RPO: Retrieval Preference Optimization for Robust Retrieval-Augmented Generation
作者: Shi-Qi Yan, Quan Liu, Zhen-Hua Ling
分类: cs.CL
发布日期: 2025-01-23 (更新: 2025-10-10)
💡 一句话要点
提出检索偏好优化(RPO)方法,提升检索增强生成模型在知识冲突下的鲁棒性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 知识冲突 偏好优化 奖励模型 大型语言模型
📋 核心要点
- RAG模型易受检索质量影响,当检索知识与模型记忆冲突时,生成效果下降。
- RPO方法通过检索偏好优化,使模型能够自适应地利用多源知识,缓解知识冲突。
- 实验结果表明,RPO在多个数据集上显著提升了RAG模型的准确率,无需额外组件。
📝 摘要(中文)
检索增强生成(RAG)在利用外部知识方面展现了潜力,但其生成过程严重依赖于检索上下文的质量和准确性。当外部检索的非参数知识与LLM内部记忆存在差异时,大型语言模型(LLM)难以评估其正确性,导致响应生成过程中的知识冲突。为此,我们提出了检索偏好优化(RPO),这是一种轻量级且有效的对齐方法,能够基于检索相关性自适应地利用多源知识。RPO推导了检索相关性的隐式表示,并将其融入奖励模型中,从而将检索评估和响应生成集成到一个模型中,解决了以往方法需要额外步骤评估检索质量的问题。值得注意的是,RPO是唯一一种专门针对RAG的对齐方法,它量化了训练中对检索相关性的感知,克服了数学障碍。在四个数据集上的实验表明,RPO在没有任何额外组件的情况下,准确率比RAG提高了4-10%,展示了其强大的泛化能力。
🔬 方法详解
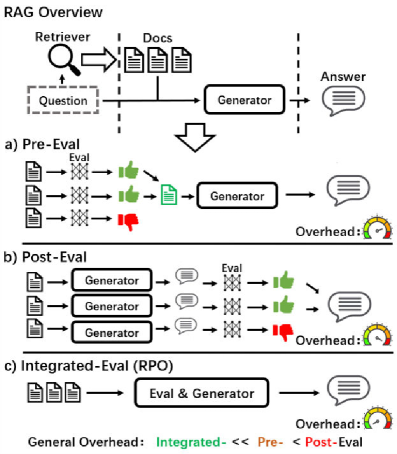
问题定义:现有RAG模型在面对检索到的知识与自身记忆冲突时,难以判断哪个知识源更可靠,导致生成错误或不一致的答案。以往方法通常需要额外的步骤来评估检索质量,增加了计算负担和复杂性。
核心思路:RPO的核心思想是让模型学习检索相关性的偏好,即模型需要知道哪些检索结果更可靠,并以此为依据生成答案。通过将检索相关性融入奖励模型,RPO能够引导模型选择更相关的知识,从而减少知识冲突。
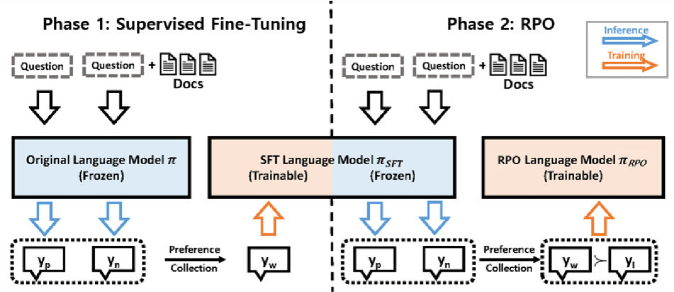
技术框架:RPO方法主要包含以下几个步骤:1) 使用检索器检索相关文档;2) 构建奖励模型,该模型将检索相关性作为输入;3) 使用偏好优化算法训练模型,使其能够根据检索相关性选择更合适的知识;4) 使用训练好的模型生成最终答案。整个框架将检索评估和响应生成整合到一个模型中。
关键创新:RPO的关键创新在于它将检索相关性显式地融入到训练过程中,使得模型能够直接学习如何根据检索结果的质量来生成答案。这是第一个专门针对RAG的对齐方法,它量化了训练中对检索相关性的感知,克服了数学障碍。
关键设计:RPO使用隐式表示来捕捉检索相关性,并将其作为奖励模型的输入。奖励模型的设计至关重要,它需要能够准确地评估检索结果的质量,并将其转化为对生成过程的指导。具体的损失函数和网络结构的选择取决于具体的应用场景和数据集。
🖼️ 关键图片
📊 实验亮点
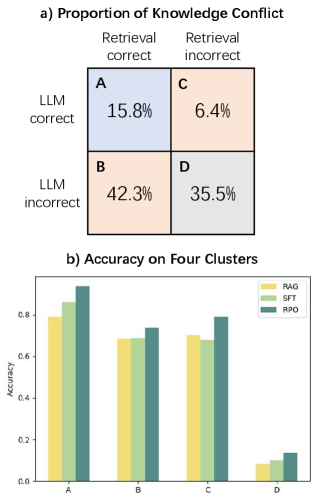
实验结果表明,RPO在四个数据集上均取得了显著的性能提升,准确率比基线RAG模型提高了4-10%,且无需任何额外的组件。这表明RPO是一种轻量级且有效的RAG对齐方法,具有良好的泛化能力和实用价值。
🎯 应用场景
RPO方法可应用于各种需要利用外部知识的自然语言生成任务,例如问答系统、对话系统、文本摘要等。通过提升RAG模型在知识冲突下的鲁棒性,RPO可以提高这些应用在复杂场景下的性能和可靠性,尤其是在需要处理大量噪声或不确定知识的场景下。
📄 摘要(原文)
While Retrieval-Augmented Generation (RAG) has exhibited promise in utilizing external knowledge, its generation process heavily depends on the quality and accuracy of the retrieved context. Large language models (LLMs) struggle to evaluate the correctness of non-parametric knowledge retrieved externally when it differs from internal memorization, leading to knowledge conflicts during response generation. To this end, we introduce the Retrieval Preference Optimization (RPO), a lightweight and effective alignment method to adaptively leverage multi-source knowledge based on retrieval relevance. An implicit representation of retrieval relevance is derived and incorporated into the reward model to integrate retrieval evaluation and response generation into a single model, solving the problem that previous methods necessitate the additional procedure to assess the retrieval quality. Notably, RPO is the only RAG-dedicated alignment approach that quantifies the awareness of retrieval relevance in training, overcoming mathematical obstacles. Experiments on four datasets demonstrate that RPO outperforms RAG by 4-10% in accuracy without any extra component, exhibiting its robust generalization.