Pseudocode-Injection Magic: Enabling LLMs to Tackle Graph Computational Tasks
作者: Chang Gong, Wanrui Bian, Zhijie Zhang, Weiguo Zheng
分类: cs.CL, cs.AI
发布日期: 2025-01-23
备注: 24 pages
💡 一句话要点
PIE:通过伪代码注入增强LLM在图计算任务中的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图计算 大型语言模型 伪代码注入 提示工程 代码生成
📋 核心要点
- 现有方法在利用LLM解决图计算任务时,面临理解复杂图结构能力不足和推理成本过高的挑战。
- PIE框架通过问题理解、提示设计和代码生成三个步骤,并注入伪代码来辅助LLM生成高效代码。
- 实验结果表明,PIE在准确性和计算效率方面均优于现有基线方法,展现了其优越性。
📝 摘要(中文)
图计算任务本身具有挑战性,通常需要开发高级算法才能有效解决。随着大型语言模型(LLM)的出现,研究人员已经开始研究它们解决这些任务的潜力。然而,现有方法受到LLM理解复杂图结构的能力有限以及高推理成本的限制,使得它们在处理大规模图时并不实用。受到人类解决图问题方法的启发,我们引入了一个新颖的框架PIE(用于图计算任务的伪代码注入增强LLM推理),它由三个关键步骤组成:问题理解、提示设计和代码生成。在这个框架中,LLM的任务是理解问题并提取相关信息以生成正确的代码。分析图结构和执行代码的责任被委托给解释器。我们将任务相关的伪代码注入到提示中,以进一步帮助LLM生成高效的代码。我们还采用经济高效的试错技术来确保LLM生成的代码正确执行。与其他需要为每个单独的测试用例调用LLM的方法不同,PIE仅在代码生成阶段调用LLM,从而允许重用生成的代码并显着降低推理成本。大量的实验表明,PIE在准确性和计算效率方面均优于现有基线。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在图计算任务中表现不佳的问题。现有方法主要痛点在于LLM难以理解复杂的图结构,且推理成本高昂,导致无法有效处理大规模图数据。
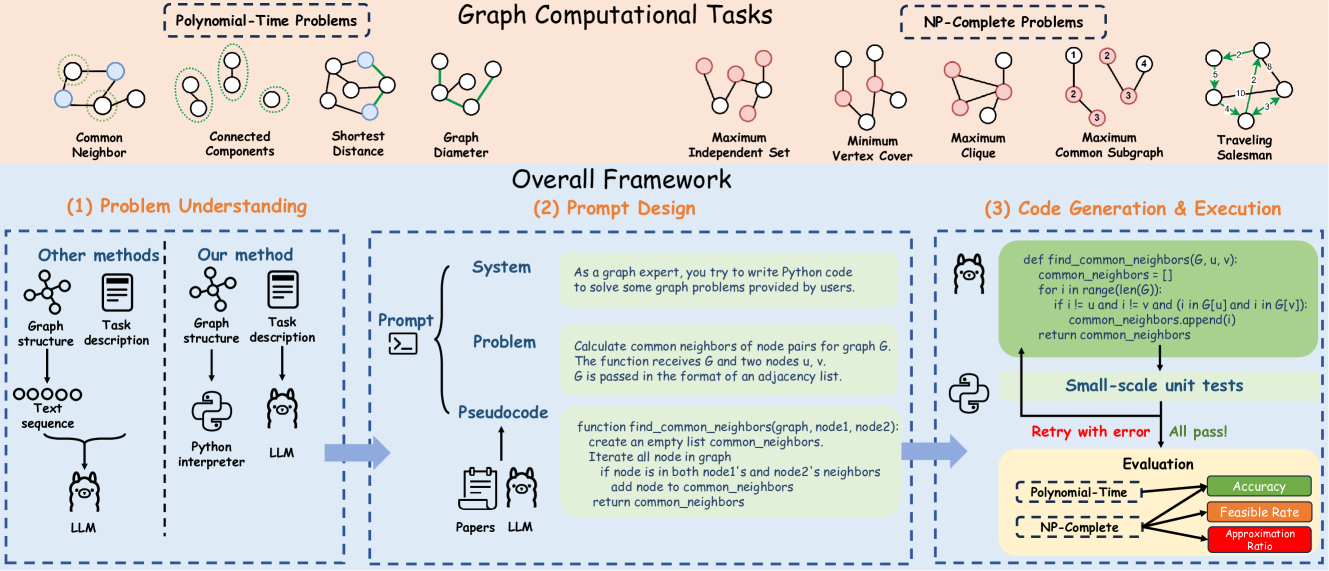
核心思路:论文的核心思路是借鉴人类解决图问题的方式,将问题分解为问题理解、提示设计和代码生成三个步骤。通过注入任务相关的伪代码到提示中,引导LLM生成更高效、更准确的代码,并将图结构分析和代码执行的任务交给解释器,从而降低LLM的推理负担。
技术框架:PIE框架包含三个主要阶段:1) 问题理解:LLM理解图计算任务的描述和要求;2) 提示设计:设计包含伪代码的提示,引导LLM生成代码;3) 代码生成:LLM基于提示生成可执行的代码,并使用解释器执行。框架还包含一个试错机制,用于验证和修正生成的代码。
关键创新:PIE的关键创新在于伪代码注入。通过在提示中加入伪代码,可以显著提升LLM生成正确代码的能力,尤其是在处理复杂的图计算任务时。此外,PIE仅在代码生成阶段调用LLM,生成的代码可以重复使用,从而大幅降低了推理成本。
关键设计:伪代码的设计需要根据具体的图计算任务进行调整,以提供LLM必要的算法指导。试错机制采用经济高效的方式,例如使用小规模图进行测试,快速发现和修正代码中的错误。提示工程的设计也至关重要,需要清晰地描述问题、提供必要的上下文信息,并引导LLM生成符合要求的代码。
🖼️ 关键图片
📊 实验亮点
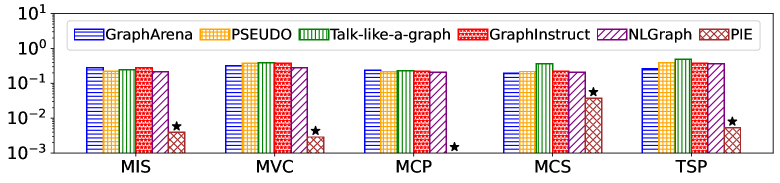
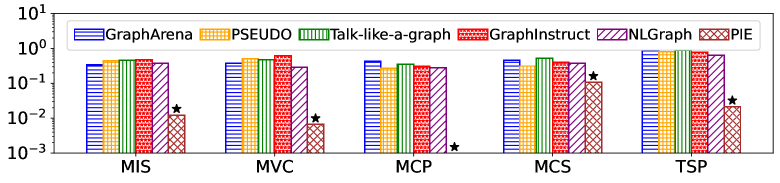
实验结果表明,PIE框架在图计算任务的准确性和计算效率方面均优于现有基线方法。具体而言,PIE能够以更低的推理成本达到与现有方法相当甚至更高的准确率,尤其是在处理大规模图数据时,优势更加明显。这证明了伪代码注入策略的有效性和PIE框架的实用性。
