Leveraging Online Olympiad-Level Math Problems for LLMs Training and Contamination-Resistant Evaluation
作者: Sadegh Mahdavi, Muchen Li, Kaiwen Liu, Christos Thrampoulidis, Leonid Sigal, Renjie Liao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-24 (更新: 2025-06-27)
备注: ICML 2025 Camera Ready
🔗 代码/项目: GITHUB
💡 一句话要点
提出AoPS-Instruct数据集和LiveAoPSBench,提升LLM奥数问题求解能力并进行抗污染评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 奥数问题求解 数据集构建 抗污染评估 自动化流程
📋 核心要点
- 现有奥数数据集规模有限且易受污染,难以有效训练和评估LLM的推理能力。
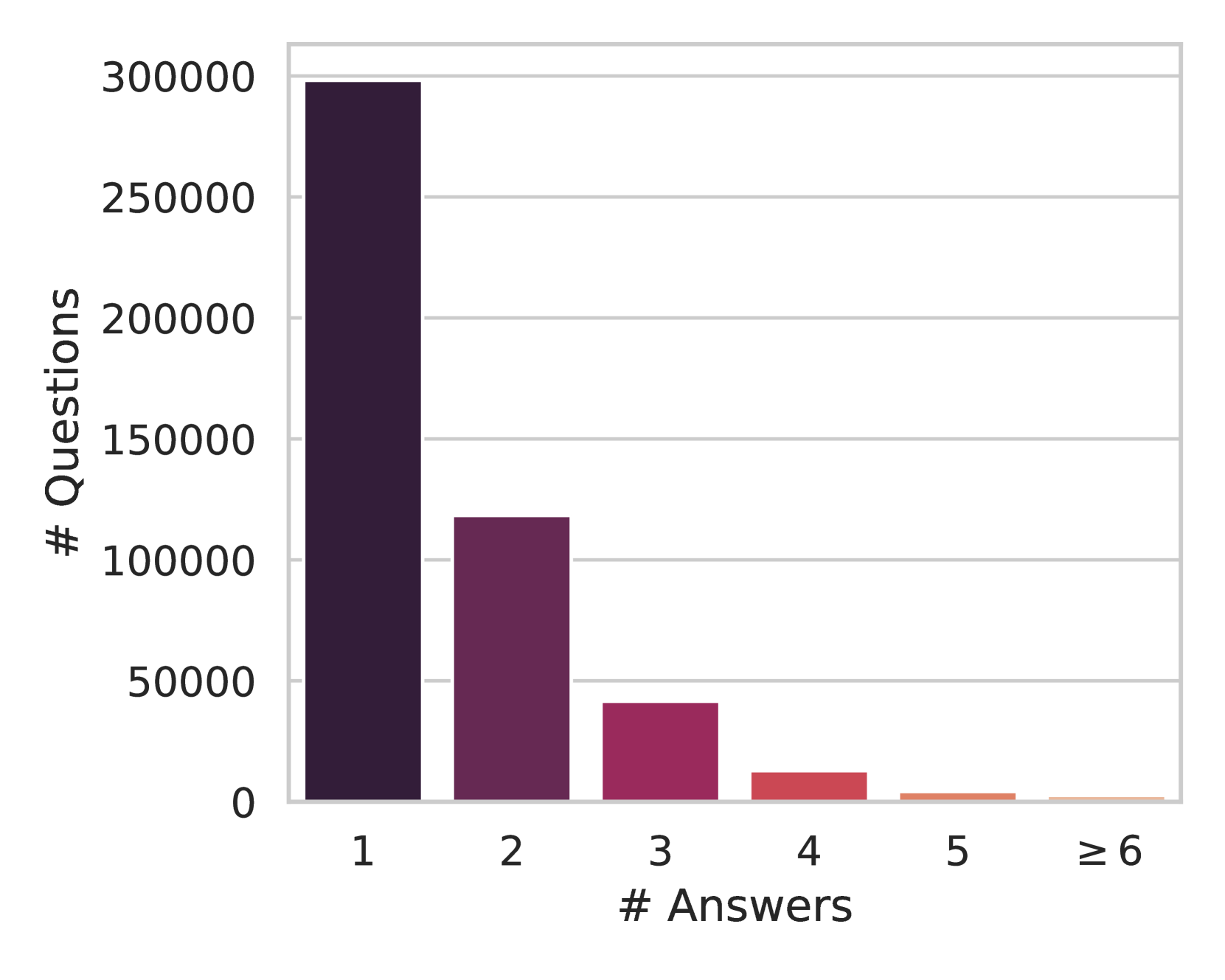
- 利用AoPS论坛资源,自动化构建大规模高质量的AoPS-Instruct数据集,用于LLM的微调。
- 提出LiveAoPSBench,一个基于时间戳的动态评估基准,有效抵抗数据污染,更准确评估LLM性能。
📝 摘要(中文)
大型语言模型(LLM)在解决奥林匹克级别数学问题方面的能力引起了广泛关注。然而,训练和评估这些模型受到可用数据集规模和质量的限制,因为为此类高级问题创建大规模数据需要人类专家的付出。此外,当前的基准测试容易受到污染,导致评估结果不可靠。本文提出了一个自动化流程,利用了Art of Problem Solving (AoPS)论坛的丰富资源,该论坛主要提供奥林匹克级别的问题和社区驱动的解决方案。使用开源LLM,我们开发了一种从论坛中提取问答对的方法,从而生成了包含超过60万个高质量QA对的AoPS-Instruct数据集。实验表明,在AoPS-Instruct上微调LLM可以提高它们在各种基准测试中的推理能力。