Musical ethnocentrism in Large Language Models
作者: Anna Kruspe
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2025-01-23 (更新: 2025-02-03)
期刊: Proceedings of the 3rd Workshop on NLP for Music and Audio (NLP4MusA) 2024
💡 一句话要点
揭示大型语言模型中的音乐民族中心主义偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 音乐偏见 民族中心主义 地缘文化偏见 ChatGPT Mixtral
📋 核心要点
- 大型语言模型训练数据中的地缘文化偏见,特别是音乐领域的偏见,缺乏深入研究。
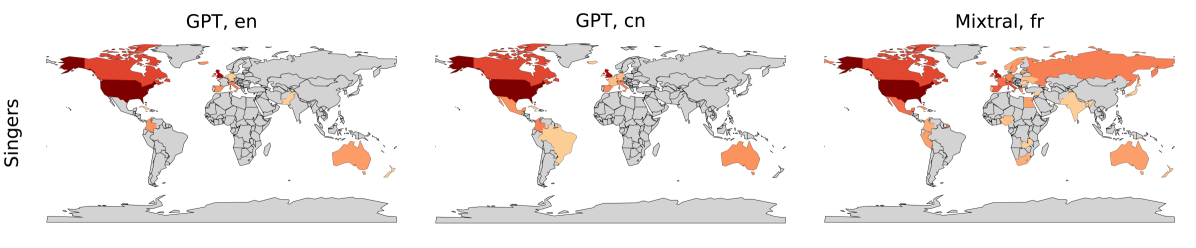
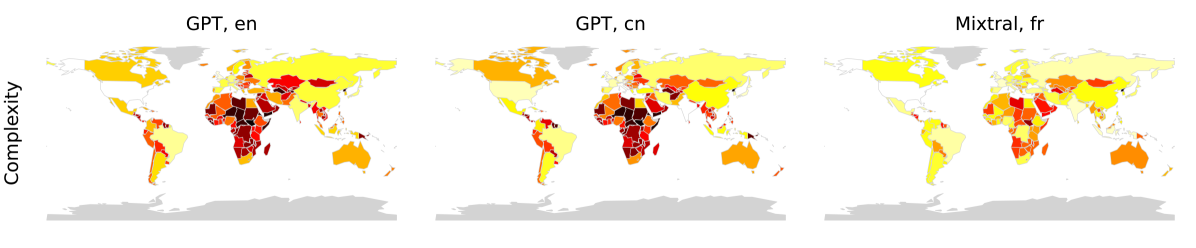
- 通过提示LLM生成音乐贡献者名单并进行国家来源分析,以及对不同国家音乐文化进行数值评级,来揭示其偏见。
- 实验结果表明,ChatGPT和Mixtral等LLM在音乐领域存在对西方音乐文化的显著偏好。
📝 摘要(中文)
大型语言模型(LLMs)反映了其训练数据中的偏见,以及创建这些训练数据的人的偏见。检测、分析和缓解这些偏见正成为研究的重点。地缘文化偏见是目前研究不足的一种偏见。这些偏见可能由训练数据中不同地理区域和文化代表性的不平衡,以及其中包含的价值判断所引起。在本文中,我们首次尝试分析LLMs(特别是ChatGPT和Mixtral)中的音乐偏见。我们进行了两个实验。在第一个实验中,我们提示LLMs提供各种类别“Top 100”音乐贡献者的名单,并分析他们的原籍国。在第二个实验中,我们要求LLMs对不同国家音乐文化的各个方面进行数值评级。我们的结果表明,在两个实验中,LLMs都强烈偏爱西方音乐文化。
🔬 方法详解
问题定义:论文旨在揭示大型语言模型(LLMs)在音乐领域中存在的民族中心主义偏见,即对特定文化(尤其是西方文化)的过度偏好。现有方法缺乏对LLM中地缘文化偏见的系统性分析,尤其是在音乐领域,这可能导致模型在音乐推荐、生成和理解等任务中产生不公平或不准确的结果。
核心思路:论文的核心思路是通过设计特定的实验来探究LLM在音乐领域的偏见。具体来说,通过提示LLM生成不同类别(如作曲家、演奏家等)的“Top 100”音乐贡献者名单,并分析这些贡献者的国籍分布,从而揭示模型对不同国家或地区的音乐家的偏好。此外,还通过要求LLM对不同国家音乐文化的各个方面进行数值评级,来进一步量化模型对不同音乐文化的偏见程度。
技术框架:论文采用了实验驱动的方法,主要包含两个阶段: 1. 生成“Top 100”音乐贡献者名单:针对不同音乐类别(如古典音乐、流行音乐等),提示LLM生成该类别下“Top 100”音乐贡献者的名单。 2. 音乐文化评级:要求LLM对不同国家或地区的音乐文化进行数值评级,评估其在不同方面的表现(如创新性、影响力等)。
关键创新:该研究的主要创新在于首次系统性地分析了LLM在音乐领域中的民族中心主义偏见。通过设计具体的实验,量化了LLM对西方音乐文化的偏好程度,并揭示了这种偏见可能对音乐相关应用产生的影响。
关键设计: * 提示工程:精心设计提示语,以确保LLM能够理解任务要求并生成有意义的结果。 * 国家/地区分类:对生成的音乐贡献者名单进行国家/地区分类,以便分析其地理分布。 * 数值评级标准:制定明确的数值评级标准,以便LLM能够对不同国家/地区的音乐文化进行客观评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ChatGPT和Mixtral等LLM在生成“Top 100”音乐贡献者名单时,显著偏好西方国家的音乐家。在音乐文化评级实验中,LLM也对西方音乐文化给出了更高的评分。这些结果量化了LLM在音乐领域存在的民族中心主义偏见,为后续的偏见缓解研究提供了依据。
🎯 应用场景
该研究成果可应用于改进音乐推荐系统,使其更加公平和多样化,避免过度推荐西方音乐。同时,可以指导LLM的训练数据选择和模型优化,减少地缘文化偏见,提升模型在跨文化音乐理解和生成方面的能力。此外,该研究也为其他领域的偏见分析提供了借鉴。
📄 摘要(原文)
Large Language Models (LLMs) reflect the biases in their training data and, by extension, those of the people who created this training data. Detecting, analyzing, and mitigating such biases is becoming a focus of research. One type of bias that has been understudied so far are geocultural biases. Those can be caused by an imbalance in the representation of different geographic regions and cultures in the training data, but also by value judgments contained therein. In this paper, we make a first step towards analyzing musical biases in LLMs, particularly ChatGPT and Mixtral. We conduct two experiments. In the first, we prompt LLMs to provide lists of the "Top 100" musical contributors of various categories and analyze their countries of origin. In the second experiment, we ask the LLMs to numerically rate various aspects of the musical cultures of different countries. Our results indicate a strong preference of the LLMs for Western music cultures in both experiments.