AdEval: Alignment-based Dynamic Evaluation to Mitigate Data Contamination in Large Language Models
作者: Yang Fan
分类: cs.CL, cs.AI
发布日期: 2025-01-23 (更新: 2025-08-12)
备注: There are serious academic problems in this paper, such as data falsification and plagiarism in the method of the paper
💡 一句话要点
AdEval:一种基于对齐的动态评估方法,用于缓解大语言模型中的数据污染问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据污染 动态评估 知识点提取 布鲁姆认知层次 模型评估 对齐学习
📋 核心要点
- 大型语言模型面临数据污染问题,导致静态评估基准高估模型性能。
- AdEval通过动态生成评估数据,避免直接依赖静态数据集,降低数据污染风险。
- 实验表明,AdEval能有效缓解数据污染,提升评估的公平性、可靠性和多样性。
📝 摘要(中文)
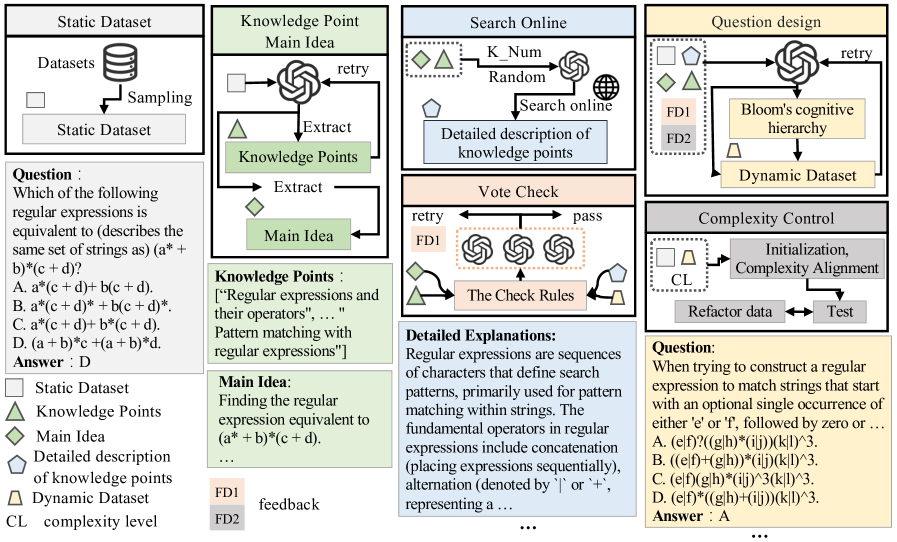
随着大型语言模型(LLMs)在超大规模语料库上进行预训练,数据污染问题日益严重,静态评估基准存在高估LLMs性能的风险。为了解决这个问题,本文提出了一种名为AdEval(Alignment-based Dynamic Evaluation)的动态数据评估方法。AdEval首先从静态数据集中提取知识点和主要思想,以实现与静态基准核心内容的动态对齐,并通过避免直接依赖静态数据集,从源头上降低了数据污染的风险。然后,它通过在线搜索获取背景信息,以生成知识点的详细描述。最后,它基于布鲁姆认知层次结构,围绕记忆、理解、应用、分析、评估和创造六个维度设计问题,以实现多层次的认知评估。此外,AdEval通过迭代的问题重构来控制动态生成数据集的复杂性。在多个数据集上的实验结果表明,AdEval有效地缓解了数据污染对评估结果的影响,解决了复杂性控制不足和单维度评估的问题,并提高了LLMs评估的公平性、可靠性和多样性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在超大规模语料库上预训练时,由于数据污染导致静态评估基准高估模型性能的问题。现有静态评估方法的痛点在于,LLMs可能已经见过评估数据集中的数据,从而导致评估结果失真,无法真实反映模型的泛化能力。
核心思路:AdEval的核心思路是通过动态生成评估数据来避免直接使用静态数据集,从而从根本上降低数据污染的风险。它通过提取静态数据集中的知识点和主要思想,并基于这些知识点动态生成新的问题,以此来评估LLMs的真实能力。这种方法的核心在于“对齐”,即动态生成的数据与静态基准的核心内容保持对齐,但形式上完全不同。
技术框架:AdEval的整体框架包含三个主要阶段:1) 知识点提取与对齐:从静态数据集中提取知识点和主要思想,确保动态生成的数据与静态基准的核心内容对齐。2) 背景信息获取与描述生成:通过在线搜索获取知识点的背景信息,并生成详细的知识点描述。3) 问题设计与生成:基于布鲁姆认知层次结构(记忆、理解、应用、分析、评估、创造)设计问题,并根据知识点描述生成多层次的认知评估问题。同时,通过迭代的问题重构来控制生成数据集的复杂性。
关键创新:AdEval最重要的技术创新点在于其动态评估的理念,即通过动态生成评估数据来避免直接使用静态数据集,从而从根本上降低数据污染的风险。与现有方法相比,AdEval不依赖于预先存在的静态数据集,而是根据知识点动态生成评估数据,这使得评估结果更加可靠和公正。
关键设计:AdEval的关键设计包括:1) 基于布鲁姆认知层次结构的问题设计,确保评估覆盖多个认知维度。2) 通过在线搜索获取背景信息,保证生成的问题具有足够的深度和广度。3) 迭代的问题重构机制,用于控制生成数据集的复杂性,避免生成过于简单或过于复杂的问题。具体的参数设置和损失函数等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
AdEval在多个数据集上的实验结果表明,该方法能够有效缓解数据污染对评估结果的影响,解决了传统静态评估方法中复杂性控制不足和单维度评估的问题。实验数据未提供具体的性能指标和提升幅度,但强调了AdEval在提高LLMs评估的公平性、可靠性和多样性方面的有效性。
🎯 应用场景
AdEval可应用于各种大型语言模型的评估,尤其是在模型训练数据规模庞大且数据污染风险较高的情况下。该方法能够提供更公平、可靠的性能评估,帮助研究人员和开发者更好地了解模型的真实能力,并指导模型改进方向。此外,AdEval的动态评估理念也可推广到其他机器学习模型的评估中。
📄 摘要(原文)
As Large Language Models (LLMs) are pre-trained on ultra-large-scale corpora, the problem of data contamination is becoming increasingly serious, and there is a risk that static evaluation benchmarks overestimate the performance of LLMs. To address this, this paper proposes a dynamic data evaluation method called AdEval (Alignment-based Dynamic Evaluation). AdEval first extracts knowledge points and main ideas from static datasets to achieve dynamic alignment with the core content of static benchmarks, and by avoiding direct reliance on static datasets, it inherently reduces the risk of data contamination from the source. It then obtains background information through online searches to generate detailed descriptions of the knowledge points. Finally, it designs questions based on Bloom's cognitive hierarchy across six dimensions-remembering, understanding, applying, analyzing, evaluating, and creating to enable multi-level cognitive assessment. Additionally, AdEval controls the complexity of dynamically generated datasets through iterative question reconstruction. Experimental results on multiple datasets show that AdEval effectively alleviates the impact of data contamination on evaluation results, solves the problems of insufficient complexity control and single-dimensional evaluation, and improves the fairness, reliability and diversity of LLMs evaluation.