Re-ranking Using Large Language Models for Mitigating Exposure to Harmful Content on Social Media Platforms
作者: Rajvardhan Oak, Muhammad Haroon, Claire Jo, Magdalena Wojcieszak, Anshuman Chhabra
分类: cs.CL, cs.AI, cs.CY, cs.SI
发布日期: 2025-01-23 (更新: 2025-05-29)
备注: Accepted to ACL 2025 Main Conference
💡 一句话要点
提出基于大语言模型的重排序方法,缓解社交媒体平台有害内容暴露问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内容审核 重排序 有害内容 社交媒体 零样本学习 少样本学习
📋 核心要点
- 社交媒体推荐算法为提升用户粘性可能导致接触有害内容,现有审核方法依赖大量标注数据,扩展性和适应性不足。
- 提出利用大语言模型进行内容重排序,无需大量标注数据即可动态评估和减少有害内容暴露。
- 实验表明,该方法在多个数据集和模型上优于现有审核方法,为有害内容缓解提供可扩展方案。
📝 摘要(中文)
社交媒体平台利用机器学习和人工智能驱动的推荐算法来最大化用户参与度,这可能导致用户无意中接触到有害内容。当前的审核工作依赖于使用大量人工标注数据训练的分类器,难以扩展和适应新的危害形式。为了解决这些挑战,我们提出了一种新颖的重排序方法,该方法在零样本和少样本设置中使用大型语言模型(LLM)。我们的方法动态评估和重排序内容序列,有效地减少有害内容的暴露,而无需大量的标记数据。除了传统的排序指标外,我们还引入了两个新指标来评估重排序在减少有害内容暴露方面的有效性。通过在三个数据集、三个模型和三种配置上进行的实验,我们证明了我们基于LLM的方法明显优于现有的专有审核方法,为减少危害提供了一种可扩展且适应性强的解决方案。
🔬 方法详解
问题定义:社交媒体平台为了提升用户参与度,通常使用推荐算法。然而,这些算法可能无意中将用户暴露于有害内容。现有的内容审核方法主要依赖于人工标注数据训练的分类器,这些方法在面对新的、不断变化的有害内容形式时,缺乏足够的扩展性和适应性,标注成本也很高。
核心思路:该论文的核心思路是利用大型语言模型(LLM)的强大语义理解和推理能力,直接对内容序列进行评估和重排序,从而减少用户接触有害内容的可能性。这种方法避免了对大量标注数据的依赖,并且能够更好地适应新的有害内容形式。
技术框架:该方法主要包含以下几个阶段:1) 获取待排序的内容序列;2) 使用LLM对内容序列进行评估,判断其潜在的危害程度;3) 基于LLM的评估结果,对内容序列进行重排序,将危害程度较高的内容排在后面,从而减少用户接触有害内容的概率。整个过程可以在零样本或少样本设置下进行,无需或仅需少量标注数据。
关键创新:该论文的关键创新在于将大型语言模型应用于社交媒体内容的重排序,以缓解有害内容暴露问题。与传统的基于分类器的审核方法相比,该方法具有更强的泛化能力和适应性,能够更好地应对新的有害内容形式。此外,该论文还提出了新的评估指标,用于衡量重排序方法在减少有害内容暴露方面的有效性。
关键设计:论文中使用了不同的LLM模型,例如未知模型A、B、C,并探索了零样本和少样本两种设置。在少样本设置中,使用了少量人工标注的有害内容示例来指导LLM的评估过程。具体的参数设置和损失函数信息未知,但可以推测使用了标准的语言模型训练方法,例如交叉熵损失函数。网络结构细节也未知,但可以推断使用了Transformer架构。
🖼️ 关键图片

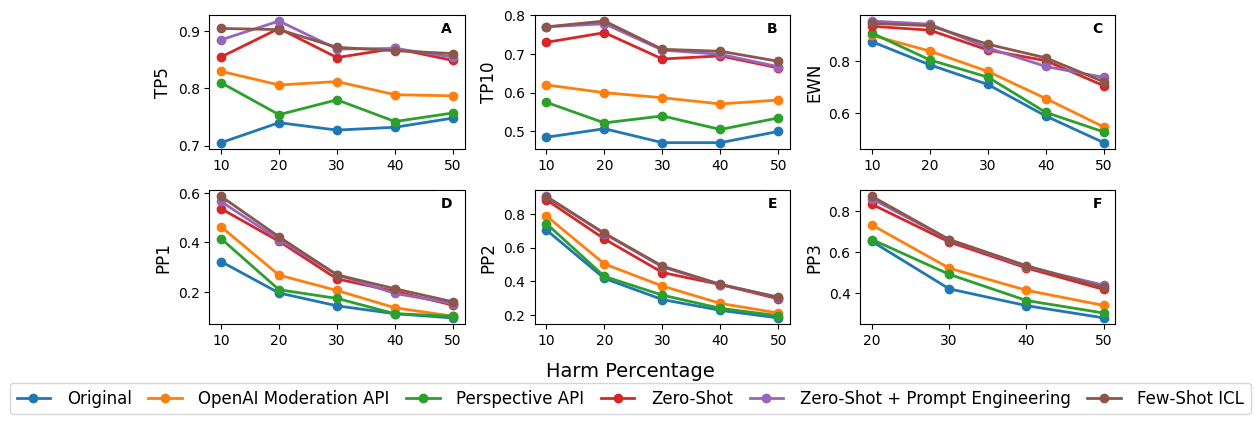
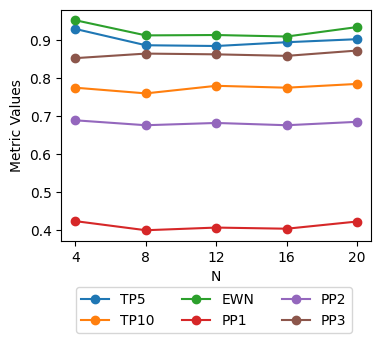
📊 实验亮点
实验结果表明,基于LLM的重排序方法在减少有害内容暴露方面显著优于现有的专有审核方法。具体性能数据未知,但论文强调了在三个数据集、三个模型和三种配置下,LLM方法均表现出优越性。该方法无需大量标注数据,具有很强的实际应用价值。
🎯 应用场景
该研究成果可应用于各种社交媒体平台,用于减少用户接触有害内容的风险,提升平台的内容质量和用户体验。此外,该方法还可以扩展到其他内容推荐场景,例如新闻推荐、视频推荐等,以减少虚假信息、煽动性内容等的传播。该研究为构建更安全、更健康的在线环境提供了新的思路。
📄 摘要(原文)
Social media platforms utilize Machine Learning (ML) and Artificial Intelligence (AI) powered recommendation algorithms to maximize user engagement, which can result in inadvertent exposure to harmful content. Current moderation efforts, reliant on classifiers trained with extensive human-annotated data, struggle with scalability and adapting to new forms of harm. To address these challenges, we propose a novel re-ranking approach using Large Language Models (LLMs) in zero-shot and few-shot settings. Our method dynamically assesses and re-ranks content sequences, effectively mitigating harmful content exposure without requiring extensive labeled data. Alongside traditional ranking metrics, we also introduce two new metrics to evaluate the effectiveness of re-ranking in reducing exposure to harmful content. Through experiments on three datasets, three models and across three configurations, we demonstrate that our LLM-based approach significantly outperforms existing proprietary moderation approaches, offering a scalable and adaptable solution for harm mitigation.