A RAG-Based Institutional Assistant
作者: Gustavo Kuratomi, Paulo Pirozelli, Fabio G. Cozman, Sarajane M. Peres
分类: cs.CL
发布日期: 2025-01-23
💡 一句话要点
构建基于RAG的机构助手,提升大型语言模型在知识密集型任务中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 知识密集型任务 虚拟助手 机构知识库
📋 核心要点
- 大型语言模型在知识密集型任务中面临挑战,无法有效利用结构化知识库和特定文档。
- 论文提出基于检索增强生成(RAG)的虚拟助手,通过检索相关文档片段来增强LLM的输入。
- 实验结果表明,RAG方法显著提升了LLM在特定任务中的准确率,但检索器的性能仍有提升空间。
📝 摘要(中文)
大型语言模型(LLMs)在文本生成方面表现出色,但在需要访问结构化知识库或特定文档的场景中表现不佳,限制了其在知识密集型任务中的有效性。为了解决这一局限性,研究人员开发了检索增强生成(RAG)模型,使生成模型能够将相关的文档片段纳入其输入。本文设计并评估了一个专门为圣保罗大学定制的基于RAG的虚拟助手。我们的系统架构包括两个关键模块:检索器和生成模型。我们对这两个组件的不同类型的模型进行了实验,调整了诸如chunk大小和检索文档数量等超参数。我们最佳的检索器模型实现了30%的Top-5准确率,而我们最有效的生成模型针对ground truth答案的得分为22.04%。值得注意的是,当向LLM提供正确的文档chunks时,准确率显著提高到54.02%,提高了30多个百分点。相反,如果没有上下文输入,性能会下降到13.68%。这些发现突出了数据库访问在提高LLM性能方面的关键作用。它们还揭示了当前语义搜索方法在准确识别相关文档方面的局限性,并强调了LLM在生成精确响应方面面临的持续挑战。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在知识密集型任务中,由于缺乏对结构化知识库或特定文档的有效访问而导致的性能瓶颈。现有方法难以将外部知识融入LLM的生成过程中,导致回答不准确或不完整。
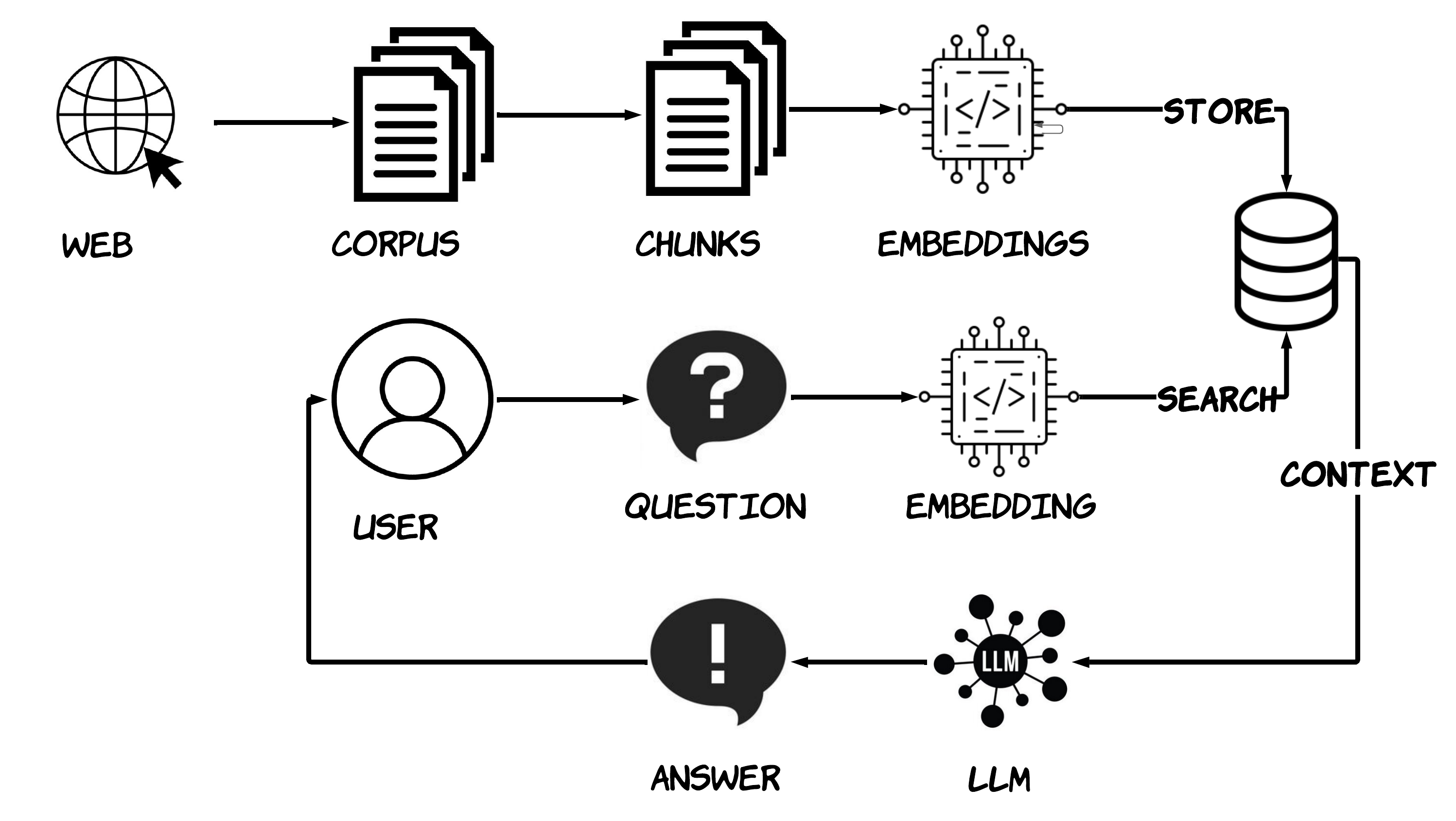
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,将检索器和生成模型结合起来。检索器负责从知识库中检索相关文档片段,然后将这些片段作为上下文提供给生成模型,从而增强LLM的知识储备和生成能力。
技术框架:该RAG系统的整体架构包含两个主要模块:检索器和生成模型。首先,检索器接收用户查询,并从大学的知识库中检索最相关的文档chunks。然后,将检索到的文档chunks与用户查询一起输入到生成模型中,生成模型根据这些信息生成最终的答案。论文实验了不同类型的模型作为检索器和生成器,并调整了chunk大小和检索文档数量等超参数。
关键创新:该研究的关键创新在于针对特定机构(圣保罗大学)定制RAG系统,并深入分析了检索器和生成模型在RAG框架中的作用。通过实验,论文量化了检索器性能对最终生成结果的影响,并揭示了当前语义搜索方法在准确识别相关文档方面的局限性。
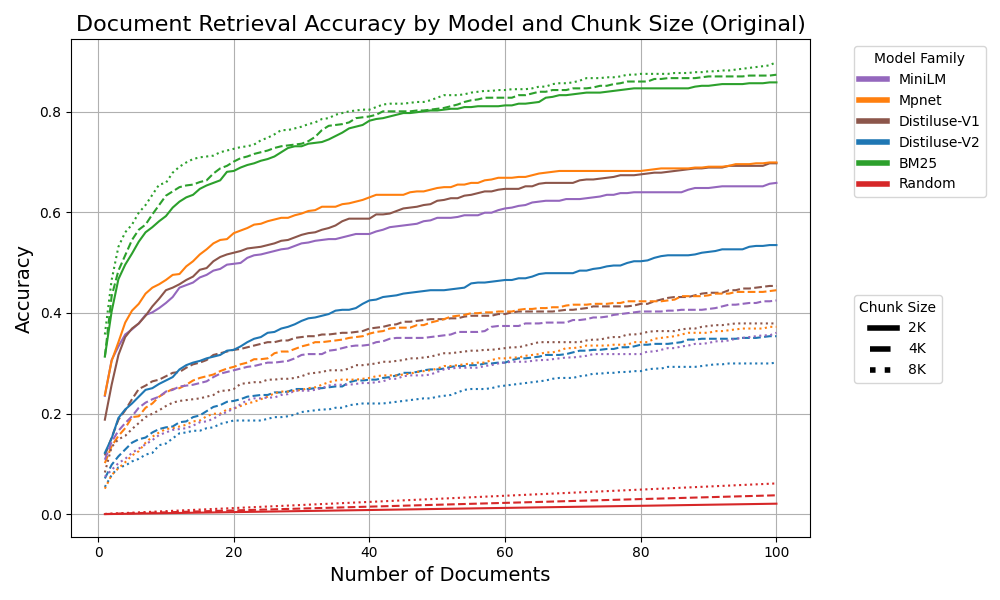
关键设计:论文实验了不同的检索器模型和生成模型,并调整了chunk size和检索文档数量等超参数。具体模型选择和参数设置在论文中未详细说明,属于实验细节,未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,最佳检索器模型的Top-5准确率为30%,最有效的生成模型针对ground truth答案的得分为22.04%。当提供正确的文档chunks时,LLM的准确率显著提高到54.02%,提升超过30个百分点。而没有上下文输入时,性能下降到13.68%。这些数据清晰地展示了RAG方法对LLM性能的积极影响。
