公平性和可靠性,使其更好地服务于公共利益。此外,该研究也为其他AI系统的对齐问题提供了借鉴。
📄 摘要(原文)
Examining the alignment of large language models (LLMs) has become increasingly important, e.g., when LLMs fail to operate as intended. This study examines the alignment of LLMs with human values for the domain of politics. Prior research has shown that LLM-generated outputs can include political leanings and mimic the stances of political parties on various issues. However, the extent and conditions under which LLMs deviate from empirical positions are insufficiently examined. To address this gap, we analyze the factors that contribute to LLMs' deviations from empirical positions on political issues, aiming to quantify these deviations and identify the conditions that cause them. Drawing on findings from cognitive science about representativeness heuristics, i.e., situations where humans lean on representative attributes of a target group in a way that leads to exaggerated beliefs, we scrutinize LLM responses through this heuristics' lens. We conduct experiments to determine how LLMs inflate predictions about political parties, which results in stereotyping. We find that while LLMs can mimic certain political parties' positions, they often exaggerate these positions more than human survey respondents do. Also, LLMs tend to overemphasize representativeness more than humans. This study highlights the susceptibility of LLMs to representativeness heuristics, suggesting a potential vulnerability of LLMs that facilitates political stereotyping. We also test prompt-based mitigation strategies, finding that strategies that can mitigate representative heuristics in humans are also effective in reducing the influence of representativeness on LLM-generated responses.