Multi-agent KTO: Reinforcing Strategic Interactions of Large Language Model in Language Game
作者: Rong Ye, Yongxin Zhang, Yikai Zhang, Haoyu Kuang, Zhongyu Wei, Peng Sun
分类: cs.CL, cs.AI, cs.HC
发布日期: 2025-01-24 (更新: 2025-03-13)
备注: Preprint. Code and data will be available at https://reneeye.github.io/MaKTO.html
💡 一句话要点
提出多智能体KTO,通过语言游戏强化大语言模型的策略交互能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体 语言游戏 强化学习 策略交互 狼人杀 大语言模型 KTO 社交推理
📋 核心要点
- 现有方法在训练语言智能体时,通常将决策和语言表达分离,缺乏上下文交互学习。
- MaKTO通过让智能体参与狼人杀游戏,生成理想和不可接受的回复,利用KTO优化决策。
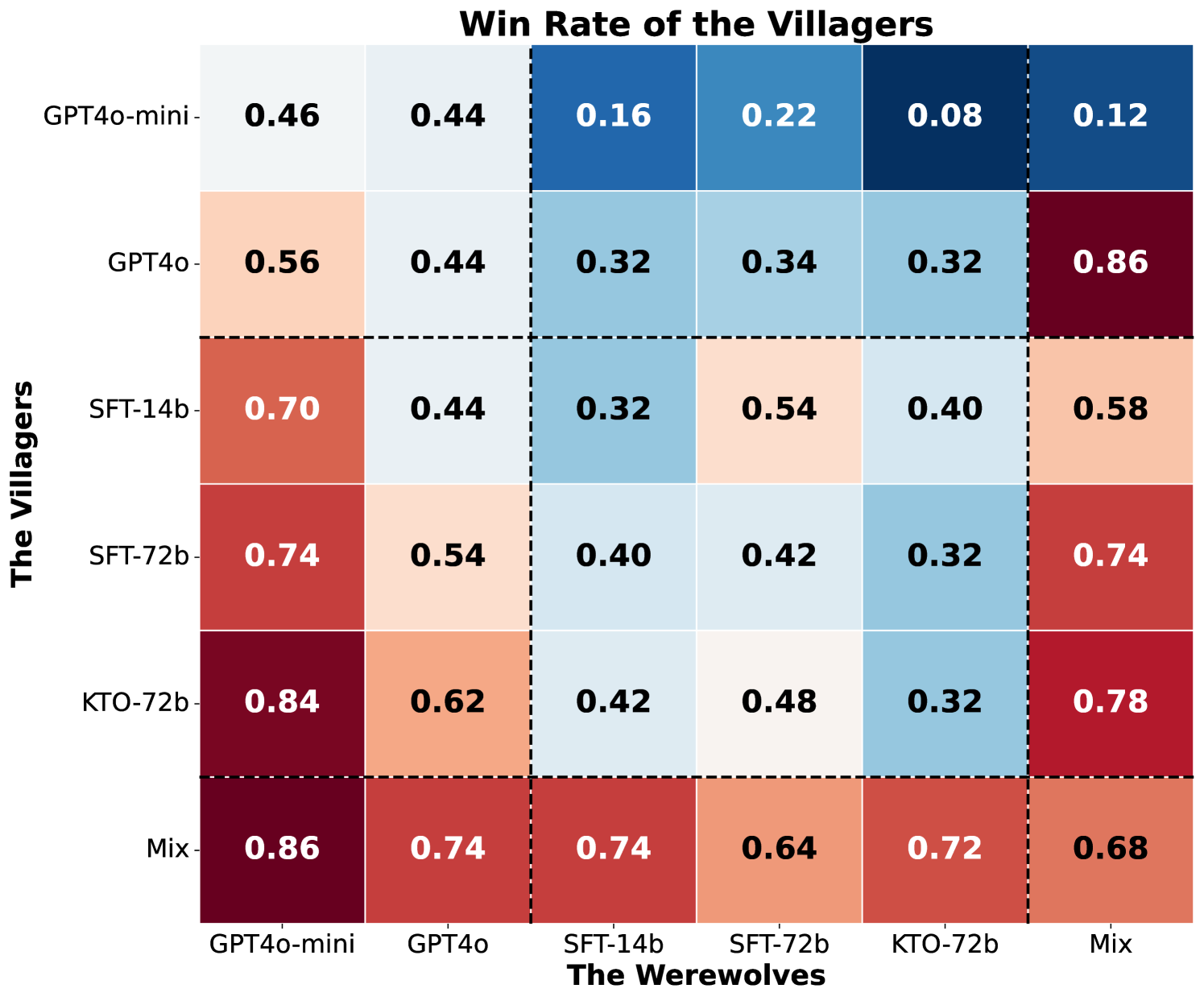
- 实验表明,MaKTO在狼人杀游戏中胜率显著高于GPT-4o和两阶段强化学习智能体,接近人类水平。
📝 摘要(中文)
为了实现通用人工智能(AGI),AI智能体不仅需要具备策略决策能力,还需要进行灵活且有意义的沟通。受维特根斯坦《哲学研究》中语言游戏理论的启发,我们提出语言智能体可以通过上下文交互进行学习,而不是将决策与语言表达分离的传统多阶段框架。我们使用狼人杀这款考验语言理解、策略交互和适应性的社交推理游戏,开发了多智能体卡尼曼-特沃斯基优化(MaKTO)。MaKTO让不同的模型参与到大量的游戏对局中,生成成对的理想和不可接受的回复,然后利用KTO来优化模型的决策过程。在9人狼人杀游戏中,MaKTO在各种模型上实现了61%的平均胜率,相对于GPT-4o和两阶段强化学习智能体,分别提高了23.0%和10.9%。值得注意的是,MaKTO还表现出类似人类的表现,在与专家玩家的对战中胜率为60%,并且在图灵风格的盲测中只有49%的可检测性。
🔬 方法详解
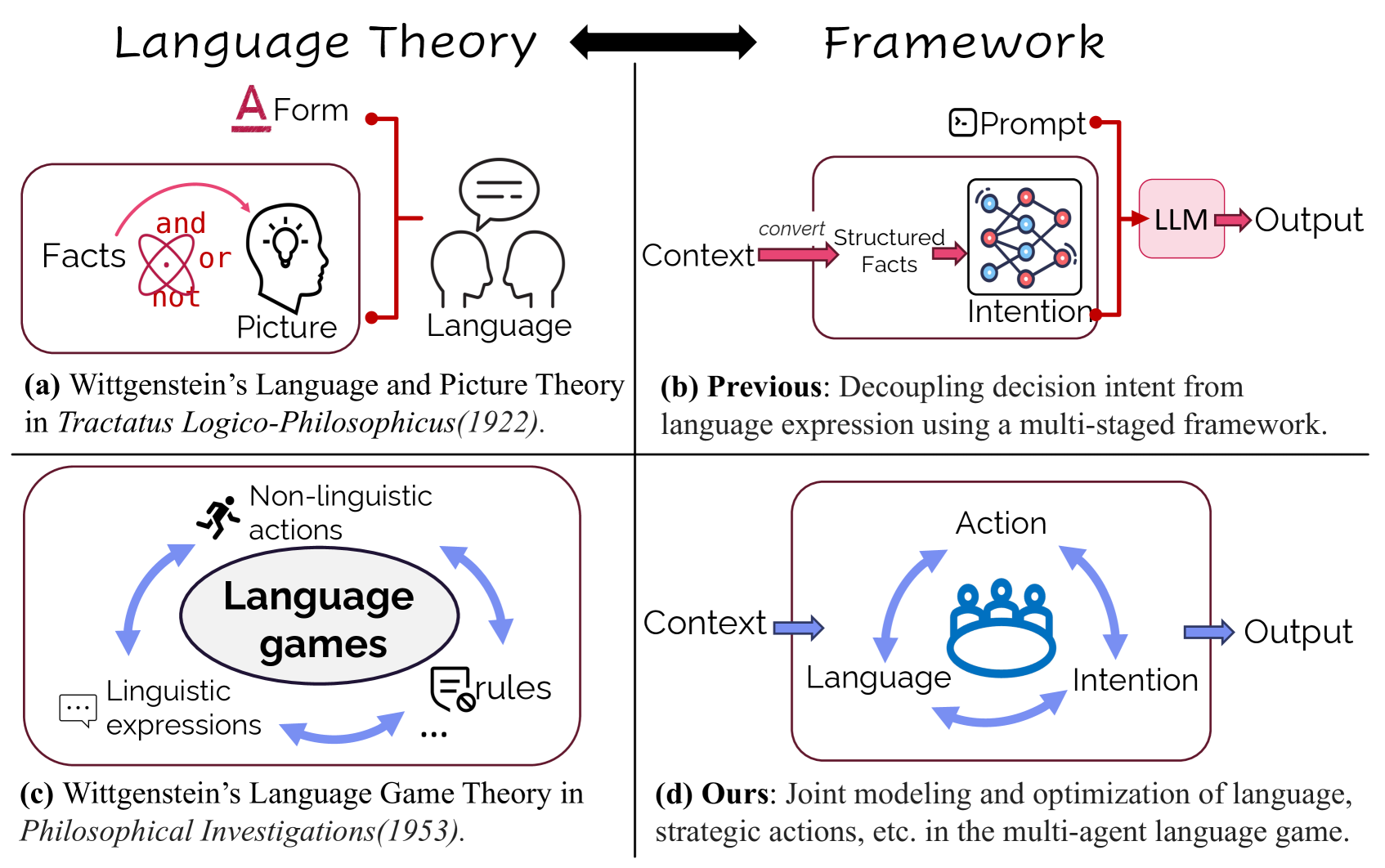