此外,我们构建了一个自动流程,引入了LiveAoPSBench,这是一个具有时间戳的演进评估集,源自最新的论坛数据,为评估LLM性能提供了一个抗污染的基准。值得注意的是,我们观察到LLM的性能随时间显著下降,这表明它们在较旧示例上的成功可能源于预训练暴露,而不是真正的推理能力。我们的工作提出了一种可扩展的方法来创建和维护用于高级数学推理的大规模、高质量数据集,为LLM在该领域的能力和局限性提供了有价值的见解。
🔬 方法详解
问题定义:论文旨在解决LLM在奥数问题求解中训练数据不足和评估基准易受污染的问题。现有方法依赖人工标注,成本高昂且规模有限。同时,公开数据集可能已被LLM预训练,导致评估结果虚高,无法真实反映模型的推理能力。
核心思路:论文的核心思路是利用Art of Problem Solving (AoPS) 论坛中丰富的奥数问题和社区解答资源,通过自动化流程构建大规模高质量的数据集,并设计动态更新的评估基准。这种方法降低了数据获取成本,并能有效避免数据污染。
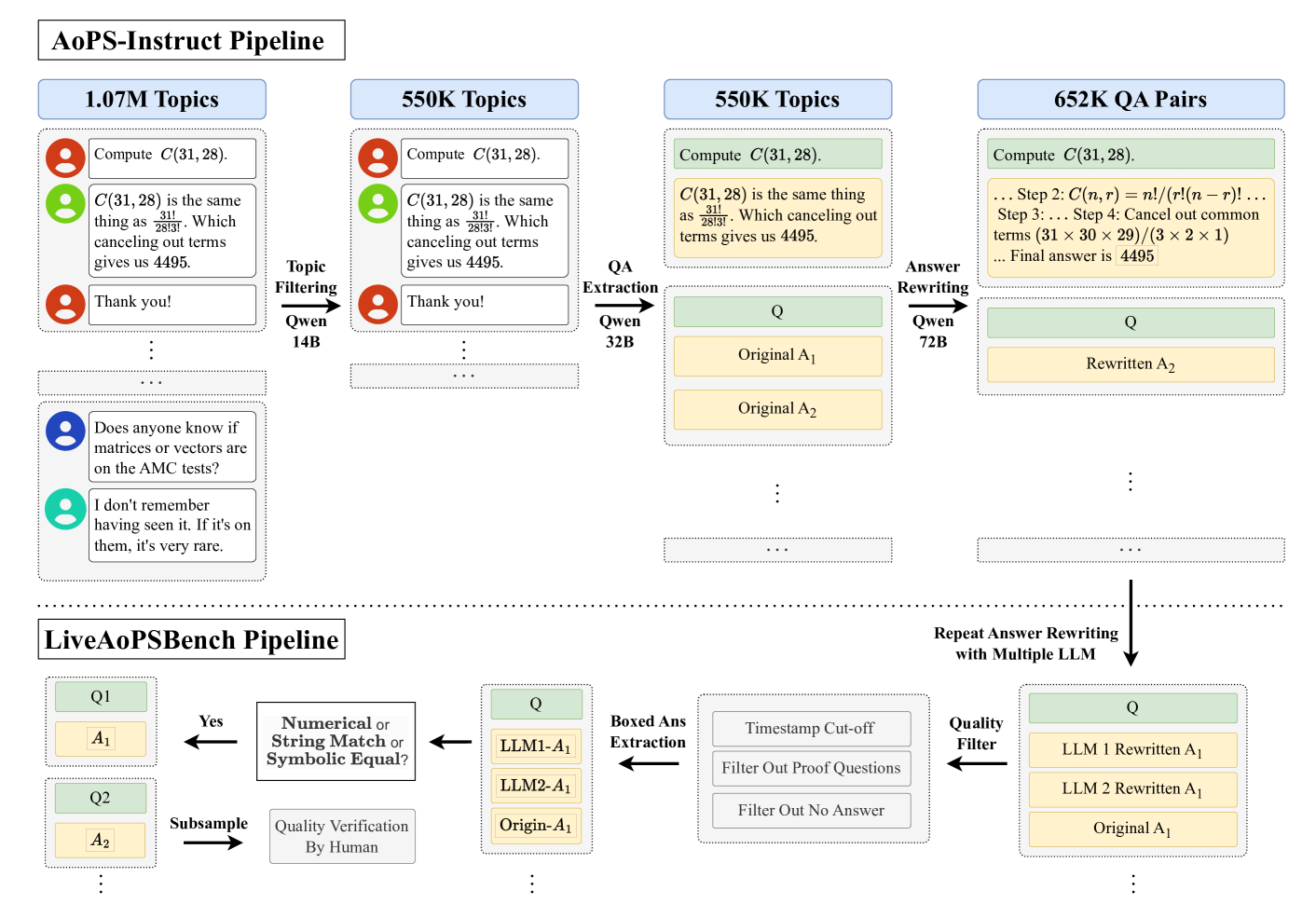
技术框架:整体框架包含两个主要部分:AoPS-Instruct数据集构建和LiveAoPSBench评估基准构建。AoPS-Instruct数据集构建流程包括:1) 从AoPS论坛抓取数据;2) 使用LLM提取问答对;3) 对提取的问答对进行清洗和过滤。LiveAoPSBench评估基准构建流程包括:1) 定期从AoPS论坛抓取新的问题;2) 自动生成评估集;3) 记录问题发布时间,用于抗污染评估。
关键创新:论文的关键创新在于提出了一种可扩展的自动化流程,能够从在线论坛中提取高质量的奥数问题和解答,从而构建大规模的训练数据集和动态评估基准。这种方法不仅降低了数据获取成本,而且能够有效避免数据污染,提供更可靠的LLM性能评估。
关键设计:在AoPS-Instruct数据集构建中,使用了开源LLM进行问答对提取,并设计了相应的prompt工程。在LiveAoPSBench评估基准构建中,关键在于利用问题发布时间进行抗污染评估,通过分析LLM在不同时间段发布的问题上的表现,判断模型是否受到预训练数据的影响。
🖼️ 关键图片
📊 实验亮点
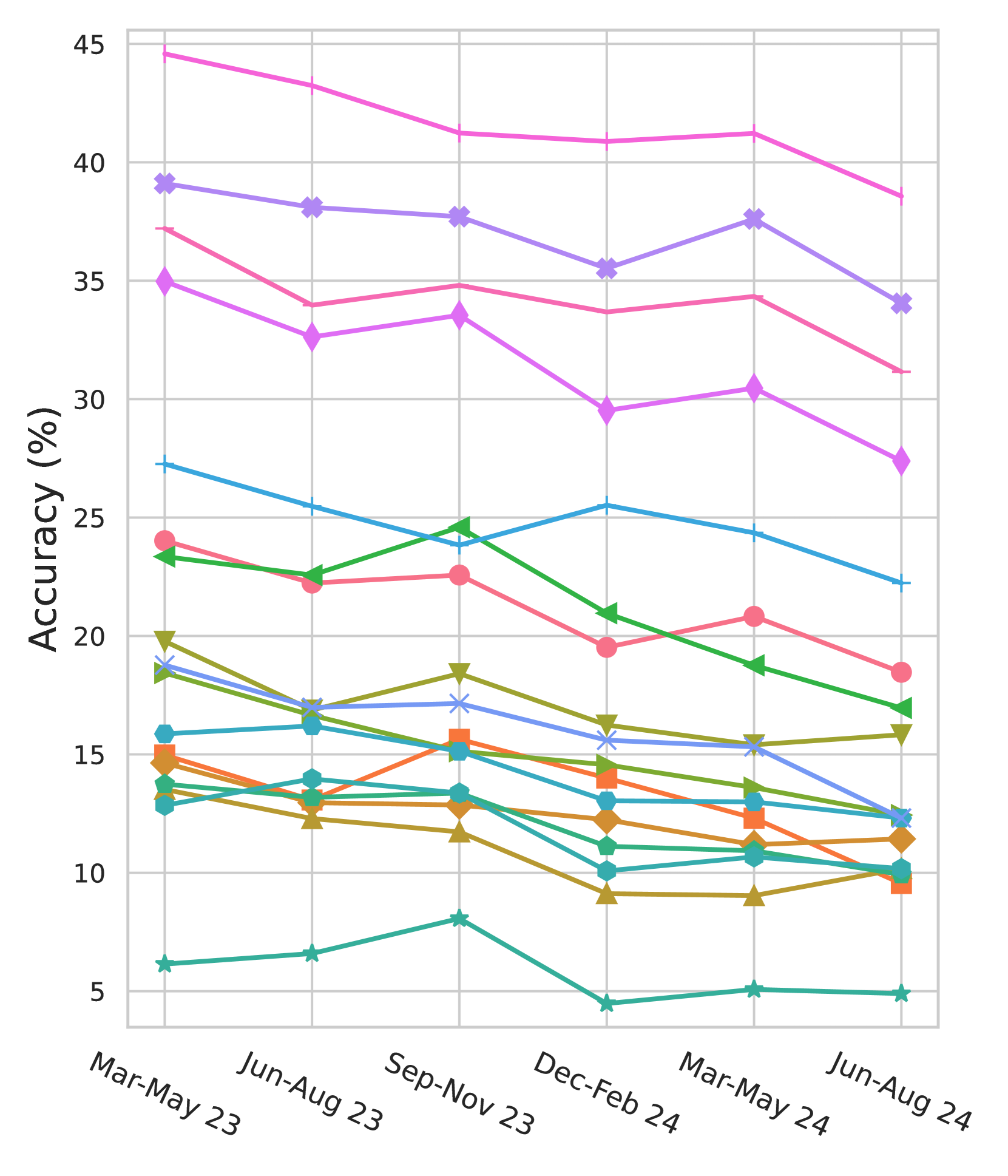