🎯 应用场景
该研究成果可应用于构建各种机构或企业的智能助手,例如大学的问答系统、公司的知识库检索工具等。通过RAG方法,可以有效提升LLM在特定领域的知识应用能力,为用户提供更准确、更全面的信息服务。未来,该技术有望在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
Although large language models (LLMs) demonstrate strong text generation capabilities, they struggle in scenarios requiring access to structured knowledge bases or specific documents, limiting their effectiveness in knowledge-intensive tasks. To address this limitation, retrieval-augmented generation (RAG) models have been developed, enabling generative models to incorporate relevant document fragments into their inputs. In this paper, we design and evaluate a RAG-based virtual assistant specifically tailored for the University of São Paulo. Our system architecture comprises two key modules: a retriever and a generative model. We experiment with different types of models for both components, adjusting hyperparameters such as chunk size and the number of retrieved documents. Our optimal retriever model achieves a Top-5 accuracy of 30%, while our most effective generative model scores 22.04\% against ground truth answers. Notably, when the correct document chunks are supplied to the LLMs, accuracy significantly improves to 54.02%, an increase of over 30 percentage points. Conversely, without contextual input, performance declines to 13.68%. These findings highlight the critical role of database access in enhancing LLM performance. They also reveal the limitations of current semantic search methods in accurately identifying relevant documents and underscore the ongoing challenges LLMs face in generating precise responses.