🎯 应用场景
该研究成果可应用于各种需要图计算的领域,例如社交网络分析、推荐系统、生物信息学、交通网络优化等。通过降低LLM在图计算任务中的推理成本,PIE框架有望推动LLM在更大规模、更复杂的图数据上的应用,并为相关领域带来实际价值和创新。
📄 摘要(原文)
Graph computational tasks are inherently challenging and often demand the development of advanced algorithms for effective solutions. With the emergence of large language models (LLMs), researchers have begun investigating their potential to address these tasks. However, existing approaches are constrained by LLMs' limited capability to comprehend complex graph structures and their high inference costs, rendering them impractical for handling large-scale graphs. Inspired by human approaches to graph problems, we introduce a novel framework, PIE (Pseudocode-Injection-Enhanced LLM Reasoning for Graph Computational Tasks), which consists of three key steps: problem understanding, prompt design, and code generation. In this framework, LLMs are tasked with understanding the problem and extracting relevant information to generate correct code. The responsibility for analyzing the graph structure and executing the code is delegated to the interpreter. We inject task-related pseudocodes into the prompts to further assist the LLMs in generating efficient code. We also employ cost-effective trial-and-error techniques to ensure that the LLM-generated code executes correctly. Unlike other methods that require invoking LLMs for each individual test case, PIE only calls the LLM during the code generation phase, allowing the generated code to be reused and significantly reducing inference costs. Extensive experiments demonstrate that PIE outperforms existing baselines in terms of both accuracy and computational efficiency.