问题定义:现有的大语言模型在进行策略性交互时,通常采用多阶段框架,将决策制定和语言表达分开处理。这种分离的方式忽略了语言在策略互动中的重要作用,限制了模型在复杂社交环境中的适应性和表现。因此,如何让大语言模型在交互中学习策略,并自然地表达出来,是一个亟待解决的问题。
核心思路:本文的核心思路是借鉴维特根斯坦的语言游戏理论,将语言智能体的学习过程置于一个动态的、交互式的环境中。通过大量的游戏对局,智能体可以观察到不同行为带来的结果,并从中学习到有效的策略。同时,利用KTO算法,可以有效地对智能体的行为进行优化,使其能够更好地适应不同的游戏场景。
技术框架:MaKTO的整体框架包括以下几个主要部分:1) 游戏环境:选择狼人杀作为测试环境,因为它需要智能体具备语言理解、策略推理和社交互动能力。2) 多智能体交互:让不同的语言模型参与到大量的狼人杀游戏中,生成游戏数据。3) 数据收集:记录智能体在游戏中的行为和结果,包括理想的回复和不可接受的回复。4) KTO优化:利用KTO算法,根据收集到的数据,对智能体的决策过程进行优化。
关键创新:MaKTO的关键创新在于它将语言游戏理论与KTO算法相结合,提出了一种新的语言智能体学习方法。与传统的强化学习方法相比,MaKTO不需要显式的奖励函数,而是通过对比理想和不可接受的回复,来引导智能体的学习。此外,MaKTO还能够有效地利用多智能体交互产生的数据,提高学习效率。
关键设计:在MaKTO中,KTO算法被用于优化语言模型的策略。具体来说,对于每个智能体,KTO会根据其在游戏中的行为,计算出一个优势函数。该函数表示了该行为相对于其他行为的优劣程度。然后,KTO会利用这个优势函数,来更新智能体的策略,使其更倾向于选择优势更高的行为。此外,为了提高学习效率,MaKTO还采用了经验回放和目标网络等技术。
🖼️ 关键图片

📊 实验亮点
MaKTO在9人狼人杀游戏中取得了显著的成果,平均胜率达到61%,超过了GPT-4o(23.0%的相对提升)和两阶段强化学习智能体(10.9%的相对提升)。更重要的是,MaKTO展现出了接近人类的表现,在与专家玩家的对战中胜率为60%,并且在图灵测试中只有49%的可检测性,表明其语言行为具有较高的人类相似度。
🎯 应用场景
MaKTO的研究成果可以应用于各种需要策略性交互的场景,例如谈判、辩论、客户服务等。通过训练具有类似人类水平的语言智能体,可以提高沟通效率,改善人机交互体验。此外,该方法还可以用于开发更智能的对话系统和游戏AI,为人们提供更丰富、更有趣的娱乐体验。未来,该研究有望推动通用人工智能的发展,使AI能够更好地理解和适应人类社会。
📄 摘要(原文)
Achieving Artificial General Intelligence (AGI) requires AI agents that can not only make stratigic decisions but also engage in flexible and meaningful communication. Inspired by Wittgenstein's language game theory in Philosophical Investigations, we propose that language agents can learn through in-context interaction rather than traditional multi-stage frameworks that separate decision-making from language expression. Using Werewolf, a social deduction game that tests language understanding, strategic interaction, and adaptability, we develop the Multi-agent Kahneman & Tversky's Optimization (MaKTO). MaKTO engages diverse models in extensive gameplay to generate unpaired desirable and unacceptable responses, then employs KTO to refine the model's decision-making process. In 9-player Werewolf games, MaKTO achieves a 61% average win rate across various models, outperforming GPT-4o and two-stage RL agents by relative improvements of 23.0% and 10.9%, respectively. Notably, MaKTO also demonstrates human-like performance, winning 60% against expert players and showing only 49% detectability in Turing-style blind tests.