实验结果表明,在AoPS-Instruct数据集上微调LLM可以显著提高其在各种奥数基准测试中的性能。同时,使用LiveAoPSBench进行评估发现,LLM在较早发布的问题上的性能较高,但在较新发布的问题上的性能显著下降,这表明LLM的成功可能部分源于预训练数据的污染。
🎯 应用场景
该研究成果可应用于提升LLM在数学推理、逻辑推理等方面的能力,并可推广到其他需要专业知识的领域,例如法律、医学等。此外,该研究提出的抗污染评估方法,可用于更客观地评估LLM的真实能力,避免模型过度依赖预训练数据。
📄 摘要(原文)
Advances in Large Language Models (LLMs) have sparked interest in their ability to solve Olympiad-level math problems. However, the training and evaluation of these models are constrained by the limited size and quality of available datasets, as creating large-scale data for such advanced problems requires extensive effort from human experts. In addition, current benchmarks are prone to contamination, leading to unreliable evaluations. In this paper, we present an automated pipeline that leverages the rich resources of the Art of Problem Solving (AoPS) forum, which predominantly features Olympiad-level problems and community-driven solutions. Using open-source LLMs, we develop a method to extract question-answer pairs from the forum, resulting in AoPS-Instruct, a dataset of more than 600,000 high-quality QA pairs. Our experiments demonstrate that fine-tuning LLMs on AoPS-Instruct improves their reasoning abilities across various benchmarks. Moreover, we build an automatic pipeline that introduces LiveAoPSBench, an evolving evaluation set with timestamps, derived from the latest forum data, providing a contamination-resistant benchmark for assessing LLM performance. Notably, we observe a significant decline in LLM performance over time, suggesting their success on older examples may stem from pre-training exposure rather than true reasoning ability. Our work presents a scalable approach to creating and maintaining large-scale, high-quality datasets for advanced math reasoning, offering valuable insights into the capabilities and limitations of LLMs in this domain. Our benchmark and code is available at https://github.com/DSL-Lab/aops